Clear Sky Science · fr
Identification automatisée d'entités biomédicales contextuellement pertinentes avec des LLM ancrés
Pourquoi un meilleur étiquetage des articles médicaux importe
Chaque année, des milliers d'études biomédicales paraissent, chacune remplie de détails sur des gènes, des types cellulaires, des maladies et des traitements. Pourtant, la plupart de ces informations restent enfermées dans de longs PDF, ce qui rend difficile pour d'autres scientifiques de trouver exactement les données dont ils ont besoin. Cet article examine comment l'intelligence artificielle moderne — les grands modèles de langage, ou LLM — peut automatiquement extraire ces termes biomédicaux clés des articles de recherche, contribuant à transformer des publications éparses en ressources bien organisées et consultables.
Des articles désordonnés à des blocs de construction consultables
Les centres de recherche biomédicale, comme les centres de recherche collaborative allemands, dépendent de données claires et structurées pour rendre les études réutilisables sur le long terme. Traditionnellement, les chercheurs devaient étiqueter manuellement leurs jeux de données avec des entités importantes telles que les organismes, les lignées cellulaires et les gènes — une tâche fastidieuse et chronophage. Les LLM peuvent lire des articles complets et comprendre le contexte, ce qui en fait des outils prometteurs pour automatiser cet étiquetage. Mais il y a un bémol : décider quels termes sont réellement pertinents dépend de la question scientifique et de la manière dont les données seront réutilisées. Les auteurs travaillent dans le cadre d'un schéma de métadonnées soigneusement conçu par le CRC axé sur la néphrologie, « NephGen », qui indique à l'IA quels types d'entités rechercher et comment elles doivent être organisées.
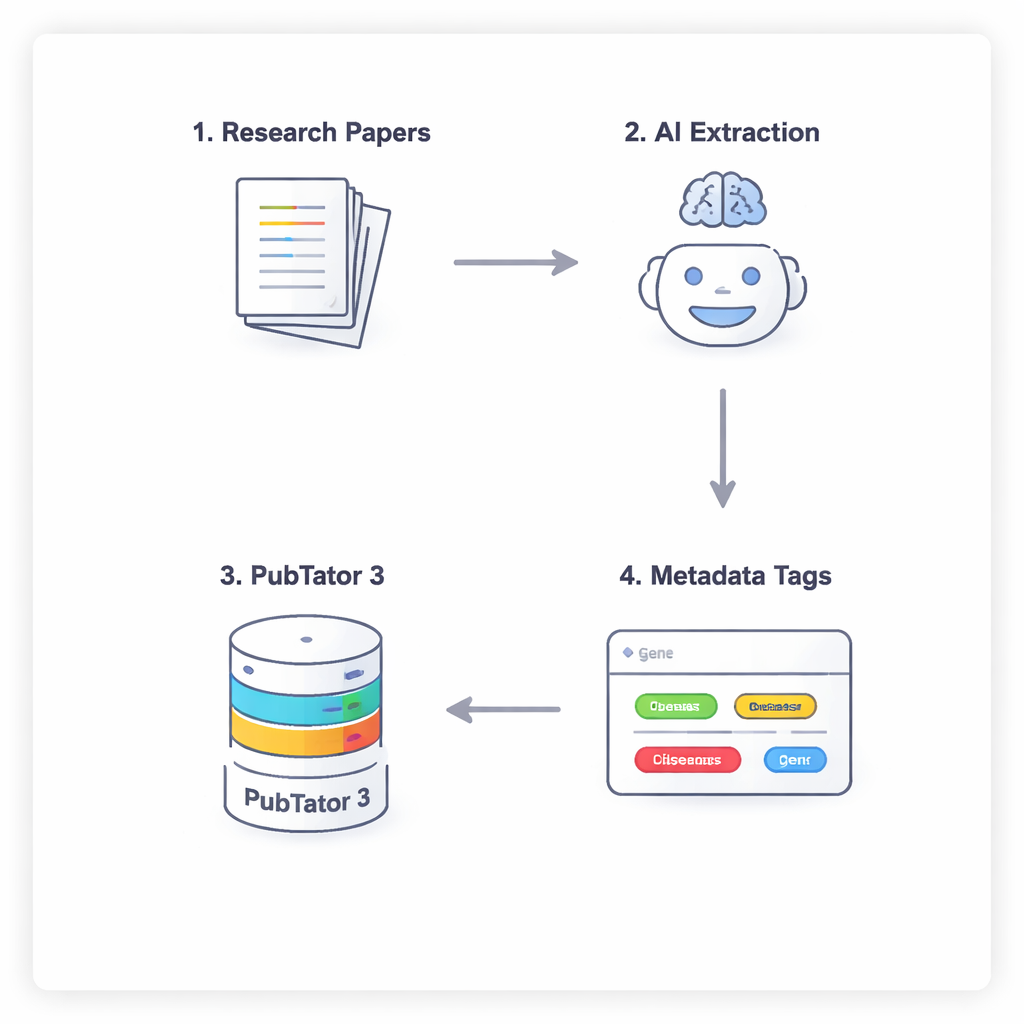
Une conversation en quatre étapes entre l'IA et une base de données biologique
Pour empêcher l'IA de simplement deviner ou « halluciner » des faits biomédicaux, les chercheurs utilisent un processus en quatre étapes qui oblige les modèles à raisonner soigneusement et à se vérifier. D'abord, le modèle parcourt le texte intégral d'un article (en ignorant la discussion et les références) pour proposer des entités potentiellement pertinentes. Ensuite, il doit consulter un outil externe, PubTator 3, une grande base de données biomédicale, pour confirmer que chaque terme proposé existe réellement et possède un identifiant reconnu. Troisièmement, l'IA assigne chaque entité confirmée à un emplacement du schéma de métadonnées NephGen, qui regroupe les entités dans une structure hiérarchique conçue par des humains. Enfin, le modèle consolide le tout dans une sortie JSON structurée, essentiellement un résumé lisible par machine des principales entités biomédicales de l'article.
Test de huit modèles d'IA avec de véritables recherches en rein
L'équipe a mis en œuvre ce flux de travail en utilisant des API pour 14 LLM différents et a constaté que seulement huit pouvaient suivre de manière fiable les exigences strictes, telles que renvoyer un JSON valide et utiliser correctement les outils. Ils ont ensuite appliqué ces huit modèles à six articles de recherche en néphrologie et ont demandé à l'auteur de chaque article de vérifier la liste finale d'entités produite par l'IA lors d'un court entretien en face à face. Parce qu'il n'existe pas de nombre « correct » fixe d'entités à extraire, les auteurs se sont concentrés sur la précision : quelle fraction des entités proposées les scientifiques ont jugé correcte. En utilisant des méthodes de méta-analyse statistique adaptées aux proportions proches de 100 %, ils ont estimé la précision pour chaque modèle en tenant compte de la variation entre les articles.
Haute précision, mais compromis sur l'effort, le coût et la vitesse
Sur l'ensemble des modèles, les systèmes d'IA ont atteint une précision globale d'environ 91 %, ce qui signifie que la grande majorité des entités proposées ont été jugées correctes. GPT-4.1, GPT-4o Mini et Gemini 2.0 Flash ont présenté la plus haute précision — environ 94 % à 98 % — bien que leurs différences ne soient pas statistiquement significatives. Les modèles Gemini ont tendance à proposer davantage d'entités au total, ce qui conduit à plus d'étiquettes correctes mais aussi à plus de vérifications humaines. Certains modèles plus petits ou moins coûteux, comme GPT-4.1 Nano, étaient plus rapides et bon marché mais sensiblement moins précis. Les auteurs ont visualisé ces tensions à l'aide de frontières de Pareto, identifiant des combinaisons de modèles qui équilibrent précision, nombre d'entités correctes, coût et temps de traitement : par exemple, GPT-4o Mini s'est avéré particulièrement attractif lorsque la précision et le faible coût sont prioritaires.
Pourquoi les humains restent essentiels dans la boucle
Malgré de bonnes performances, l'étude met en évidence des limites importantes. Les modèles confondaient parfois les informations relatives à l'article publié avec des détails qui n'étaient pas réellement pertinents pour le jeu de données sous-jacent que les futurs utilisateurs pourraient vouloir réutiliser. Cette confusion reflète un défi plus large de l'extraction automatique de texte : les articles scientifiques discutent de bien plus de choses que ce qui finit dans un jeu de données partagé. Les auteurs recommandent donc que des experts humains continuent de revoir les annotations générées par l'IA avant leur publication. Ils notent également que leur évaluation ne couvre que six articles de néphrologie, d'où la nécessité de tests plus larges dans d'autres domaines. Avec le temps, un flux de travail routinier « human-in-the-loop » pourrait construire un ensemble de référence consensuel, permettant de mesurer non seulement la précision mais aussi le nombre d'entités que l'IA a pu manquer.
Ce que cela signifie pour le partage futur des données biomédicales
L'étude montre que, lorsqu'ils sont guidés avec soin et ancrés dans des bases de données fiables, les LLM modernes peuvent aider de manière fiable à annoter les articles biomédicaux, réduisant considérablement la charge manuelle pour les chercheurs. Les meilleurs modèles approchent d'une précision au niveau des experts tout en offrant un éventail de compromis entre exhaustivité, coût et rapidité. Pour l'instant, la révision humaine demeure essentielle pour garantir que les annotations correspondent réellement aux jeux de données et au contexte de recherche. Mais à mesure que les outils et les modèles open source mûrissent, des flux de travail comme celui-ci pourraient devenir une colonne vertébrale standard pour transformer le flot actuel d'articles médicaux en un commun de données réutilisables et bien organisé de demain.
Citation: Watter, M., Giuliani, C., Benadi, G. et al. Automated identification of contextually relevant biomedical entities with grounded LLMs. Sci Rep 16, 1952 (2026). https://doi.org/10.1038/s41598-026-35492-8
Mots-clés: extraction de texte biomédical, grands modèles de langage, annotation de métadonnées, IA ancrée, recherche en néphrologie