Chaque fois que des gouvernements, des scientifiques ou des sondeurs tentent d'apprendre quelque chose sur une population entière — par exemple le revenu moyen, le rendement des cultures ou les niveaux de pollution — ils peuvent rarement mesurer tout le monde. Ils tirent plutôt un échantillon et extrapolent. Cela ne fonctionne bien que si les données se comportent correctement. Dans la réalité, toutefois, les enquêtes et les mesures sont truffées d'erreurs et de valeurs extrêmes qui peuvent fausser fortement les résultats. Cet article présente une nouvelle façon de calculer les moyennes de population qui reste fiable même lorsque les données sont encombrées, rendant les décisions fondées sur les enquêtes plus dignes de confiance.
Quand les moyennes simples échouent
Les outils standard pour estimer une moyenne de population, comme la moyenne d'échantillon simple ou la régression ordinaire, supposent que la plupart des observations suivent des motifs réguliers, sans valeurs aberrantes extrêmes ni cas inhabituels. Dans les enquêtes sociales et économiques, la surveillance environnementale et les statistiques agricoles, cet espoir est souvent déçu. Quelques relevés erronés, des événements rares mais extrêmes, ou des réponses mal déclarées peuvent tirer les estimations loin de la vérité, augmentant à la fois le biais et l'incertitude. Des travaux antérieurs ont tenté d'atténuer l'impact de telles valeurs aberrantes en utilisant des méthodes dites robustes, incluant une approche populaire connue sous le nom d'estimation M de Huber. Bien que utiles, ces méthodes protègent principalement contre les valeurs extrêmes de la variable d'intérêt et restent vulnérables aux motifs inhabituels dans les informations explicatives associées.
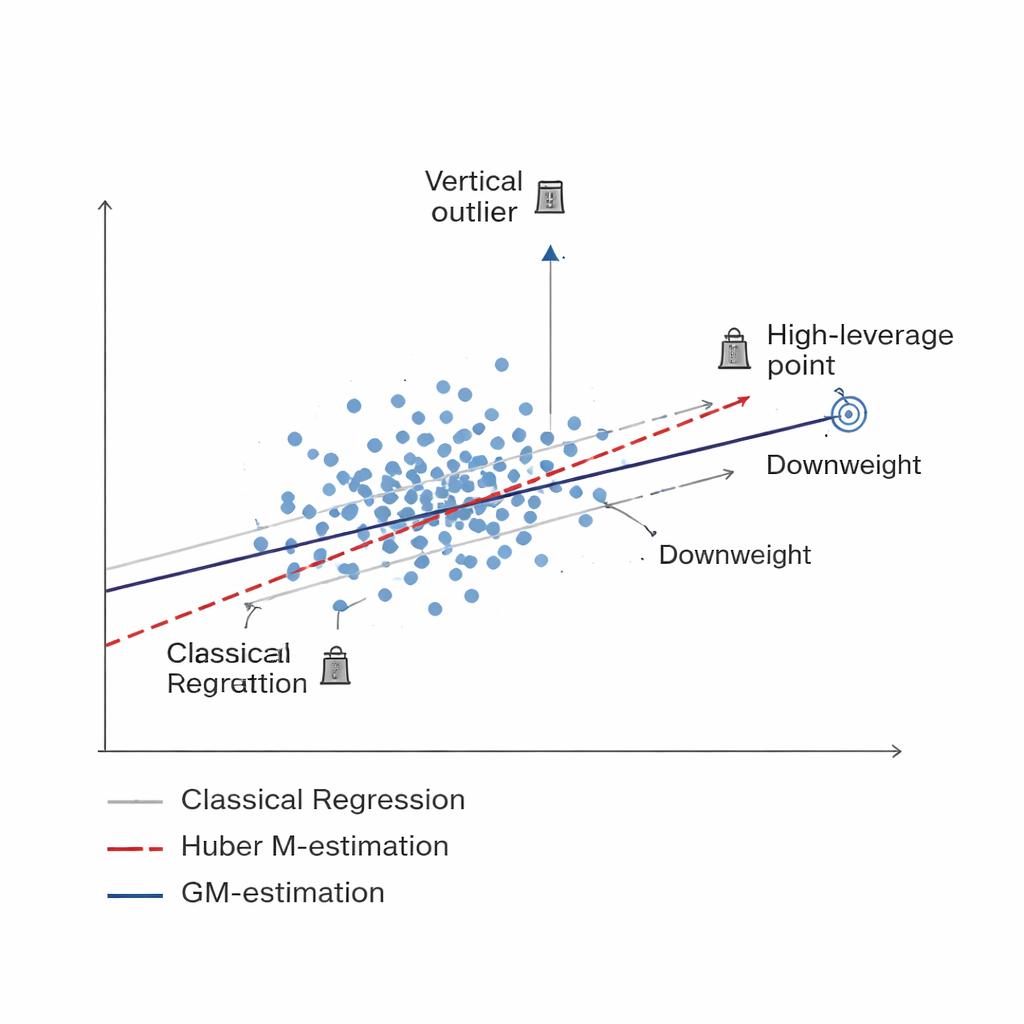
Une façon plus intelligente de réduire le poids des mauvaises données Figure 1.
L'étude développe une nouvelle famille d'estimateurs fondée sur l'estimation M généralisée, ou estimation GM. Au lieu de traiter chaque unité échantillonnée de façon égale, les méthodes GM attribuent des poids adaptatifs qui dépendent de deux éléments à la fois : à quel point la réponse d'une unité est extrême (une valeur aberrante verticale) et à quel point ses informations associées sont inhabituelles (un point à levier élevé). Trois versions spécifiques — appelées Mallows-GM, Schweppes-GM et SIS-GM — sont conçues pour des scénarios d'enquête courants, incluant l'échantillonnage aléatoire simple sans remplacement et des plans stratifiés plus complexes où la population est divisée en groupes relativement homogènes. En contrôlant conjointement ces deux types d'observations problématiques, ces estimateurs visent à maintenir la stabilité de l'estimation finale de la moyenne de la population même lorsque les données contiennent des contaminations importantes.
Mettre les nouveaux estimateurs à l'épreuve
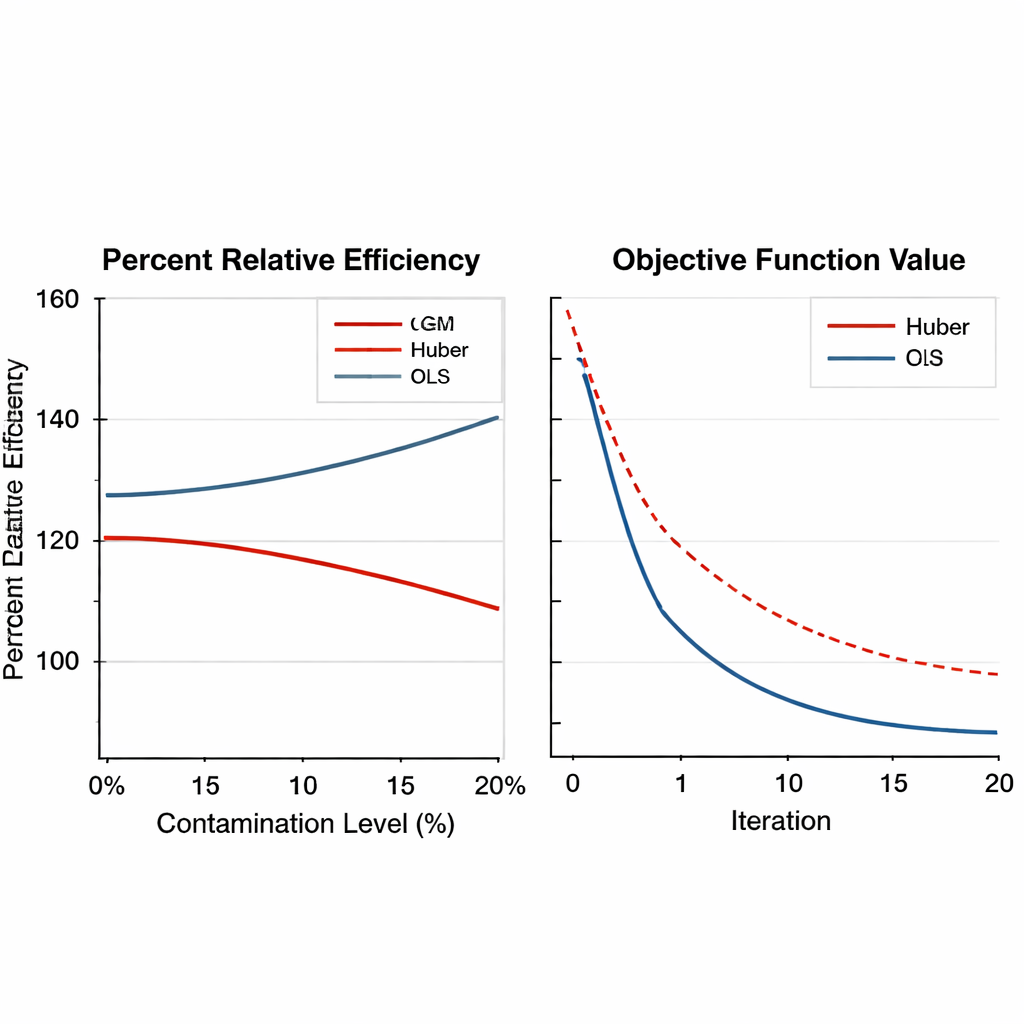
Pour évaluer l'efficacité des estimateurs basés sur GM, l'auteur réalise de vastes expériences numériques. D'abord, des données réelles d'agriculture du tabac sont analysées sous deux formes : une version propre et une version délibérément contaminée où une unité est remplacée par des valeurs extrêmes. Les nouveaux estimateurs sont comparés aux méthodes traditionnelles de régression et aux méthodes robustes basées sur Huber en utilisant une mesure appelée efficacité relative en pourcentage, qui reflète la réduction de l'erreur d'estimation. Sur une large gamme de tailles d'échantillon, les estimateurs GM surpassent systématiquement les méthodes plus anciennes, en particulier lorsque les données incluent des valeurs extrêmes. Dans certains scénarios, l'estimateur GM le plus performant réduit l'erreur de plus de 50 % par rapport à l'approche de Huber.
Robustesse à travers dessins, contextes et choix de réglage Figure 2.
L'article élargit ensuite les tests à l'aide de simulations informatiques à grande échelle. Des populations artificielles sont générées sous plusieurs formes — distributions normales, asymétriques et à longues queues — et contaminées par des fractions variables de valeurs aberrantes, de aucune jusqu'à 20 %. Sont considérés à la fois des plans d'échantillonnage simples et stratifiés, et la force de la relation entre la variable principale et ses auxiliaires est modulée de faible à forte. Les estimateurs GM non seulement conservent leur avantage sous une forte contamination, atteignant souvent des gains d'efficacité supérieurs à 150 %, mais montrent aussi une convergence numérique régulière et fiable. Fait important, leurs performances varient peu lorsque les réglages internes sont ajustés dans des plages raisonnables, ce qui signifie que les praticiens n'ont pas besoin de les affiner délicatement pour chaque nouvelle enquête.
Ce que cela signifie pour les enquêtes réelles
En termes simples, l'article montre que les estimateurs proposés basés sur GM offrent une manière plus sûre de transformer des échantillons imparfaits en estimations des moyennes à l'échelle de la population. Dans des conditions de données idéales et propres, ils sont à peu près aussi précis que les méthodes classiques. Mais lorsque les données incluent des erreurs de mesure, des valeurs mal déclarées ou des événements rares et extrêmes — comme c'est courant dans les enquêtes nationales, la surveillance environnementale et les statistiques financières — ils fournissent des réponses sensiblement plus fiables. Parce qu'ils sont calculables en pratique et fonctionnent bien à travers différents plans et contextes, ces estimateurs offrent aux praticiens des enquêtes une amélioration pratique pouvant rendre les décisions fondées sur des preuves plus résistantes au désordre inévitable des données du monde réel.
Citation: Abuhasel, K.A. A robust methodology for finite population mean estimation based on Generalized M estimation.
Sci Rep16, 5182 (2026). https://doi.org/10.1038/s41598-026-35592-5
Mots-clés: échantillonnage d'enquête, estimation robuste, valeurs aberrantes, estimation M généralisée, moyenne d'une population finie