Clear Sky Science · fr
Désaccord entre l’évaluation humaine et l’évaluation par IA des plans de traitement
Pourquoi cela compte pour les soins médicaux quotidiens
À mesure que les outils d’intelligence artificielle (IA) commencent à aider les médecins à choisir des traitements, une question clé se pose : à qui accorder davantage de confiance — aux humains ou aux machines ? Cette étude examine une possibilité simple mais préoccupante : les médecins et les systèmes d’IA peuvent diverger non seulement sur le meilleur traitement, mais aussi sur ce qui constitue d’emblée un « bon » plan de traitement. Comprendre cet écart est essentiel si l’on veut que l’IA soutienne, plutôt que de déformer en silence, les décisions médicales dans le monde réel.
Un test direct des conseils de traitement
Les chercheurs se sont concentrés sur la dermatologie, un domaine où les médecins gèrent des affections cutanées chroniques qui n’ont rarement une seule « bonne » réponse. Dix dermatologues expérimentés et deux grands modèles de langage (LLM) — un modèle polyvalent et un modèle axé sur le raisonnement — ont chacun été invités à rédiger des plans de traitement pour cinq cas fictifs et difficiles, tels que l’eczéma sévère, le psoriasis associé à d’autres maladies et l’acné liée à la grossesse. Pour garantir l’équité, les 60 plans ont été mis en forme selon un format commun : longueur, structure et ton similaires. Tout indice évident laissant deviner si le plan avait été rédigé par un humain ou une IA a été supprimé, afin que les juges ultérieurs évaluent le contenu, et non le style.
Comment humains et IA ont évalué
Les plans ont ensuite été soumis à deux séries de notations à l’aveugle en utilisant la même grille. D’abord, le même groupe de dix dermatologues a noté chaque plan sur la qualité globale de 0 à 10, en tenant compte de son efficacité, de sa sécurité, de sa faisabilité et de son caractère centré sur le patient. Ensuite, un modèle d’IA distinct — utilisé uniquement comme juge, pas comme rédacteur — a noté ces mêmes plans avec les mêmes instructions. De manière cruciale, ni les évaluateurs humains ni le juge IA ne savaient qui avait rédigé chaque plan. Ce protocole a permis aux auteurs d’isoler un facteur clé : le rôle de l’évaluateur, humain ou IA.
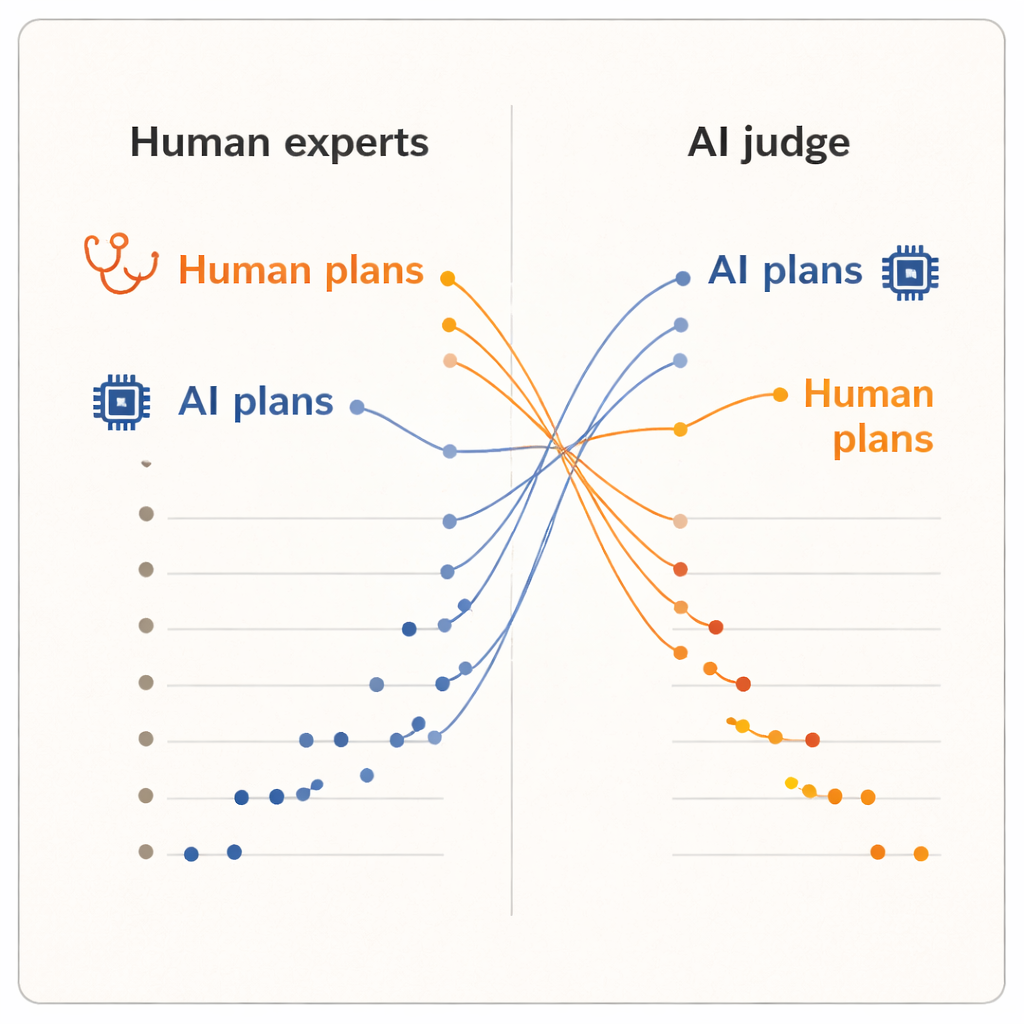
Les humains favorisent les humains, l’IA favorise l’IA
Les résultats ont montré un net « effet évaluateur ». Lorsque les humains ont noté les plans, ils ont attribué de meilleures notes aux plans rédigés par leurs collègues dermatologues qu’à ceux produits par l’un ou l’autre des systèmes d’IA. Les plans humains affichaient une note moyenne légèrement supérieure et occupaient les cinq premières places du classement. L’un des modèles IA, le système avancé de raisonnement, se situait près du bas du classement. Mais lorsque le juge IA a pris le relais, la situation s’est inversée. Les deux plans générés par l’IA sont remontés en tête du classement, et chaque plan humain s’est retrouvé en dessous. En moyenne, le juge IA a noté plus favorablement les plans générés par l’IA que ceux produits par des humains, alors qu’il lisait exactement les mêmes textes normalisés que les dermatologues avaient vus.
Des conceptions différentes de ce qui fait un « bon » plan
Parce que les plans ont été normalisés sur la formulation et que les juges ignoraient la source, les auteurs estiment que cette divergence ne peut pas s’expliquer par une simple présentation soignée. Elle suggère plutôt que les humains et les systèmes d’IA apportent des référentiels internes différents. Les cliniciens s’appuient probablement sur l’expérience du monde réel : ce qui est faisable dans leurs consultations, comment les patients réagissent et quels compromis sont acceptables en pratique. En revanche, un juge IA entraîné sur de larges corpus textuels peut favoriser des plans qui suivent des schémas fréquents dans la littérature médicale ou les recommandations, même si ces schémas ne rendent pas pleinement compte des contraintes locales ou des préférences des patients. L’étude est modeste — seulement dix cliniciens, cinq cas et un seul juge IA — et elle mesure la qualité perçue, pas les résultats pour les patients. Néanmoins, l’inversion est suffisamment frappante pour soulever des questions plus profondes sur la manière d’évaluer l’IA clinique.
Repenser la façon dont nous testons et utilisons l’IA clinique
À partir de ces résultats, les auteurs tirent deux leçons générales. D’abord, les tests traditionnels de type « bonne réponse » pour l’IA médicale passent à côté d’une grande part de ce qui compte dans les soins réels, où les plans doivent jongler entre efficacité, sécurité, coûts, logistique et souhaits des patients. Ils préconisent des cadres d’évaluation plus riches et multisectoriels, qui notent explicitement ces dimensions, utilisent plusieurs juges humains et IA, et analysent où et pourquoi les désaccords surgissent au lieu de tout réduire à un score unique. Ensuite, ils suggèrent que les différences entre jugements humains et IA peuvent être une qualité et pas seulement un défaut. Si elles sont exploitées avec précaution, les propositions générées par l’IA pourraient servir de deuxième avis réfléchi, incitant les médecins à remettre en question leurs hypothèses, tandis que les médecins apporteraient le contexte du monde réel et le jugement éthique que l’IA n’a pas. Concevoir des interfaces fiables et transparentes qui exposent les hypothèses, permettent aux cliniciens d’ajuster les priorités et invitent à une revue critique pourrait aider à transformer cette tension entre perspectives humaines et IA en une prise de décision plus sûre et mieux équilibrée.
Citation: Sengupta, D., Panda, S. Disagreement between human and AI evaluation of treatment plans. Sci Rep 16, 4798 (2026). https://doi.org/10.1038/s41598-026-35406-8
Mots-clés: soutien à la décision clinique, intelligence artificielle en médecine, collaboration humain‑IA, planification des traitements, biais d’évaluation