Clear Sky Science · fr
Combiner la fragmentation des paramètres et le mélange par groupes pour se défendre contre un serveur non fiable en apprentissage fédéré
Pourquoi il est important de protéger les modèles partagés
Nos téléphones, hôpitaux et banques sont de plus en plus alimentés par l’intelligence artificielle. Souvent, plusieurs organisations souhaiteraient entraîner un modèle commun, mais la loi et le bon sens interdisent de rassembler leurs données brutes en un seul endroit. L’apprentissage fédéré a été conçu pour résoudre cette tension : chaque participant entraîne le modèle sur son propre appareil et ne partage que des mises à jour du modèle. Mais cet article montre que même ces mises à jour peuvent divulguer des informations privées si le serveur central est curieux ou malhonnête — et présente ensuite une nouvelle méthode pour mieux protéger à la fois nos données et nos identités.
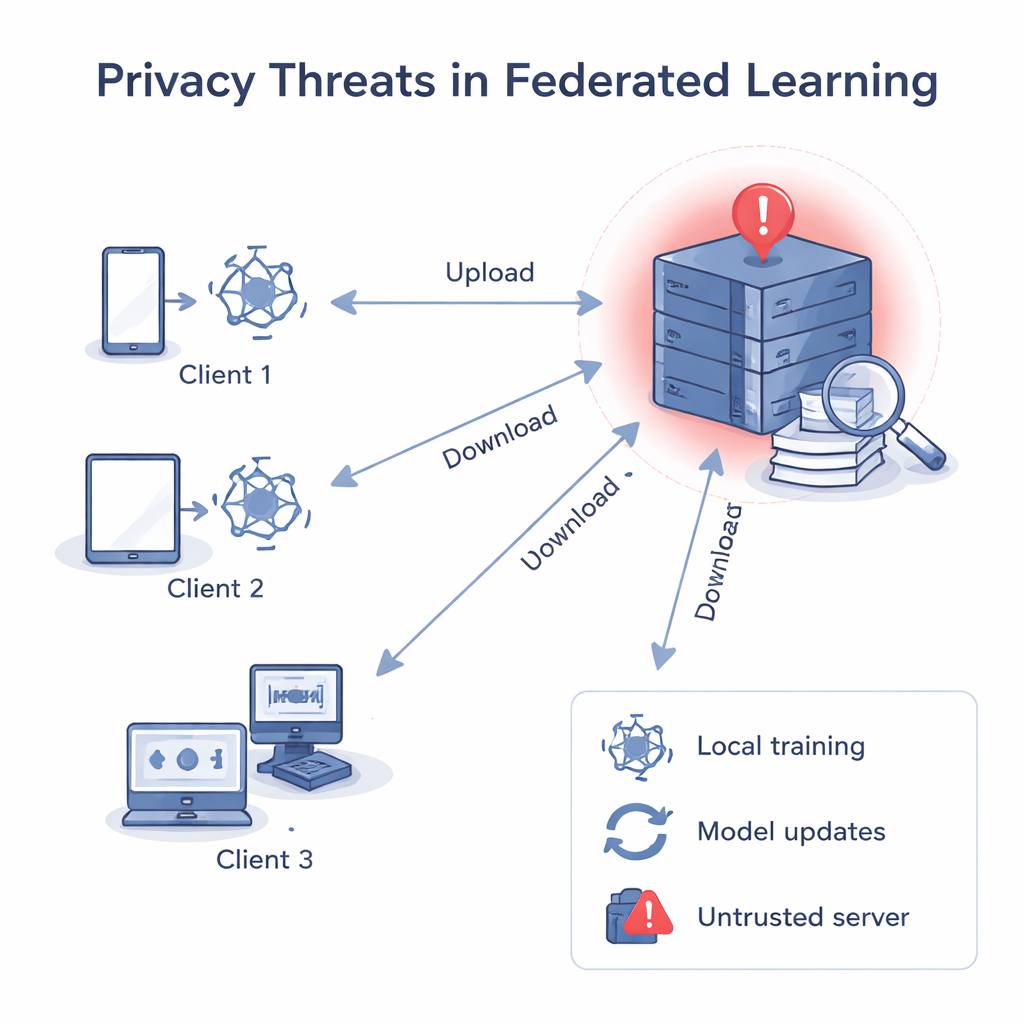
Quand le serveur ne devrait pas être digne de confiance
Dans l’apprentissage fédéré classique, un serveur central envoie un modèle commun, chaque client l’améliore avec ses propres données, puis renvoie la mise à jour. Le serveur moyenne ces mises à jour pour obtenir un modèle global amélioré. Même si les données brutes ne quittent jamais les appareils, des travaux antérieurs ont montré que les gradients et poids — les nombres à l’intérieur du modèle — peuvent être « inversés » pour reconstruire des données privées, comme des images ou du texte, ou pour deviner si un enregistrement particulier a été utilisé lors de l’entraînement. Si le serveur central n’est pas digne de confiance, il peut analyser séparément la mise à jour de chaque client, apprendre des choses sur les données locales de ce client, et même relier une mise à jour à une personne ou une organisation précise.
Découper les mises à jour en morceaux inoffensifs
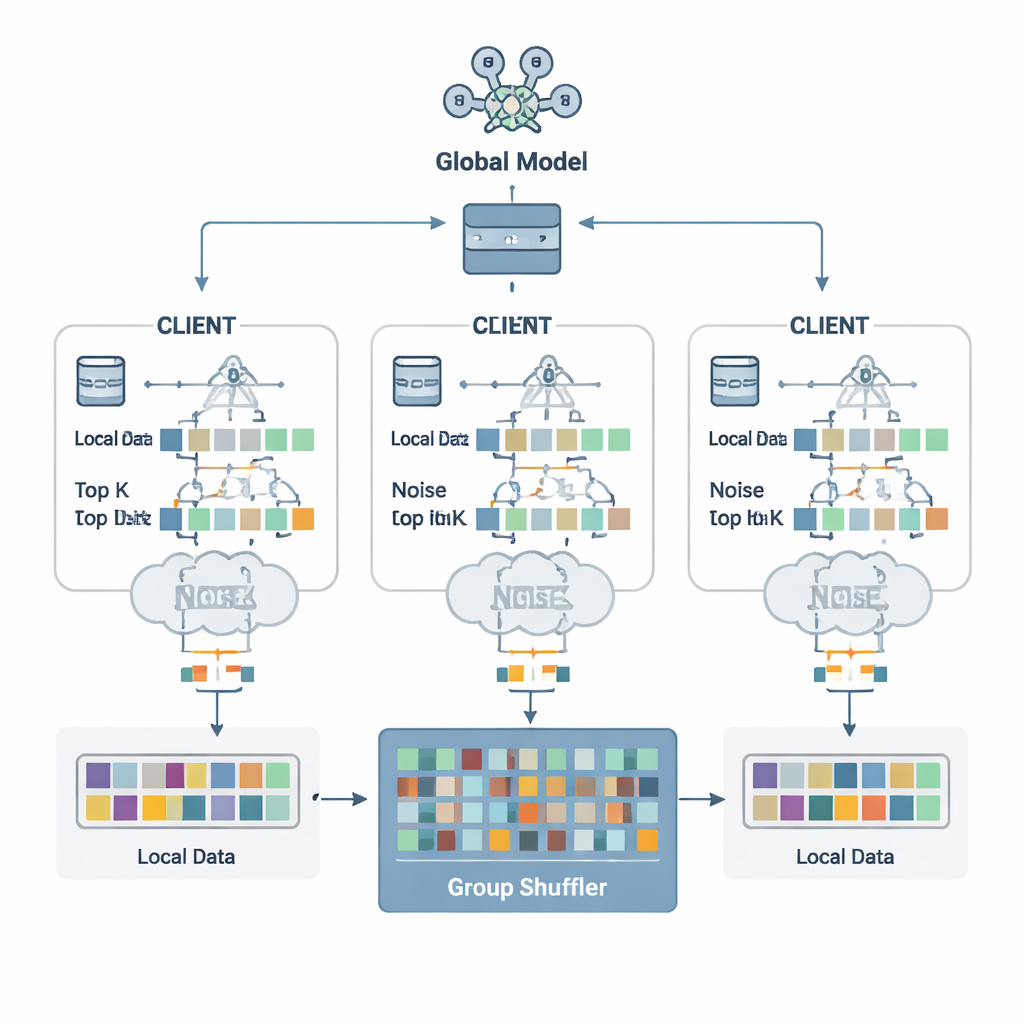
Les auteurs proposent un schéma de défense appelé Security Defense based on Parameter Fragmentation Group Shuffling (SDPFGS). La première idée est simple mais puissante : ne jamais envoyer une mise à jour complète. À la place, chaque client divise sa mise à jour de modèle en plusieurs « fragments » artificiels. La plupart de ces fragments sont remplis de nombres aléatoires, et seul le dernier est ajusté de sorte que la somme de tous les fragments reconstitue la vraie mise à jour. N’importe quel fragment seul, ou même plusieurs d’entre eux, ressemble à du bruit et révèle presque rien sur les données originales. Cette astuce mathématique est similaire au partage de secret : ce n’est qu’en combinant toutes les pièces qu’on peut retrouver l’ensemble.
Ajouter du bruit et remuer le tout
Envoyer beaucoup de fragments pourrait rester coûteux et, si on les examine ensemble, permettre à un attaquant d’inférer davantage. Pour éviter cela, chaque client ne sélectionne que les valeurs de fragment les plus importantes — les entrées Top-K qui comptent le plus pour l’apprentissage — et leur ajoute un bruit aléatoire soigneusement calibré suivant les principes de la confidentialité différentielle. Ce bruit rend statistiquement difficile de déterminer si les données d’une personne ont influencé une valeur donnée. Vient ensuite le second ingrédient clé : le mélange par groupes. Au lieu d’envoyer les fragments directement au serveur, les clients les transmettent à un « mélangeur » de confiance qui regroupe les fragments provenant de nombreux clients avant de les rediriger. Après ce mélange, le serveur ne peut plus dire quel fragment provient de quel client, rompant le lien entre mises à jour et identités.
Préserver la précision tout en réduisant les fuites
L’équipe a testé SDPFGS sur des jeux de référence standards pour l’image et le texte, y compris des chiffres manuscrits (MNIST), des photos de vêtements (Fashion-MNIST) et des images en couleur (CIFAR-10 et CIFAR-100), ainsi qu’une tâche de classification de nouvelles. Ils ont comparé leur méthode à plusieurs techniques de protection d’état de l’art utilisant uniquement du bruit, uniquement du mélange, ou une simple compression des gradients. Dans ces expériences, SDPFGS a systématiquement égalé ou dépassé la précision des méthodes concurrentes tout en nécessitant moins de communication et de temps d’entraînement que beaucoup d’entre elles. Plus notable encore, face aux attaques d’inversion de modèle — où un adversaire tente de reconstruire des exemples d’entraînement — SDPFGS a obtenu le taux de succès d’attaque le plus faible, ce qui signifie qu’il fuyait le moins d’informations sur les données sous-jacentes.
Ce que cela signifie pour les utilisateurs quotidiens
Pour un non-spécialiste, le message à retenir est que « cacher les données » ne suffit pas ; il faut aussi masquer ce que nos appareils envoient pendant l’entraînement. SDPFGS réalise cela en transformant chaque mise à jour de modèle en fragments bruyants et mélangés, inutiles pris isolément mais qui se combinent toujours pour former un modèle global de haute qualité. Le résultat est un bouclier plus solide contre un serveur curieux ou compromis, avec un coût mineur sur la précision et l’efficacité. À mesure que l’apprentissage fédéré se répand dans la santé, la finance et les appareils intelligents, des techniques comme SDPFGS pourraient aider à garantir que les personnes bénéficient de modèles partagés puissants sans livrer les clés de leur vie privée.
Citation: Guo, H., Chen, W., Li, J. et al. Combining parameter fragmentation and group shuffling to defend against the untrustworthy server in federated learning. Sci Rep 16, 5097 (2026). https://doi.org/10.1038/s41598-026-35420-w
Mots-clés: apprentissage fédéré, confidentialité des données, confidentialité différentielle, attaques d’inversion de modèle, agrégation sécurisée