Clear Sky Science · fr
Reconnaissance à l’aveugle des codes de canal basée sur un réseau de neurones convolutionnel à fusion de caractéristiques à double branche
Des radios plus intelligentes pour des ondes encombrées
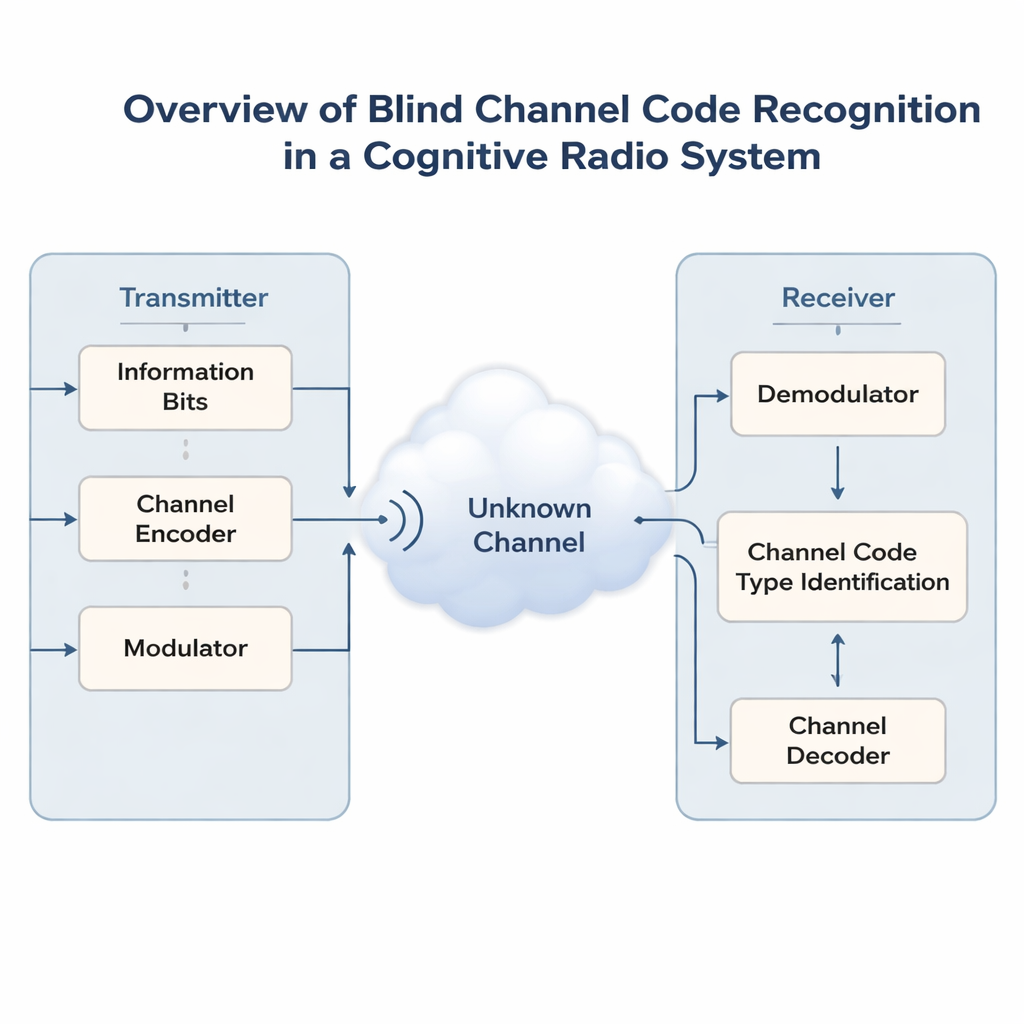
Les réseaux sans fil deviennent saturés à mesure que téléphones, capteurs et véhicules concurrencent les mêmes bandes de fréquence. Pour éviter le chaos, les futures « radios cognitives » devront d’abord écouter, puis partager intelligemment un spectre déjà utilisé par d’autres. Un problème central est que ces radios ignorent souvent comment le signal d’origine a été protégé contre les erreurs avant d’être envoyé. Cet article présente une nouvelle méthode d’intelligence artificielle capable de deviner le code correcteur d’erreurs caché utilisé sur un signal — sans aucune information préalable — ce qui facilite l’alignement des récepteurs intelligents et leur permet de communiquer de façon fiable.
Pourquoi les codes correcteurs d’erreurs cachés comptent
Les liens sans fil modernes protègent les données avec des codes correcteurs d’erreurs, qui ajoutent une redondance structurée pour permettre aux récepteurs de corriger les erreurs induites par le bruit et les interférences. Différentes situations exigent différents codes : des codes simples de Hamming, des codes plus puissants BCH et Reed–Solomon, des codes flexibles LDPC et Polar, ou des codes convolutionnels et Turbo adaptés au streaming. Dans des contextes non coopératifs — communications militaires, surveillance du spectre ou bandes partagées ouvertes — les récepteurs ne peuvent pas interroger l’émetteur sur le code utilisé. Ils ne voient qu’un flux de bits bruité. Deviner correctement le schéma de codage, tâche appelée reconnaissance aveugle de codes, est essentiel avant tout décodage significatif ou traitement de niveau supérieur.
Limites des méthodes de reconnaissance antérieures
Les recherches antérieures se sont soit concentrées sur une famille de codes à la fois, soit reposaient sur des statistiques conçues manuellement, comme la fréquence de répétition des bits, le degré d’aléa apparent d’une séquence, ou des astuces algébriques adaptées à un code particulier. Ces approches peuvent indiquer « il s’agit d’un type de code par bloc », mais peinent à distinguer plusieurs formats populaires simultanément. L’apprentissage profond a récemment amélioré la situation en traitant les flux de bits un peu comme des phrases dans un modèle de langage. Cependant, la plupart des réseaux neuronaux n’examinent que les séquences brutes ou uniquement des caractéristiques manuelles, et gèrent en général au maximum deux ou trois types de codes ensemble. Leur précision chute fortement lorsque le taux d’erreur binaire augmente, précisément lorsque la reconnaissance robuste est la plus nécessaire.
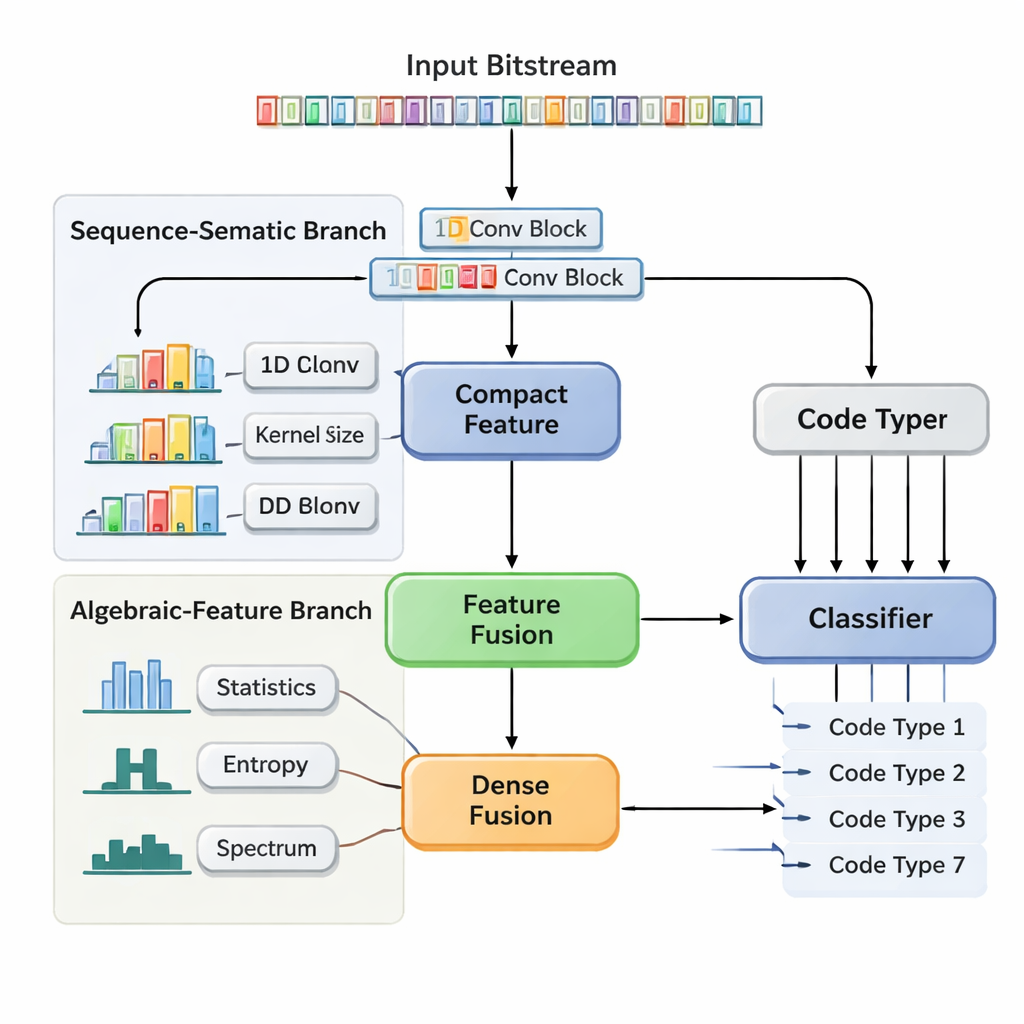
Un réseau neuronal à deux voies qui analyse structure et statistiques
Les auteurs proposent un réseau convolutionnel à fusion de caractéristiques à double branche (DBFCNN) qui traite la reconnaissance aveugle de sept codes largement utilisés en une seule passe : Hamming, BCH, Reed–Solomon, LDPC, Polar, codes convolutionnels et Turbo. La première branche considère les bits entrants comme de courts « mots », les regroupant en blocs de 8 bits et mappant chaque bloc sur un vecteur dense, à la manière d’un embedding en traitement du langage naturel. Elle applique ensuite un ensemble de convolutions unidimensionnelles avec différentes tailles de fenêtre et taux de dilatation. De petits filtres capturent des motifs de courte portée, comme la structure serrée des codes par bloc simples, tandis que des filtres plus larges et dilatés couvrent des portées plus longues, détectant des traces d’entrelaceurs et des motifs de parité typiques des codes Turbo et LDPC. Une étape de pooling global condense cela en un résumé compact de l’« empreinte » structurelle de la séquence.
Des mesures conçues à la main qui stabilisent le modèle
La seconde branche adopte une perspective très différente. Plutôt que d’utiliser les bits bruts, elle calcule sept familles de statistiques descriptives que les ingénieurs savent sensibles aux choix de codage. Celles-ci incluent la fréquence des runs de bits identiques, la complexité de la séquence, son aspect aléatoire, la corrélation avec des copies décalées d’elle‑même, et la répartition de son énergie selon les fréquences. Des mesures supplémentaires sondent le degré de « linéarité » apparente du code et le comportement local de blocs de bits. Parce que ces statistiques évoluent lentement lorsque le bruit augmente, elles fournissent au réseau une perspective stable et tolérante au bruit. Un petit sous‑réseau neuronal transforme ce vecteur de caractéristiques en une autre représentation compacte. Enfin, DBFCNN concatène les deux branches, normalise et régularise les caractéristiques combinées, puis les transmet à un classifieur qui renvoie des probabilités pour chacun des sept types de codes.
Validation de la fiabilité dans des conditions bruitées
Pour tester rigoureusement DBFCNN, les auteurs ont généré plus d’un million d’exemples synthétiques couvrant sept familles de codes, plusieurs réglages de paramètres et des taux d’erreur binaire allant de quasi nuls à des conditions extrêmement bruitées. Ils ont entraîné et évalué le modèle en utilisant des procédures de Monte Carlo soigneuses afin d’éviter tout recouvrement caché entre les jeux d’entraînement et de test. Sur cette large plage, DBFCNN a systématiquement surpassé trois fortes lignes de base, dont un CNN dilaté multi‑échelle antérieur conçu spécifiquement pour cette tâche. À des taux d’erreur modérés et faibles (taux d’erreur binaire inférieur à 10⁻³), le nouveau réseau a identifié correctement le type de code environ 98 % du temps, améliorant la précision absolue d’environ 5 à 11 points de pourcentage par rapport au meilleur modèle précédent. Même lorsque le niveau de bruit devenait assez sévère, DBFCNN conservait un avantage net et pouvait encore reconnaître plusieurs codes complexes avec une grande confiance.
Ce que cela signifie pour les radios intelligentes de demain
Pour un non‑spécialiste, l’essentiel est que ce travail montre comment la combinaison du savoir‑faire du domaine et de l’apprentissage profond peut rendre les radios beaucoup plus autonomes. DBFCNN apprend l’« accent » subtil des différents codes correcteurs d’erreurs dans des flux de bits bruités en écoutant de deux manières simultanément : une branche saisit des motifs locaux détaillés, tandis que l’autre mesure des indices statistiques globaux. En fusionnant ces points de vue, le système peut généralement déterminer exactement quel schéma de codage est utilisé, sans coopération de l’émetteur. Cette capacité constitue un élément fondamental pour des radios cognitives capables de rejoindre des réseaux inconnus, de s’adapter à des environnements changeants et de mieux exploiter un spectre rare, tout en maintenant des communications fiables même lorsque les ondes sont encombrées et bruyantes.
Citation: Ma, Y., Lei, Y., Liu, C. et al. Blind recognition of channel codes based on dual-branch feature fusion convolutional neural networks. Sci Rep 16, 5159 (2026). https://doi.org/10.1038/s41598-026-35558-7
Mots-clés: radio cognitive, codage de canal, apprentissage profond, correction d'erreurs, classification de signaux