Clear Sky Science · fr
Géolocalisation d’utilisateurs sociaux basée sur K-médoïdes et un réseau d’attention sur graphe à noyau gaussien
Pourquoi vos tweets peuvent révéler où vous habitez
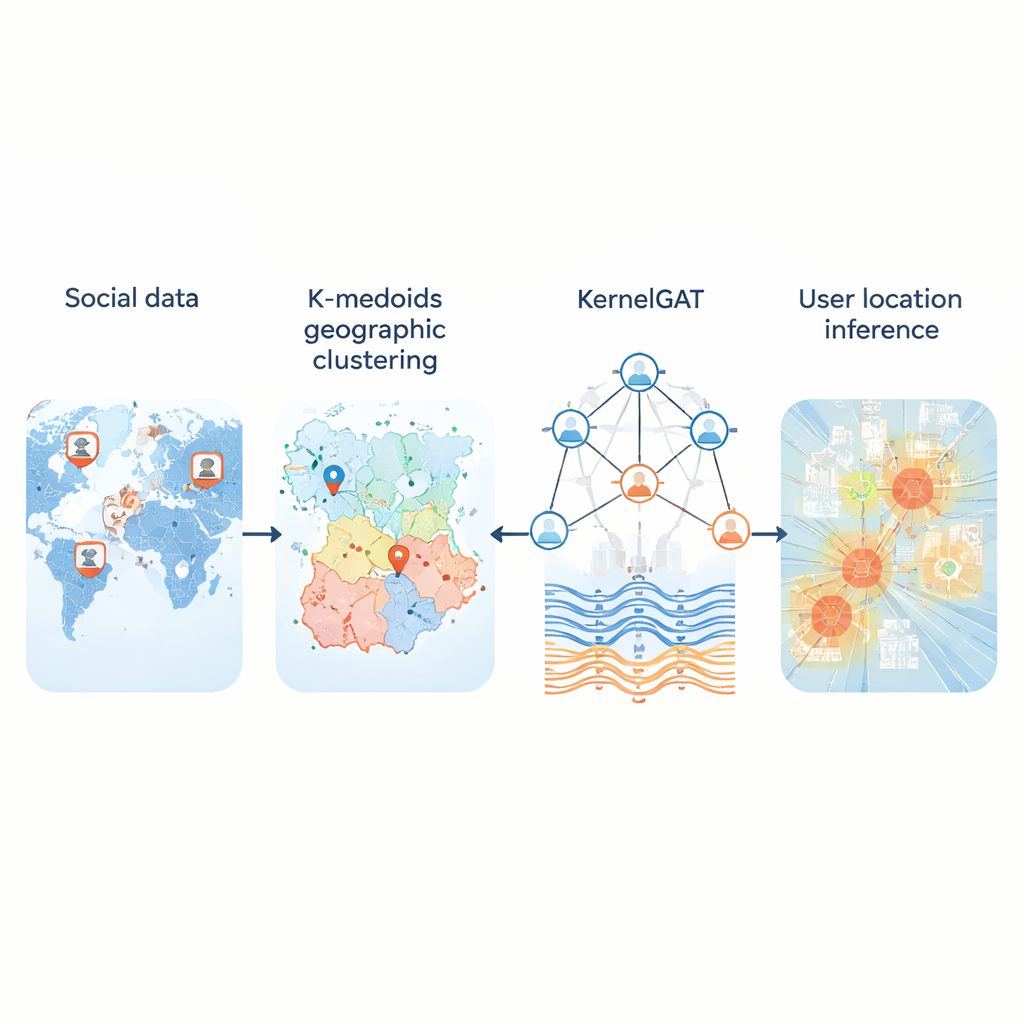
Chaque jour, des millions de personnes publient sur les réseaux sociaux sans partager leurs coordonnées GPS. Pourtant ces publications laissent des indices sur les lieux où les utilisateurs vivent, travaillent et voyagent. Pouvoir inférer la localisation à partir de cette trace publique importe pour tout, de la réponse aux urgences et le suivi des maladies aux recommandations locales et services ciblés. Cet article présente une nouvelle méthode, nommée KMKGAT, qui utilise à la fois le contenu des messages et les connexions en ligne pour estimer la localisation, avec une précision supérieure aux approches précédentes.
Du bavardage en ligne aux lieux du monde réel
Quand les utilisateurs écrivent des tweets ou des microblogs, ils peuvent mentionner des noms de lieux, employer des expressions locales ou interagir avec des amis proches géographiquement. Des entreprises comme Twitter (aujourd’hui X) connaissent l’adresse internet d’un utilisateur, mais les chercheurs extérieurs et les prestataires de services n’y ont généralement pas accès. Ils doivent donc s’appuyer sur l’information publique : le texte lui‑même, les profils utilisateurs et qui interagit avec qui. Les méthodes antérieures se répartissaient en trois familles. Les méthodes basées uniquement sur le contenu exploitaient mots et hashtags pour deviner des localisations. Les méthodes basées uniquement sur le réseau s’appuyaient sur le fait que les gens ont tendance à interagir avec des utilisateurs proches. Une troisième famille, plus puissante, combinait les deux points de vue, mais conservait des angles morts — en particulier pour les personnes dans des zones peu peuplées et pour celles dont les connexions en ligne couvrent de longues distances.
Regroupements géographiques plus intelligents avec des centres d’utilisateurs réels
Un problème clé est de transformer la surface continue de la Terre en un ensemble de régions qu’un ordinateur peut apprendre à prédire. De nombreux systèmes découpent la carte en une grille fixe. Cela fonctionne assez bien en ville mais échoue en milieu rural, où de vastes cellules couvrent des centaines de kilomètres. La nouvelle méthode remplace les grilles rigides par un regroupement en k‑médoïdes, une manière de grouper les utilisateurs de sorte que chaque région soit centrée sur un utilisateur réel plutôt que sur un point artificiel. Cela rend les régions plus compactes et moins sensibles aux valeurs aberrantes, notamment là où les utilisateurs sont peu nombreux. Dans des tests sur trois grands jeux de données Twitter couvrant les États‑Unis et le monde, ce partitionnement adaptatif a réduit les erreurs typiques comparé aux schémas basés sur des grilles et a fourni des « régions domicile » plus réalistes pour les utilisateurs.
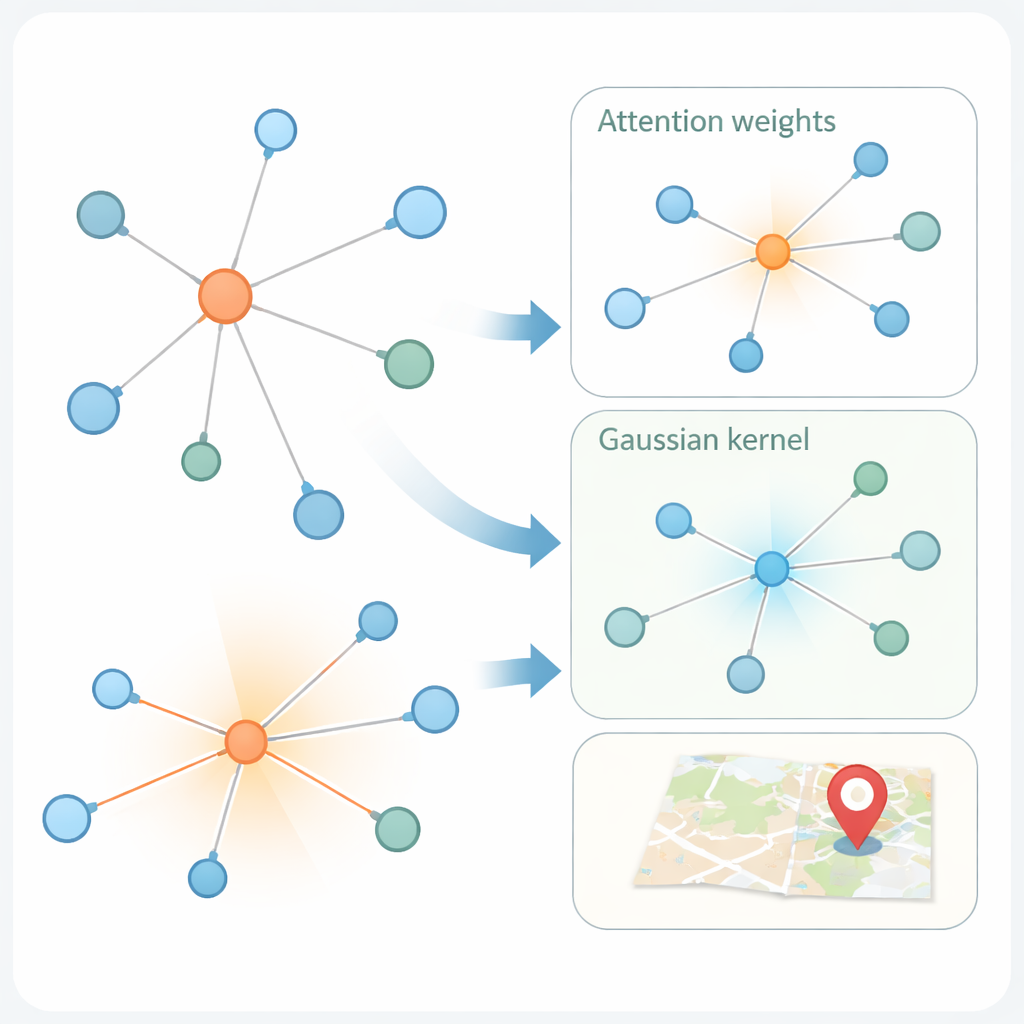
Laisser le réseau se concentrer sur des voisins proches et similaires
La deuxième innovation concerne la manière dont le modèle apprend à partir du graphe social. Les « graph attention networks » modernes pondèrent déjà différemment les voisins d’un utilisateur, en fonction de la similarité de leurs représentations de caractéristiques. Mais la similarité seule peut être trompeuse : un compte à New York et un autre à Londres peuvent utiliser un langage similaire tout en étant géographiquement éloignés. KMKGAT complète l’attention par un noyau gaussien, un filtre mathématique qui favorise les voisins dont les caractéristiques apprises sont proches de celles de l’utilisateur cible et atténue l’influence des voisins éloignés. Plusieurs noyaux de ce type, combinés comme un mélange de lentilles, permettent au modèle de capturer la localité à différentes échelles. Cela respecte le principe simple mais puissant selon lequel les interactions en ligne sont souvent les plus fortes entre personnes physiquement proches.
Des caractéristiques textuelles légères mais porteuses d’indices de localisation
Plutôt que de s’appuyer sur des modèles linguistiques profonds et lourds, qui peuvent peiner face au style bruité et argotique des tweets, les auteurs utilisent une technique classique appelée TF–IDF pour transformer la collection de messages de chaque utilisateur en un sac de mots-clés pondérés. Les mots courants comme « the » ou « lol » reçoivent peu de poids, tandis que des termes plus rares et spécifiques à une région remontent en tête. Ces caractéristiques textuelles sont ensuite attachées à chaque utilisateur dans le graphe social et transitent par le réseau d’attention amélioré. Fait intéressant, les meilleurs résultats ont été obtenus lorsque la plupart des caractéristiques textuelles étaient aléatoirement supprimées pendant l’entraînement, ce qui suggère qu’une petite fraction des mots aide réellement à localiser, le reste ajoutant surtout du bruit.
Devancer l’état de l’art à grande échelle
Pour évaluer les performances, les chercheurs ont mesuré la distance, en kilomètres, entre le centre de la région prédite et les coordonnées connues de chaque utilisateur, et le pourcentage d’utilisateurs placés à moins de 161 km (100 miles) de leur localisation réelle. Sur trois jeux de données Twitter de référence, KMKGAT a systématiquement égalé ou surpassé des systèmes solides existants, améliorant la précision « dans 161 km » de quelques points de pourcentage — un gain significatif à ce niveau de maturité. Les bénéfices étaient les plus nets sur des réseaux de petite et moyenne taille, tandis que sur un graphe mondial massif la méthode était limitée par la nécessité d’échantillonner uniquement les voisins immédiats pendant l’entraînement.
Ce que cela signifie au quotidien
Pour les non‑spécialistes, la conclusion est qu’il devient de plus en plus faisable d’estimer où se trouvent les utilisateurs des réseaux sociaux, même s’ils ne partagent jamais de balise de localisation. En regroupant les utilisateurs en régions réalistes basées sur des comptes réels et en apprenant au modèle à se fier principalement aux voisins proches et similaires dans le réseau social, KMKGAT restreint l’endroit d’où quelqu’un poste ou probablement habite. Cela peut aider les secours à localiser des personnes lors de catastrophes, améliorer la recherche locale et les recommandations, et soutenir des études sur la diffusion de l’information entre lieux. En même temps, cela illustre combien nos interactions ordinaires en ligne peuvent révéler sur notre vie hors ligne, soulignant l’importance d’une utilisation réfléchie des données et de protections de la vie privée.
Citation: Jiao, A., Qiao, Y., Li, P. et al. Social user geolocation based on K-medoids and Gaussian Kernel graph attention network. Sci Rep 16, 5115 (2026). https://doi.org/10.1038/s41598-026-35532-3
Mots-clés: géolocalisation sur les réseaux sociaux, localisation des utilisateurs Twitter, réseaux de neurones sur graphes, services basés sur la localisation, confidentialité en ligne