Clear Sky Science · fr
Un modèle de prévision hybride de la concentration de PM2,5 basé sur des IMF haute et basse fréquence issues de la décomposition EMD
Pourquoi des prévisions d’air plus propres importent au quotidien
Les particules fines dans l’air, appelées PM2,5, sont suffisamment petites pour pénétrer profondément dans nos poumons et même atteindre la circulation sanguine. Dans le nord de la Chine, où l’industrie lourde et le chauffage hivernal sont concentrés, ces particules atteignent souvent des niveaux qui peuvent déclencher des alertes sanitaires, perturber les déplacements et même entraîner la fermeture d’usines et d’écoles. Cette étude pose une question très pratique : peut‑on prévoir l’évolution horaire des concentrations de PM2,5 de manière plus précise, afin que les villes et les habitants reçoivent des alertes plus précoces et plus fiables avant que l’air ne devienne dangereux ?
Un regard plus proche sur la mauvaise qualité de l’air dans le Nord de la Chine
Les chercheurs se sont concentrés sur six grandes villes du nord de la Chine : Pékin, Tianjin, Shijiazhuang, Taiyuan, Jinan et Zhengzhou. Ces villes représentent des zones densément peuplées et industrialisées où les épisodes de pollution sont fréquents, en particulier en hiver. En utilisant des données de surveillance officielles, l’équipe a collecté des relevés horaires de PM2,5 pour l’année 2021 entière, soit 8 760 points de données pour chaque ville. Ils ont constaté que les niveaux de pollution variaient fortement d’une ville à l’autre ; par exemple, Taiyuan présentait la moyenne de PM2,5 la plus élevée, tandis que Pékin affichait la plus basse. Les événements extrêmes étaient marquants : à Taiyuan, les concentrations ont culminé à 652 microgrammes par mètre cube lors d’un épisode de poussière et de pollution en mars, poussant l’indice de qualité de l’air à son niveau maximal, signe net d’un air fortement pollué.
Pourquoi il est si difficile de prévoir le PM2,5
Les niveaux de PM2,5 sont poussés et tirés par de nombreuses forces à la fois — émissions locales du trafic et des usines, transport régional de poussières et de fumées, vitesse du vent, humidité, et plus encore. En conséquence, l’enregistrement de la pollution se comporte moins comme une courbe lisse que comme un battement de cœur saccadé et agité. Les outils statistiques traditionnels ou même les réseaux neuronaux modernes peuvent peiner avec ce type de données : ils peuvent capter la tendance générale mais manquer des pointes soudaines, ou fonctionner dans une ville mais échouer dans une autre. Des études antérieures ont tenté d’améliorer les prévisions soit en ajoutant plus de détails physiques (comme les modèles de transport chimique), soit en se reposant uniquement sur des méthodes avancées d’apprentissage automatique. Cet article combine au contraire plusieurs méthodes, chacune choisie pour gérer un « rythme » différent dans les données.
Diviser le signal en rythmes rapides et lents
L’étape clé est une technique appelée décomposition en modes intrinsèques (EMD), qui scinde la série temporelle originale de PM2,5 en plusieurs composantes plus simples. Certaines de ces composantes ondulent rapidement et captent les pointes à court terme et le bruit ; d’autres évoluent lentement et reflètent la tendance sous‑jacente. Les auteurs regroupent les cinq premières composantes comme parties « haute fréquence » et les restantes, plus une tendance résiduelle, comme parties « basse fréquence ». Les morceaux haute fréquence, plus irréguliers et fortement non linéaires, sont fournis à un réseau LSTM (long short‑term memory), un type de modèle d’apprentissage profond bien adapté à l’apprentissage des motifs temporels. Les composantes plus lisses et basse fréquence sont traitées par une méthode classique de séries temporelles connue sous le nom d’ARIMA, efficace lorsque les données se comportent de manière plus régulière et quasi linéaire.
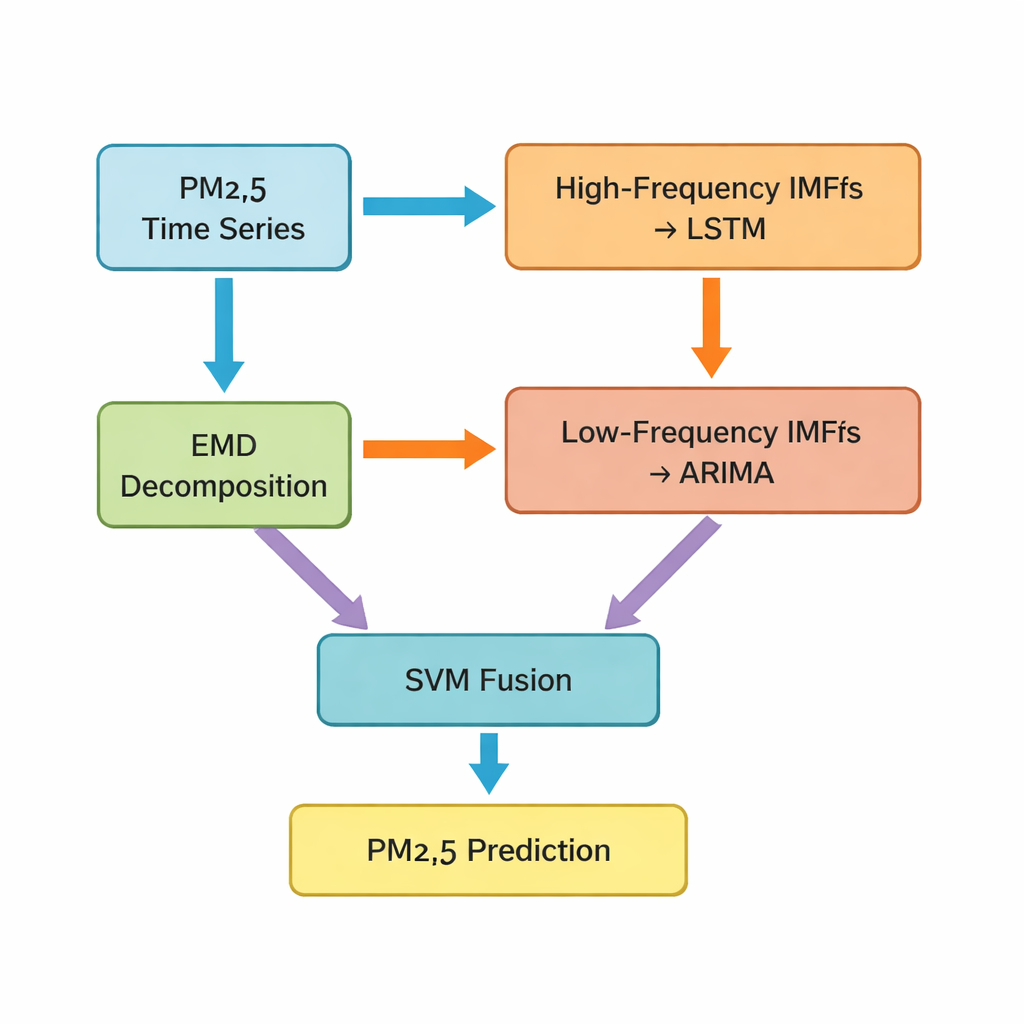
Combiner différents modèles en une prévision plus intelligente
Après que les modèles LSTM et ARIMA ont chacun produit leurs prévisions partielles, l’étude fait face à un défi : comment fusionner ces prédictions séparées en une valeur finale de PM2,5 la plus fiable pour l’heure suivante. Pour cela, les auteurs utilisent une machine à vecteurs de support (SVM), une autre méthode d’apprentissage automatique qui apprend à pondérer et combiner les deux entrées. En essence, la SVM agit comme un arbitre, décidant quand la vision « rapide » (les motifs haute fréquence) compte davantage et quand la vision « lente » (les tendances à long terme) doit dominer. Le système combiné, que les auteurs appellent Hybrid‑EMDHL, est ensuite évalué à l’aide de plusieurs indicateurs de performance, notamment l’erreur moyenne, la proximité entre les prévisions et les valeurs observées, et la capacité du modèle à prévoir la direction du changement — si les niveaux augmentent ou baissent.
Des alertes plus nettes et une meilleure planification
Le modèle hybride surpasse chacune de ses composantes utilisées seules dans les six villes. Il réduit non seulement les erreurs moyennes et quadratiques, mais améliore aussi fortement la capacité à anticiper correctement si le PM2,5 va augmenter ou diminuer lors de l’heure suivante — une caractéristique cruciale pour émettre des avis sanitaires en temps utile. Dans de nombreux cas, l’approche hybride divise par plus de deux les mesures d’erreur par rapport à un modèle neuronal unique, et sa « précision de direction » dépasse 0,69, ce qui signifie que dans bien plus des deux‑tiers des cas de test il prédit correctement la tendance. Pour un non‑spécialiste, cela se traduit par des prévisions de qualité de l’air, à la manière météo, à la fois plus nettes et plus fiables. Pour les urbanistes et les autorités sanitaires, c’est un outil pratique pour soutenir des actions ciblées et anticipées — comme ajuster les activités industrielles ou la circulation — avant le pic d’un épisode de pollution, aidant ainsi à réduire l’exposition et à protéger la vie quotidienne dans certaines des régions urbaines les plus polluées de Chine.
Citation: Wang, P., Wu, Q. & Zhang, G. A hybrid prediction model for PM2.5 concentration based on high-frequency and low-frequency IMFs with EMD decomposition. Sci Rep 16, 4969 (2026). https://doi.org/10.1038/s41598-026-35386-9
Mots-clés: prévision PM2,5, pollution de l'air, Nord de la Chine, apprentissage automatique, décomposition de séries temporelles