Clear Sky Science · fr
Intégration des connaissances pour la régression symbolique informée par la physique en utilisant des grands modèles de langage pré-entraînés
Apprendre aux ordinateurs à deviner les formules de la nature
Beaucoup des grandes idées en science se résument sous forme d’équations élégantes : de la chute d’une balle à la propagation des ondes lumineuses dans l’espace. Cet article explore une nouvelle manière d’aider les ordinateurs à redécouvrir automatiquement de telles équations à partir de données brutes, en leur permettant de consulter un grand modèle de langage — le même type d’IA qui alimente les chatbots modernes — afin que leurs hypothèses soient non seulement précises, mais aussi physiquement cohérentes.
Des données brutes aux lois lisibles par l’humain
Les auteurs se concentrent sur une technique appelée régression symbolique, qui recherche une formule mathématique liant des entrées et sorties mesurées. À la différence d’un simple ajustement de courbe, la régression symbolique ne part pas d’une forme de formule prédéfinie ; elle construit et fait évoluer des équations candidates jusqu’à en trouver une qui s’ajuste bien aux données. Cela en fait un outil prometteur pour la découverte scientifique, car il peut potentiellement révéler de nouvelles relations jamais formulées auparavant. Mais il y a un bémol : une formule qui ajuste parfaitement les données peut rester absurde d’un point de vue physique — par exemple, additionner une distance et un temps, ou produire des unités qui ne correspondent à aucune grandeur réelle.
Pourquoi l’intuition physique reste importante
Pour éviter de telles absurdités, les chercheurs ont développé des versions « informées par la physique » de la régression symbolique qui intègrent des règles connues de la nature dans la recherche. Ces méthodes récompensent par exemple les équations qui conservent l’énergie ou respectent la cohérence dimensionnelle. Cependant, l’encodage de ces connaissances a généralement exigé que des experts conçoivent à la main des contraintes et des fonctions de perte spéciales pour chaque nouveau problème. Cela rend l’approche puissante mais difficile à généraliser. Chaque nouveau système physique peut nécessiter un travail de conception spécifique, limitant l’accessibilité de ces outils aux non-spécialistes.
Laisser les modèles de langage juger les équations
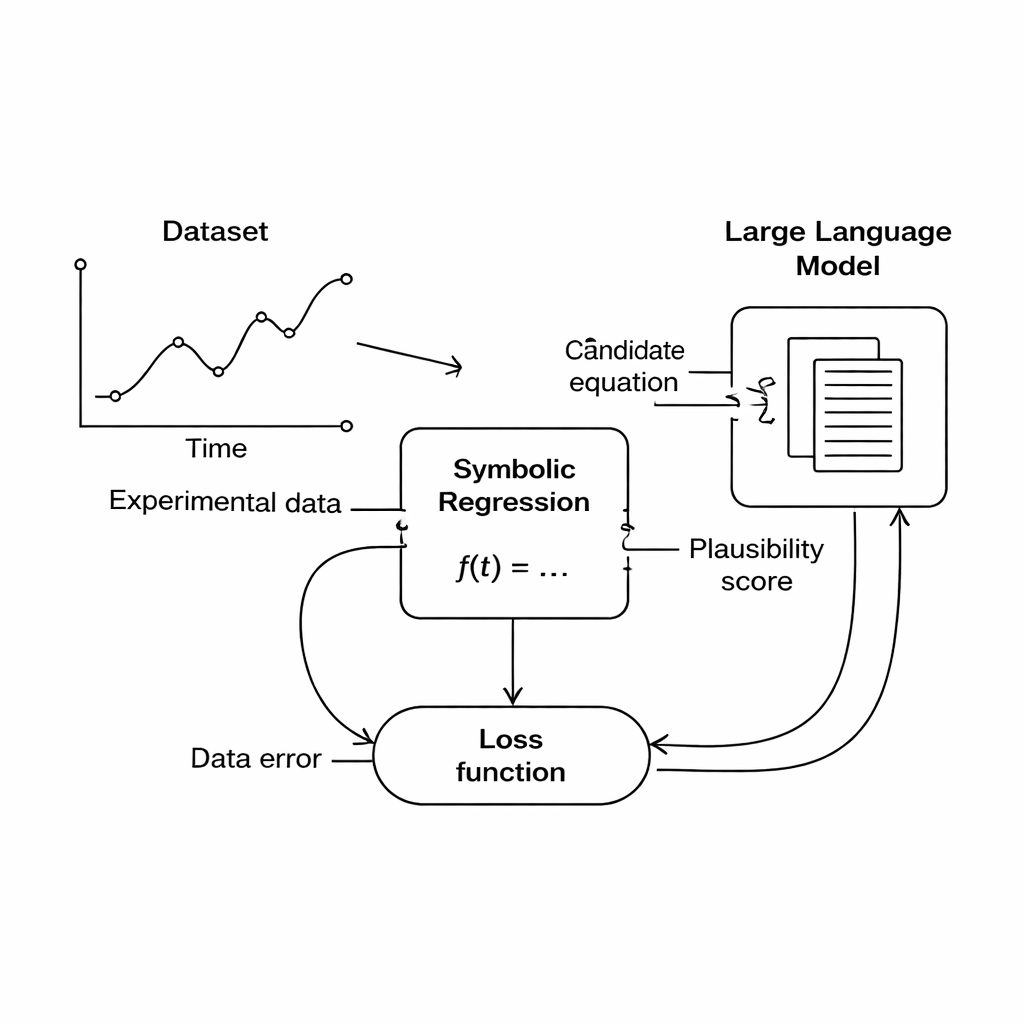
Cette étude propose une voie différente : au lieu de coder rigidement les règles du domaine, utiliser un grand modèle de langage (LLM) comme juge flexible de la plausibilité scientifique. Lors de la recherche, le moteur de régression symbolique produit des équations candidates qui correspondent aux données dans une certaine mesure. Chaque équation est alors traduite en texte et envoyée au LLM, accompagnée d’un court prompt décrivant les grandeurs impliquées et les contraintes physiques connues. Le LLM renvoie des scores sur trois aspects : si les unités de l’équation ont du sens, sa simplicité et si elle paraît physiquement réaliste. Ces scores sont intégrés dans la fonction objective principale, de sorte que l’ordinateur équilibre désormais « ajuste les données » et « ressemble à une bonne physique » lorsqu’il choisit quelles équations améliorer.
Mettre la méthode à l’épreuve
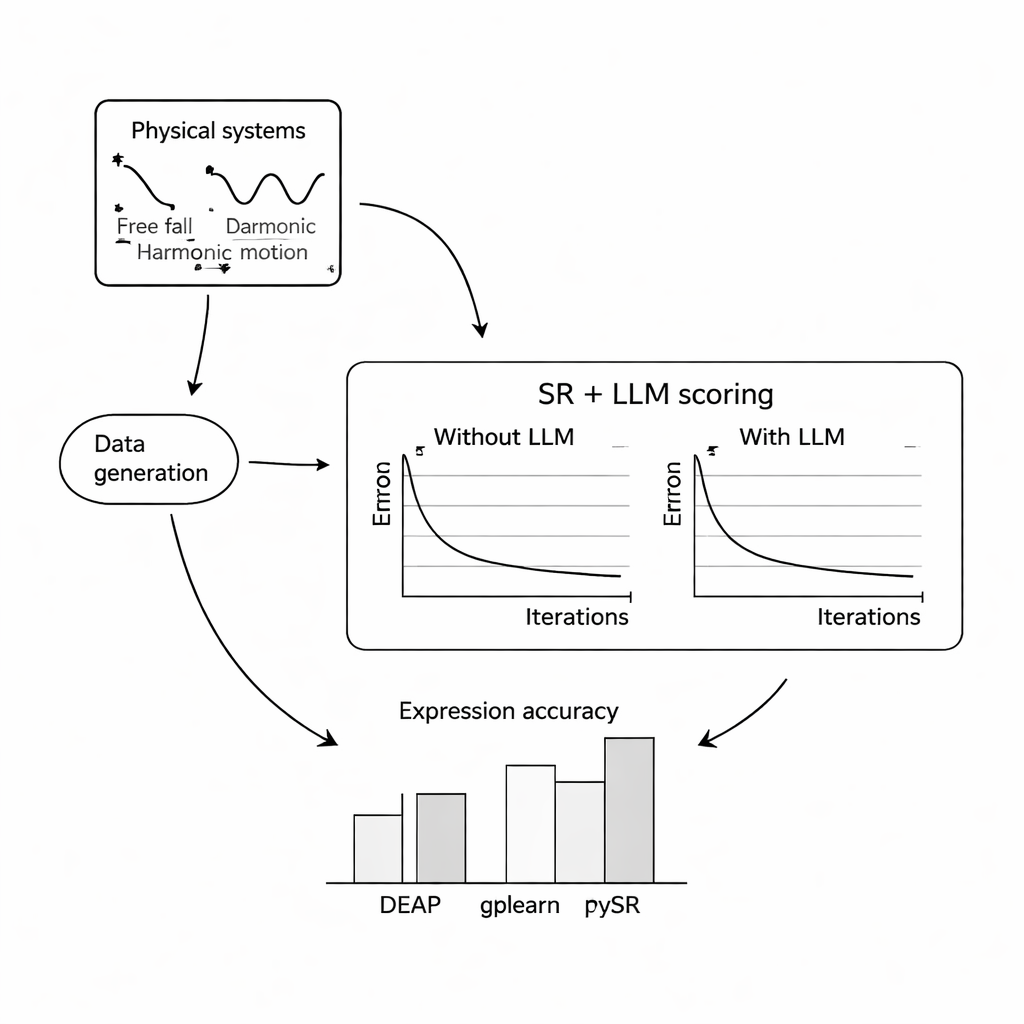
Pour évaluer l’efficacité de l’approche, les auteurs ont mené de vastes expériences informatiques sur trois problèmes classiques : la chute libre d’une balle sous gravité terrestre, le mouvement harmonique simple d’une masse sur un ressort, et une onde électromagnétique amortie. Pour chaque système, ils ont simulé des milliers de mesures bruitées dans des conditions variées, puis demandé à trois programmes populaires de régression symbolique de retrouver les équations sous-jacentes, avec ou sans l’aide d’un LLM. Ils ont testé trois modèles de langage compacts et open source — Mistral, Llama 2 et Falcon — et exploré comment différents designs de prompts, du contexte minimal à la description complète voire la formule exacte, modifiaient l’orientation donnée par le LLM. Dans la plupart des configurations, l’ajout du score du LLM a amélioré la concordance des équations retrouvées avec les lois connues et les a rendues plus robustes au bruit, la combinaison de PySR (une bibliothèque de régression symbolique) et Mistral donnant généralement les meilleurs résultats.
Quand les mots orientent les mathématiques
Une conclusion clé est que la formulation du prompt influence fortement les résultats. Lorsque les prompts comprenaient des descriptions claires des variables, de la nature de l’expérience et parfois la formule cible exacte, la recherche guidée par le LLM convergait plus sûrement vers la bonne structure. Dans ces cas plus riches, les équations découvertes étaient souvent structurellement identiques aux lois de référence, et pas seulement proches numériquement. Les auteurs ont aussi testé la tenue de l’approche face à des niveaux croissants de bruit aléatoire dans les mesures. Si toutes les méthodes se dégradaient à mesure que les données devenaient plus bruitées et que les équations sous-jacentes plus complexes, les versions augmentées par LLM perdaient généralement en précision plus lentement que leurs homologues standard, ce qui suggère que le sens de plausibilité du modèle de langage peut agir comme un facteur de stabilisation.
Ce que cela signifie pour les découvertes futures
Pour le grand public, le message principal est que l’IA basée sur le texte peut faire plus que rédiger des essais ou répondre à des questions — elle peut aussi guider d’autres algorithmes vers des équations scientifiques qui « semblent justes » au regard de nos connaissances actuelles de la nature. La méthode présentée ici ne garantit pas que chaque équation découverte soit correcte, et elle dépend toujours d’une supervision humaine et de prompts soigneusement conçus. Mais elle montre que les grands modèles de langage, entraînés sur des océans de textes scientifiques, peuvent servir de source réutilisable de connaissances de domaine, aidant les outils automatisés à passer d’un ajustement aveugle des données à la proposition de lois que les scientifiques peuvent interpréter, vérifier et exploiter.
Citation: Taskin, B., Xie, W. & Lazebnik, T. Knowledge integration for physics-informed symbolic regression using pre-trained large language models. Sci Rep 16, 1614 (2026). https://doi.org/10.1038/s41598-026-35327-6
Mots-clés: régression symbolique, IA informée par la physique, grands modèles de langage, découverte scientifique, apprentissage d’équations