Clear Sky Science · fr
Génération d'images artistiques colorées guidée visuellement par IA via un GAN amélioré
Pourquoi des machines artistiques plus intelligentes comptent
Les outils numériques peuvent désormais peindre des portraits, paysages et scènes abstraites en quelques secondes, mais nombre de ces œuvres d'IA semblent encore légèrement décalées — les couleurs jurent, les textures paraissent plates ou le « style » ne correspond pas tout à fait à ce que l'on imagine. Cet article présente une nouvelle façon d'apprendre aux ordinateurs à créer des œuvres colorées plus riches, plus cohérentes et plus proches des peintures réelles, tout en permettant aux utilisateurs d'orienter le résultat par de simples indices visuels tels que croquis et choix de couleurs. L'objectif est de faire de l'IA un partenaire créatif plus fiable pour les artistes, designers et utilisateurs ordinaires qui veulent de l'art personnalisé sans années de formation.
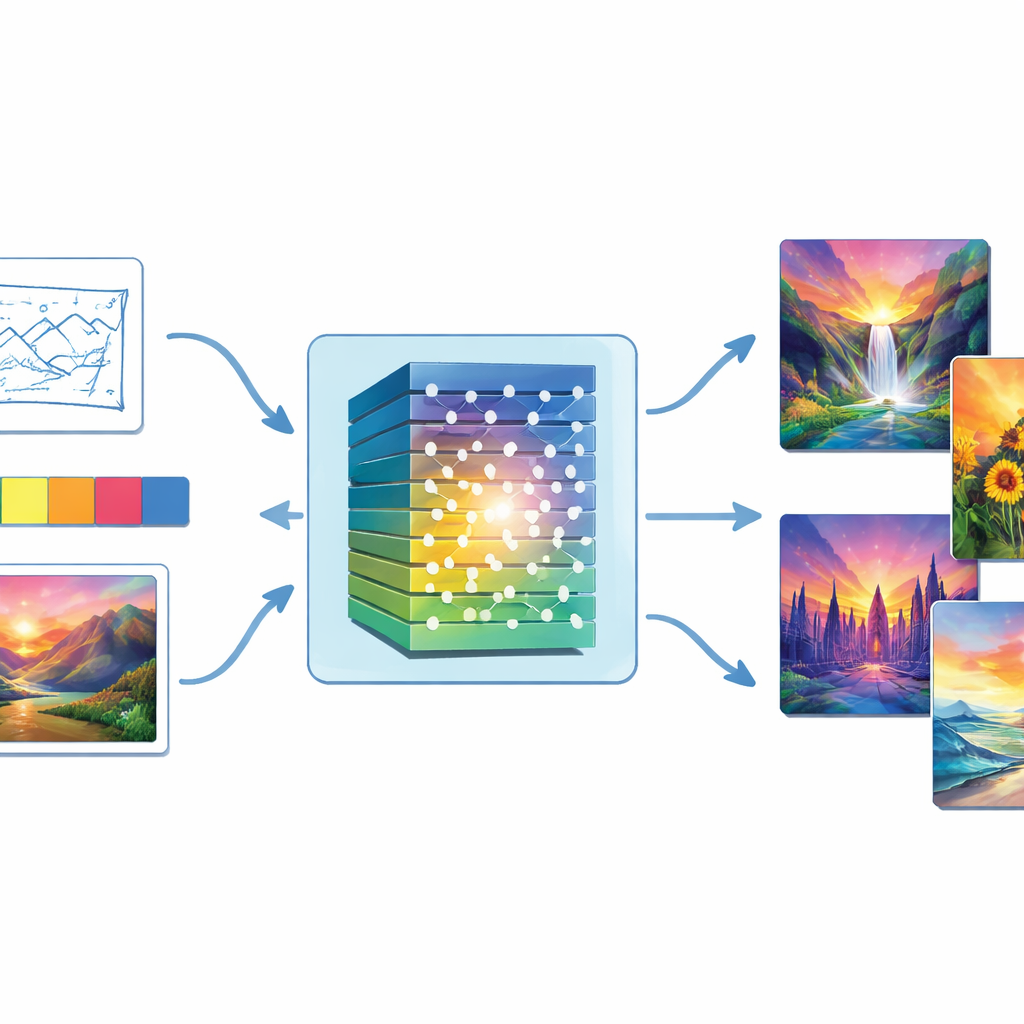
Du bruit aléatoire aux peintures achevées
Au cœur de l'étude se trouve un type d'IA appelé réseau antagoniste génératif, ou GAN. Un GAN est composé de deux parties opposées : un « générateur » qui tente de produire des images convaincantes à partir de bruit aléatoire, et un « discriminateur » qui juge si une image semble réelle ou fausse. Au fil de nombreuses itérations d'entraînement, le générateur s'améliore pour tromper le discriminateur, et les images deviennent progressivement plus réalistes. Les auteurs renforcent cette idée centrale en insérant une chaîne de traitement d'image profonde — appelée réseau de neurones convolutionnel — à la fois dans le générateur et le discriminateur, afin que le système capture mieux tout, des formes générales aux détails fins rappelant des traits de pinceau.
Apprendre au système où regarder
Si les GAN standards peuvent produire des images nettes, ils ratent souvent la vue d'ensemble : ils peuvent suraccentuer de petits détails au détriment de la structure globale, ou ne pas maintenir un style artistique cohérent. Pour y remédier, l'équipe ajoute un mécanisme d'attention adaptatif. Ce module analyse les cartes de caractéristiques internes du générateur et apprend, durant l'entraînement, quelles régions d'une image importent le plus à chaque instant. Il renforce ensuite ces zones clés — telles que les contours, textures et objets focaux — tout en adoucissant les zones d'arrière-plan moins importantes. Des mesures de perte spécifiques suivent dans quelle mesure l'image générée correspond au style et à la texture d'une œuvre cible, poussant le modèle à équilibrer contenu reconnaissable et apparence artistique cohérente.
Guider la machine avec des indices visuels
Contrairement aux systèmes uniquement textuels, cette approche permet aux utilisateurs d'orienter l'œuvre par un guidage visuel direct. Les utilisateurs peuvent fournir un croquis pour définir la composition, une palette de couleurs pour fixer l'ambiance, une image de style de référence à imiter ou de simples étiquettes de scène. Ces entrées pénètrent le générateur aux côtés du bruit aléatoire. Le modèle calcule alors des propriétés colorimétriques comme la teinte, la saturation et la luminosité, et ajuste sa sortie pour que la peinture finale respecte à la fois les intentions colorées de l'utilisateur et le style de référence. Un objectif de correspondance des couleurs renforce encore le lien entre ce que l'utilisateur indique et ce que le système produit, de sorte qu'un paysage marin bleu froid ne devienne pas, par exemple, un coucher de soleil chaud de manière inattendue.
Apprendre à s'améliorer par essai-erreur
Le système va plus loin en utilisant l'apprentissage par renforcement profond, une technique inspirée de l'apprentissage par essai et erreur. Ici, un module de décision séparé considère l'écart entre la sortie actuelle et la guidance cible comme son « état », et propose de petits ajustements d'éléments tels que la force du croquis ou les poids de la palette comme ses « actions ». Après chaque changement, le système mesure combien les scores de qualité d'image importants s'améliorent — tels que le rapport signal/bruit de pointe, la similarité structurelle et la perte de style — et utilise cela comme signal de récompense. Avec le temps, cette boucle apprend une politique qui affine automatiquement la guidance pour pousser le générateur vers des images à la fois fidèles visuellement et cohérentes artistiquement.
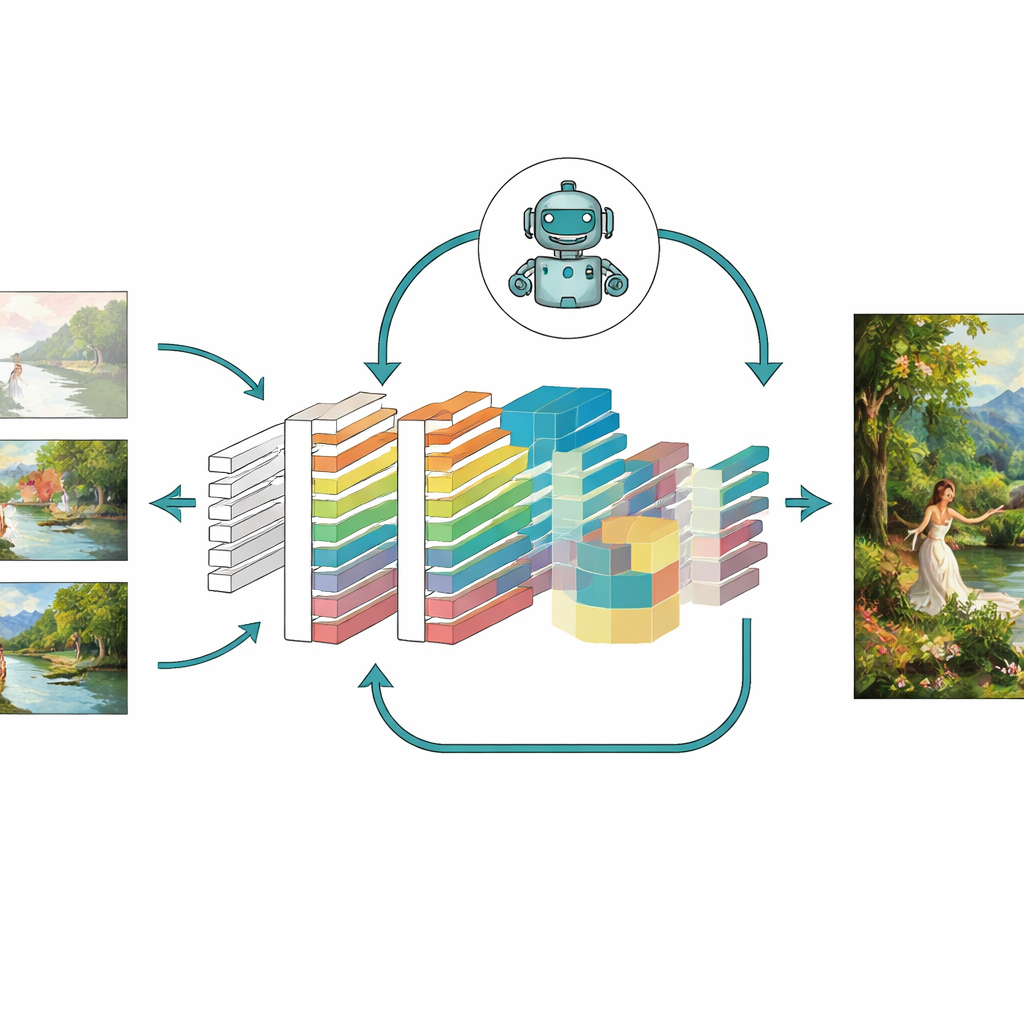
Mettre le modèle à l'épreuve
Pour évaluer si ces idées apportent réellement une amélioration, les auteurs ont testé leur modèle enrichi — appelé CNN-GAN — sur une grande collection de peintures de l'Université d'Oxford et sur un ensemble personnalisé de plus de 5 000 œuvres colorées couvrant des styles comme portraits, paysages et scènes abstraites. Ils ont comparé les résultats avec plusieurs systèmes connus, y compris des variantes classiques de GAN, des autoencodeurs et même des générateurs modernes basés sur la diffusion. Selon de nombreuses mesures, le nouveau modèle produisait des images plus nettes avec moins d'artéfacts, une correspondance structurelle plus proche des œuvres réelles, une distance perceptuelle plus faible par rapport aux images cibles et une plus grande diversité dans les types de scènes générées. Des études d'ablation, retirant un module à la fois, ont montré que l'attention, l'apprentissage par renforcement et la conception combinée des pertes contribuaient chacun à des améliorations significatives, et qu'ensembles ils offraient la meilleure performance.
Ce que cela implique pour les futurs outils créatifs
En termes concrets, l'article décrit une machine à peindre qui non seulement apprend à partir de milliers d'œuvres, mais prête aussi une attention particulière aux régions importantes, écoute les indices visuels des utilisateurs et s'enseigne progressivement comment ajuster ces indices pour de meilleurs résultats. Le résultat est une IA capable de générer des images de haute qualité et stylistiquement unifiées plus régulièrement que les méthodes antérieures, tout en laissant de la place à la direction humaine. Bien que le système ait encore du mal avec des textures extrêmement complexes et dépende de volumes conséquents de données d'entraînement, les auteurs suggèrent des extensions futures — telles que des modules multi-échelles et des réseaux plus légers — pour le rendre plus efficace et largement utilisable. Ensemble, ces avancées ouvrent la voie à des outils d'art assisté par IA plus rapides, plus fidèles à l'intention de l'utilisateur et meilleurs pour capturer le caractère subtil des peintures humaines.
Citation: Wu, Z. Visual guided AI color art image generation using enhanced GAN. Sci Rep 16, 9345 (2026). https://doi.org/10.1038/s41598-026-35625-z
Mots-clés: génération d'art par IA, transfert de style d'image, réseaux antagonistes génératifs, créativité artificielle, synthèse d'images neuronale