Clear Sky Science · fr
QPSODRL : un protocole de regroupement et de routage intelligent pour réseaux de capteurs sans fil, fondé sur une optimisation de particules quantique améliorée et l’apprentissage par renforcement profond
Des réseaux de capteurs plus intelligents pour un monde connecté
De l’agriculture de précision aux systèmes d’alerte en cas de catastrophe, les réseaux de capteurs sans fil surveillent discrètement notre environnement, collectant des données à partir de centaines voire de milliers de petits dispositifs disséminés sur de vastes zones. Leur plus grande faiblesse est aussi leur caractéristique déterminante : chaque capteur fonctionne sur une petite batterie difficile ou impossible à remplacer. Cet article présente une nouvelle façon d’organiser et d’orienter le flux de données dans ces réseaux afin d’allonger la durée de vie des batteries, d’améliorer la fiabilité des transmissions et de permettre au réseau de s’adapter lorsque les conditions évoluent.
Pourquoi de petits dispositifs nécessitent une grande intelligence
Dans un réseau de capteurs sans fil, chaque nœud peut mesurer, calculer et communiquer, mais l’énergie est précieuse. Si certains nœuds réalisent trop de travail, ils s’épuisent rapidement, créant des « zones mortes » où aucune donnée ne peut être collectée. Pour éviter cela, les concepteurs regroupent généralement les nœuds en clusters. Au sein de chaque cluster, un nœud devient chef de cluster : il collecte les relevés de ses voisins et les achemine vers une station de base centrale. Choisir quels nœuds doivent être chefs de cluster et comment les données doivent sauter à travers le réseau est un puzzle complexe qui change à mesure que les batteries s’épuisent. Les solutions traditionnelles basées sur des règles ou sur un seul algorithme ont souvent tendance à se fixer trop rapidement sur des schémas sous‑optimaux ou à échouer lorsque la topologie du réseau et les niveaux d’énergie évoluent dans le temps.
Mélanger des essaims inspirés de la mécanique quantique avec des machines d’apprentissage
Cette étude introduit QPSODRL, un protocole qui marie deux idées puissantes : une méthode d’essaim inspirée de la mécanique quantique pour former les clusters et un moteur d’apprentissage par renforcement profond pour le routage. Dans la première étape, des « particules » virtuelles explorent différentes manières d’affecter les chefs de cluster et les membres. Leur comportement est guidé par une mesure de la répartition de l’énergie sur le réseau, connue sous le nom d’entropie. Lorsque l’utilisation d’énergie est déséquilibrée, l’algorithme encourage une large exploration de nouvelles configurations de clusters ; lorsque la situation semble stable, il affine les dispositions prometteuses. Une étape spéciale de « perturbation d’élite » pousse occasionnellement les meilleurs candidats dans de nouvelles directions, aidant la recherche à échapper aux impasses locales et à éviter de sursolliciter les mêmes nœuds à haute consommation. 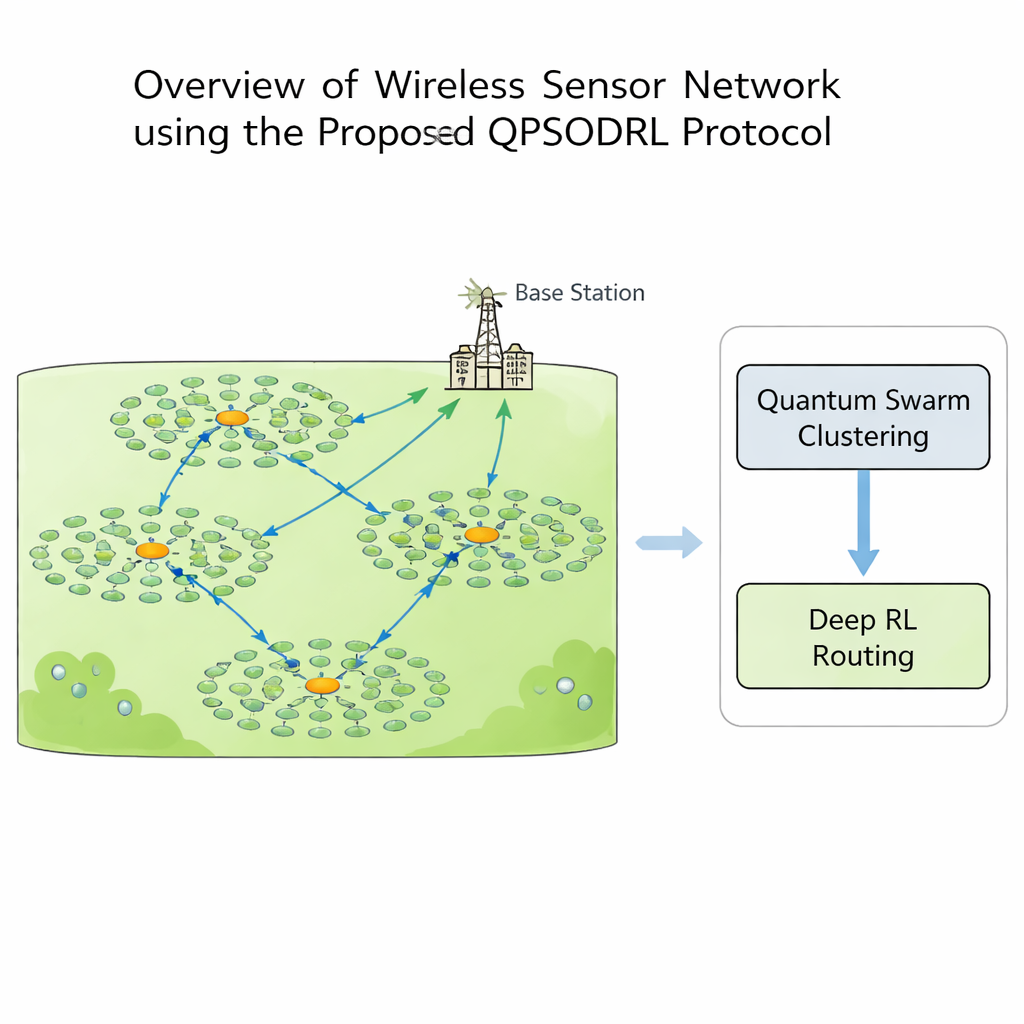
Apprendre au réseau à trouver de meilleurs chemins
Une fois les clusters formés, la deuxième étape décide comment chaque chef de cluster doit envoyer ses données à la station de base. Au lieu de suivre des routes fixes, QPSODRL considère chaque chef de cluster comme un agent dans un processus d’apprentissage. À chaque étape, l’agent observe sa propre énergie restante, l’énergie et la distance des chefs voisins, ainsi que les retards estimés, puis choisit le prochain saut. Une forme spécialisée d’apprentissage Q profond, appelée Dueling Double Deep Q‑Network, estime la qualité à long terme de chaque choix. Les auteurs ajoutent un terme d’« entropie » pour décourager le système de devenir trop confiant trop rapidement, afin qu’il continue d’explorer des routes alternatives. Ils conçoivent également un mécanisme amélioré de relecture d’expérience qui concentre délibérément l’apprentissage sur les situations les plus informatives — par exemple lorsque l’énergie est faible ou que les retards augmentent — afin que le modèle s’améliore plus rapidement dans les scénarios les plus critiques. 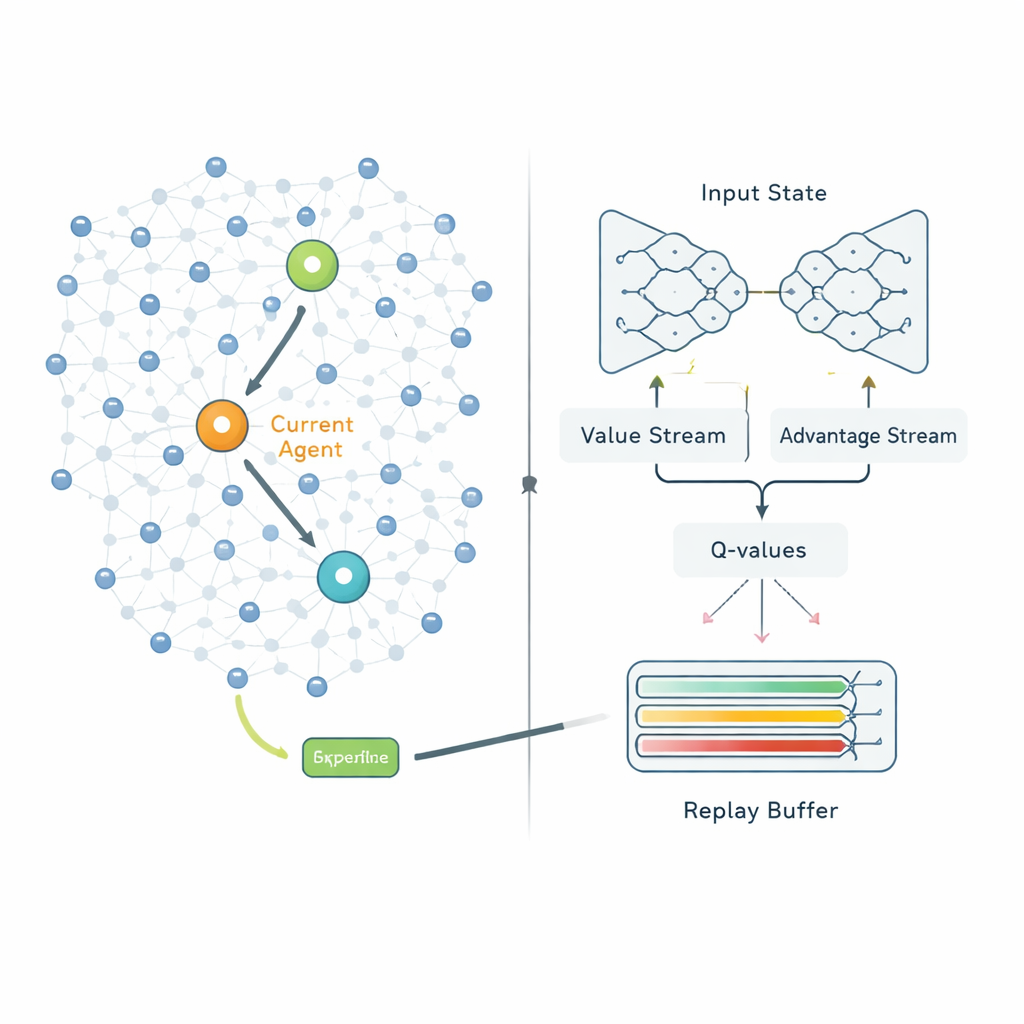
Mettre l’approche à l’épreuve
Pour évaluer les performances de QPSODRL, l’auteur réalise des simulations informatiques détaillées de réseaux de 100 et 200 nœuds répartis sur des zones de tailles différentes et avec des fractions variables de nœuds agissant comme chefs de cluster. Le nouveau protocole est comparé à quatre concurrents récents et avancés qui utilisent des essaims de particules, l’optimisation par baleines, la logique floue ou d’autres schémas hybrides et basés sur l’apprentissage. Dans toutes les configurations testées, QPSODRL maintient le réseau actif pendant davantage de cycles de communication, livre plus de paquets de données à la station de base et consomme moins d’énergie totale. Il répartit également la charge parmi les chefs de cluster de manière plus homogène, comme le montre une variation plus faible du trafic traité par chaque chef. Ces gains sont particulièrement marqués dans des dispositions plus difficiles où la station de base est placée en bordure du champ, obligeant certains nœuds à effectuer des sauts plus longs.
Ce que cela signifie pour les systèmes réels
Pour les non‑spécialistes, le message principal est que doter les réseaux de capteurs de la capacité à optimiser globalement leur structure tout en apprenant localement de l’expérience peut prolonger significativement leur durée de vie utile. Le regroupement inspiré par la mécanique quantique de QPSODRL maintient l’usage d’énergie équilibré, tandis que son routage fondé sur l’apprentissage profond s’adapte aux conditions changeantes sans réglages humains constants. Bien que les résultats reposent sur des simulations avec des nœuds fixes et non mobiles, ils suggèrent que de futures déploiements de capteurs — des villes intelligentes aux observatoires environnementaux — pourraient fonctionner plus longtemps, tomber en panne moins souvent et mieux exploiter l’énergie limitée des batteries en adoptant des stratégies de contrôle intelligent similaires.
Citation: Guangjie, L. QPSODRL: an improved quantum particle swarm optimization and deep reinforcement learning based intelligent clustering and routing protocol for wireless sensor networks. Sci Rep 16, 5526 (2026). https://doi.org/10.1038/s41598-026-35365-0
Mots-clés: réseaux de capteurs sans fil, routage économe en énergie, apprentissage par renforcement profond, optimisation par essaim, regroupement de réseau