Clear Sky Science · fr
Génération précise de comptes rendus de sortie en utilisant des grands modèles de langage affinés avec auto-évaluation
Pourquoi la paperasserie à l’hôpital compte vraiment
Quand un patient quitte l’hôpital, l’histoire de sa maladie ne s’arrête pas à la porte de sortie. Les médecins des autres cliniques, les médecins de famille et les patients eux-mêmes s’appuient tous sur un document clé appelé compte rendu de sortie pour comprendre ce qui s’est passé à l’hôpital et quelles sont les étapes suivantes. Pourtant, rédiger ces comptes rendus est un travail lent et répétitif qui peut prendre aux cliniciens occupés une demi-heure ou plus par patient. Cette étude explore comment les outils modernes de langage IA peuvent aider à rédiger des comptes rendus de sortie plus rapidement et avec plus de précision, tout en préservant la confidentialité des données patients et le contrôle de l’hôpital.
Transformer des dossiers éparpillés en une histoire claire
Les informations hospitalières sont réparties dans de nombreux systèmes électroniques : résultats de laboratoire dans un tableau, notes opératoires dans un autre, observations infirmières dans un troisième, et ainsi de suite. Le séjour de chaque patient génère des milliers de petits fragments de texte. Les chercheurs ont d’abord construit un pipeline pour transformer ces informations dispersées et désordonnées en une entrée propre que le modèle IA peut comprendre. En utilisant des méthodes pour fusionner et dédupliquer les enregistrements qui se chevauchent, filtrer les détails privés tels que les noms et identifiants, corriger l’orthographe et standardiser les termes médicaux, ils ont créé une entrée structurée pour chaque séjour hospitalier. Ce processus a été appliqué aux données de plus de 6 000 patients ayant subi une chirurgie thyroïdienne dans un grand hôpital chinois, produisant des exemples appariés de vrais comptes rendus de sortie et des données brutes à partir desquelles ils ont été rédigés. 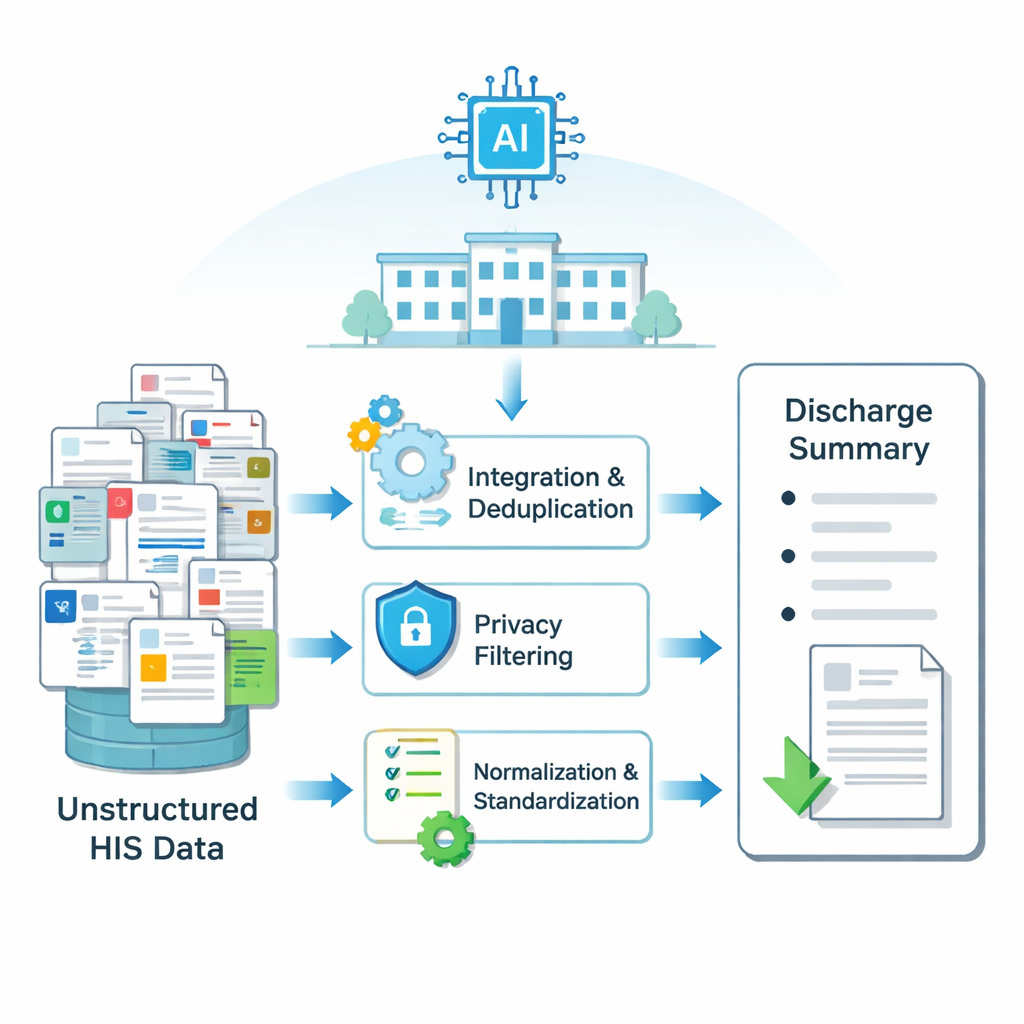
Affiner l’IA pour qu’elle parle le langage de la médecine
Les grands modèles de langage du commerce sont entraînés sur des textes généraux provenant d’internet et d’ouvrages, ils peinent donc souvent avec le langage médical spécialisé et les styles locaux de documentation. L’équipe a comparé plusieurs façons « d’affiner » des modèles existants afin qu’ils comprennent mieux les dossiers médicaux chinois. Une nouvelle méthode appelée adaptation à faible rang décomposée des poids, ou DoRA, ajuste les poids internes du modèle de manière plus ciblée que des techniques plus anciennes telles que LoRA et QLoRA. Sur différents modèles, y compris Qwen2, Mistral et Llama 3, DoRA a systématiquement produit des comptes rendus plus fluides, plus proches en sens de ceux rédigés par des humains, et moins confus (mesuré par une métrique standard appelée perplexité). En substance, DoRA a aidé l’IA à apprendre les tournures et la terminologie médicales sans nécessiter une réentraînement complet sur des infrastructures massives.
Apprendre à l’IA à vérifier son propre travail
Même un modèle bien entraîné peut oublier des détails importants ou introduire des erreurs mineures lorsqu’il rédige un long compte rendu en une seule passe. Inspirés par des idées psychologiques opposant la pensée rapide « Système 1 » à un raisonnement plus lent et attentif « Système 2 », les auteurs ont conçu une boucle d’auto-évaluation. D’abord, le modèle rédige un compte rendu de sortie initial à partir des données hospitalières traitées. Ensuite, les données originales sont découpées en segments—tels que les résultats de pathologie, les ordonnances des médecins ou les panels de laboratoire—et chaque segment est réapparié avec l’ébauche du compte rendu. On demande alors au modèle, en substance, « Tout ce qui figure dans ce segment est-il reflété dans le compte rendu ? » Si ce n’est pas le cas, il révise le texte pour ajouter les informations manquantes ou corriger les incohérences. Ce cycle se répète jusqu’à trois fois ou jusqu’à ce que le modèle juge le compte rendu complet, produisant une version raffinée qui correspond plus fidèlement au dossier du patient. 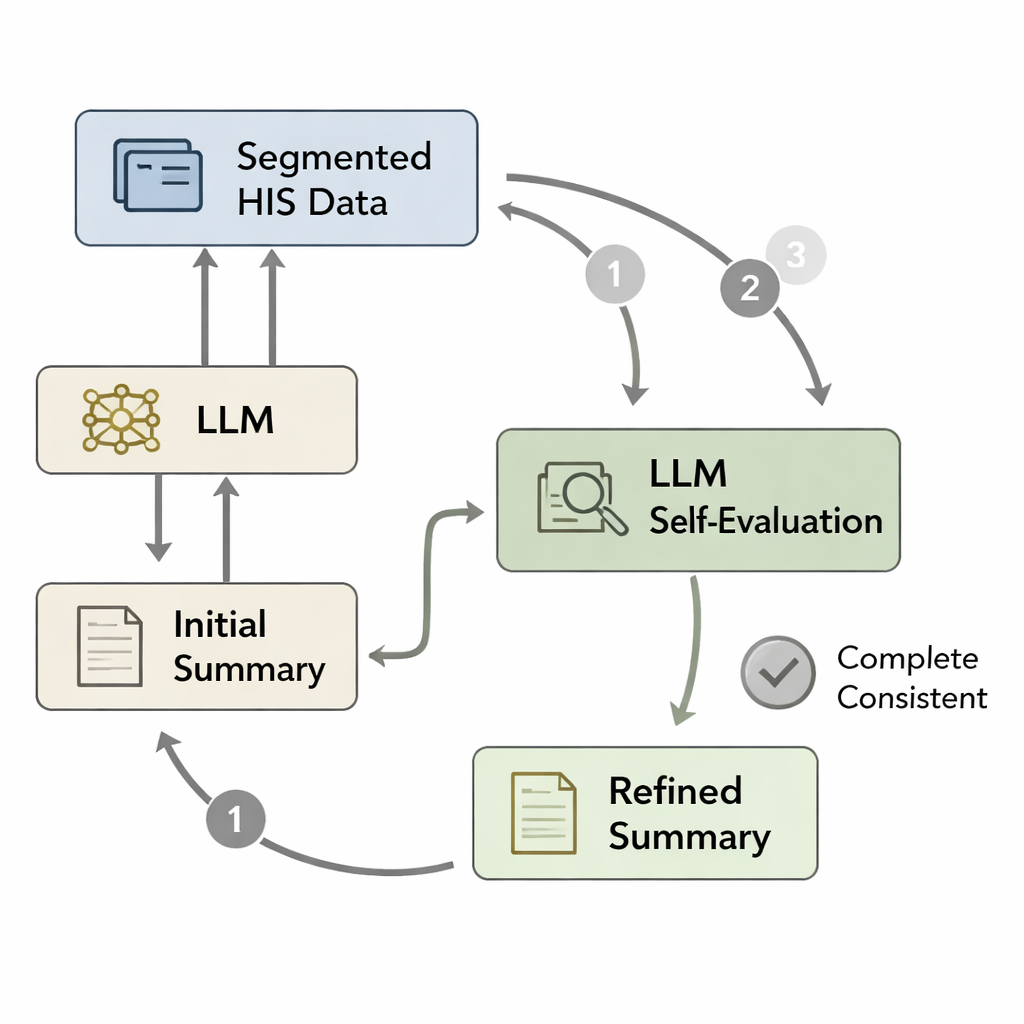
Que vaut l’IA par rapport aux humains ?
Pour évaluer la qualité, l’équipe a utilisé à la fois des scores automatiques et des évaluateurs humains. Des médecins et des chercheurs médicaux ont noté les comptes rendus selon l’exactitude, l’exhaustivité, la clarté, la cohérence et l’utilité pour la prise en charge continue. Le meilleur système—combinant l’affinage DoRA et la boucle d’auto-évaluation—s’est rapproché le plus des comptes rendus rédigés par des humains sur toutes les mesures. Il a particulièrement amélioré l’exhaustivité, c’est-à-dire qu’il y avait moins de diagnostics, traitements ou valeurs de laboratoire clés omis. Dans un exemple détaillé, l’IA avait initialement oublié de mentionner un petit cancer thyroïdien et une pilule hormonale spécifique ; après deux passes d’auto-évaluation, les deux détails avaient été correctement ajoutés. En moyenne, le système générait un compte rendu de sortie en environ 80 secondes sur un serveur hospitalier, contre 30–50 minutes pour qu’un clinicien en rédige un à partir de zéro, bien que la relecture humaine reste essentielle avant l’intégration du texte au dossier officiel.
Ce que cela pourrait signifier pour les patients et les cliniciens
L’étude montre qu’avec un entraînement soigné et des vérifications internes, les systèmes d’IA peuvent produire des comptes rendus de sortie suffisamment précis pour être considérés cliniquement acceptables après une rapide vérification humaine. Cela ne remplace pas les médecins, mais peut réorienter leur temps de la saisie répétitive vers la relecture et la prise de décisions à plus forte valeur ajoutée. En maintenant tous les calculs à l’intérieur du réseau hospitalier et en supprimant les éléments d’identification, l’approche respecte également la vie privée des patients. Bien que les résultats actuels proviennent d’un seul service dans un seul hôpital, le cadre ouvre la voie à un futur dans lequel l’IA aide à transformer des données médicales complexes en récits clairs et fiables dans de nombreuses spécialités, favorisant des transitions de soins plus sûres et une meilleure compréhension pour les patients et leurs familles.
Citation: Li, W., Feng, H., Hu, C. et al. Accurate discharge summary generation using fine tuned large language models with self evaluation. Sci Rep 16, 5607 (2026). https://doi.org/10.1038/s41598-026-35552-z
Mots-clés: comptes rendus de sortie, IA médicale, grands modèles de langage, documentation clinique, auto-évaluation