Clear Sky Science · fr
Une approche d’apprentissage par renforcement profond pour l’analyse des mouvements de danse
Apprendre aux ordinateurs à regarder la danse comme nous
Du ballet au hip‑hop, la danse est remplie de déplacements subtils de rythme et de posture que l’œil humain perçoit instantanément — mais que les ordinateurs peinent à détecter. Cette étude présente une nouvelle façon pour l’intelligence artificielle de « regarder » des vidéos de danse de manière plus proche d’un expert humain, en passant rapidement sur les étapes routinières pour se concentrer sur de brefs moments révélateurs qui définissent chaque style. Le résultat est un système qui reconnaît les genres de danse avec plus de précision tout en visionnant beaucoup moins de vidéo, ce qui peut bénéficier aux archives numériques, aux technologies sportives et de divertissement.
Pourquoi les vidéos de danse sont difficiles pour les machines
À première vue, entraîner un ordinateur à reconnaître des styles de danse semble simple : fournir des vidéos et laisser l’apprentissage profond trouver des motifs. En réalité, la plupart des systèmes actuels gaspillent des ressources. Les modèles vidéo standard traitent soit chaque image, soit échantillonnent des segments à intervalles fixes, en supposant que tous les instants sont également importants. Or les styles de danse diffèrent souvent par de tout petits détails — la rotation d’un pied, le moment où un partenaire pivote, ou le timing d’une pirouette — plutôt que par un mouvement continu. Beaucoup d’images sont donc répétitives ou peu informatives, et les poses clés peuvent tomber entre des points d’échantillonnage fixes, entraînant des confusions entre, par exemple, une valse et un foxtrot.
Une façon plus intelligente de parcourir la vidéo
Les auteurs proposent un cadre appelé Reinforcement‑based Attentive Temporal Sampling, ou RATS, qui traite l’analyse vidéo comme une recherche active plutôt que comme un visionnage passif. Plutôt que d’avancer image par image, le système découpe la vidéo de danse en courts segments et convertit d’abord chaque segment en une description compacte du mouvement à l’aide d’un réseau de convolution 3D spécialisé. Ces résumés de mouvement sont ensuite stockés en mémoire. Par dessus cela, un agent décisionnel parcourt la séquence de segments, choisissant d’avancer par un petit saut, par un saut plus grand, ou de s’arrêter et d’émettre une prédiction de style. En pratique, le système apprend à naviguer dans le temps, s’attardant sur des motifs révélateurs et en sautant les passages moins utiles.
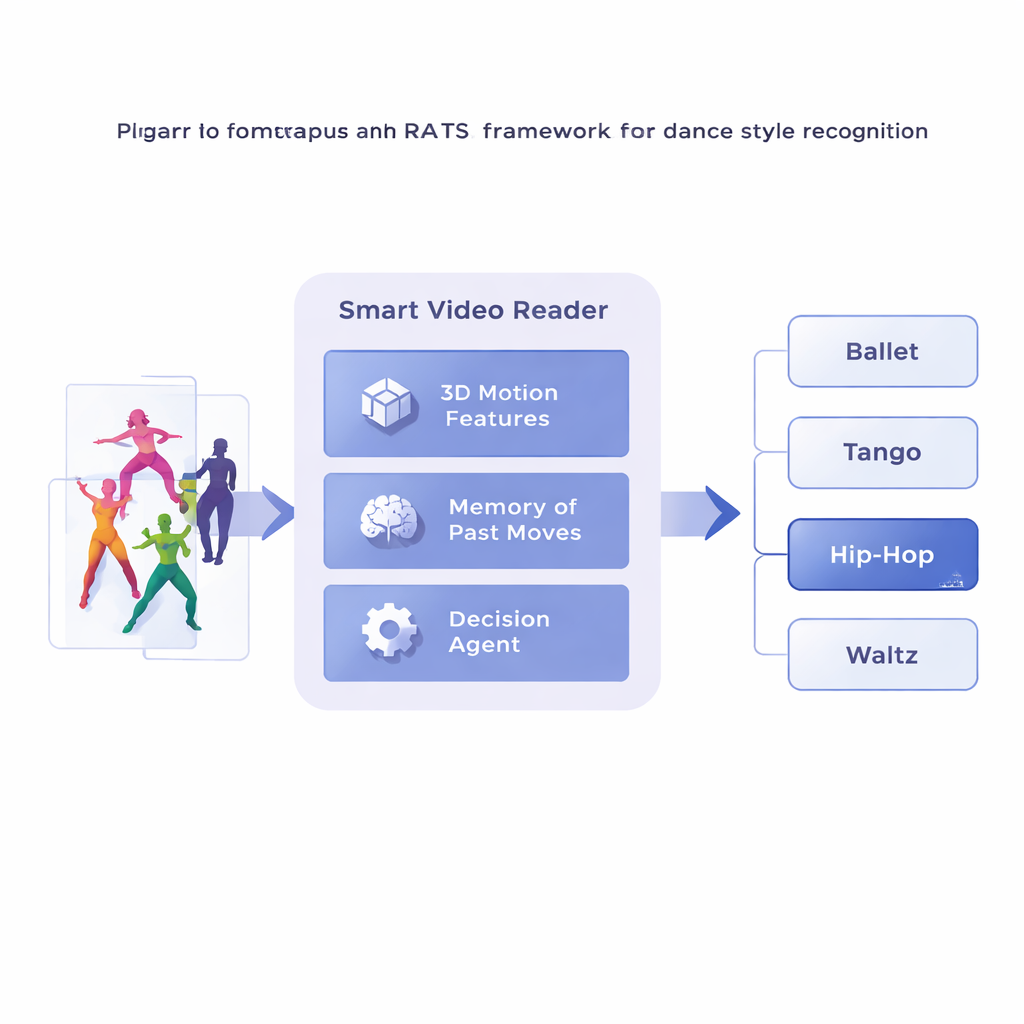
Apprendre quand regarder et quand décider
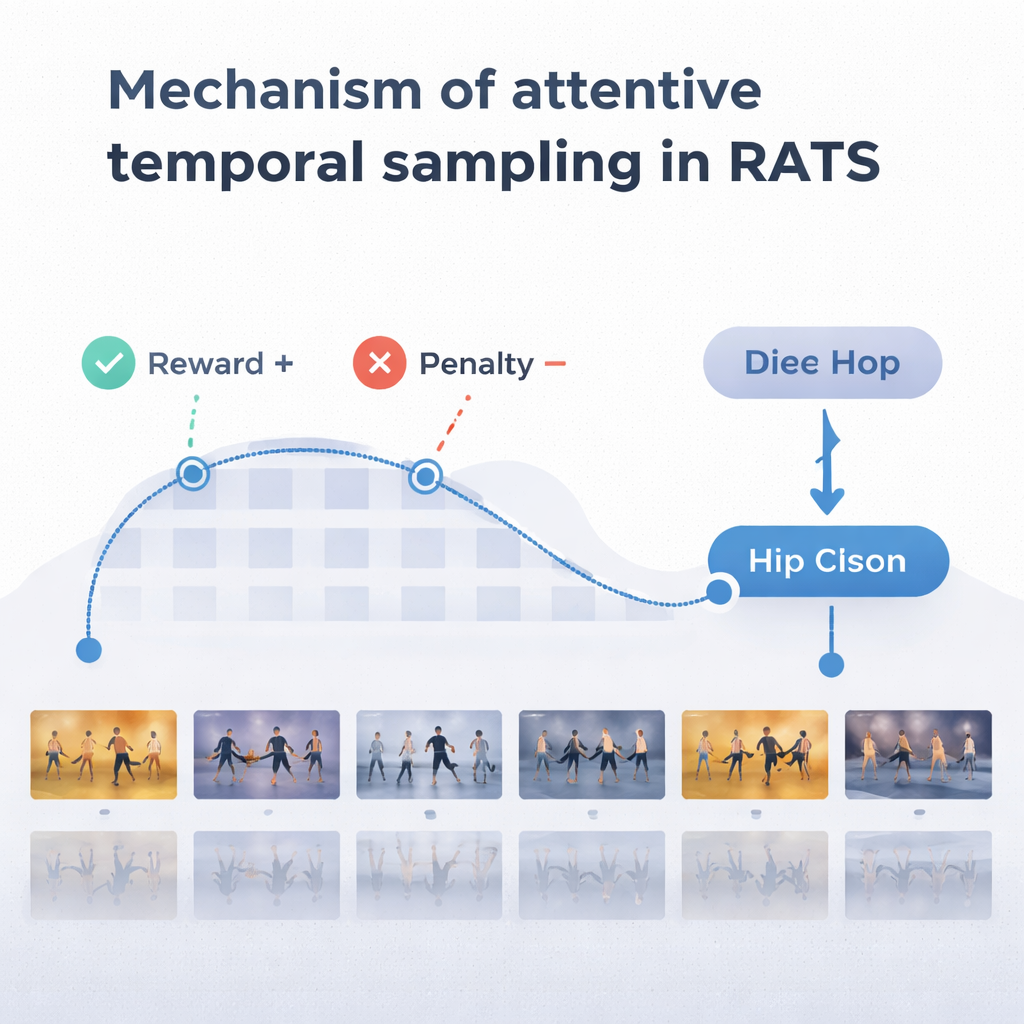
Pour prendre des décisions pertinentes, l’agent s’appuie sur une forme de mémoire inspirée de notre capacité à nous souvenir à la fois des mouvements passés et émergents. Un réseau récurrent bidirectionnel suit ce que le système a déjà « vu » et la façon dont les segments actuels se rapportent à cet historique. À chaque étape, l’agent pèse trois options : faire un petit bond pour inspecter des détails fins comme le jeu de jambes, effectuer un saut plus long pour passer un mouvement répétitif, ou s’arrêter et classer la danse. Le système est entraîné avec des récompenses et des pénalités : il gagne une forte récompense pour une décision correcte, une forte pénalité pour une décision erronée, et une petite pénalité à chaque saut. Cet équilibre encourage l’agent à être à la fois précis et efficace — attendre d’avoir suffisamment de preuves, sans parcourir toute la vidéo.
Des performances supérieures aux classificateurs conventionnels
L’équipe a testé RATS sur le jeu de données Let’s Dance, une collection difficile de 1 000 vidéos couvrant dix styles, du flamenco et du tango au swing et au square dancing. Comparé à plusieurs méthodes existantes, y compris des réseaux profonds standard et d’autres modèles spécialisés pour la danse, RATS a atteint la meilleure précision — environ 92 % — et le meilleur équilibre global entre précision et rappel. Il s’est également montré statistiquement supérieur à des concurrents solides, et pas seulement légèrement différent par hasard. Fait important, le système a obtenu ces résultats en analysant en moyenne seulement environ 38 % des images vidéo. L’échantillonnage uniforme toutes les quelques images était plus rapide mais manquait des moments cruciaux et faisait chuter la performance ; traiter chaque image était plus lent et restait moins précis que l’approche ciblée.
Ce que cela signifie au‑delà de la piste de danse
Pour un non‑spécialiste, le message central est simple : les ordinateurs peuvent mieux faire quand ils apprennent à être des spectateurs sélectifs. En apprenant à une IA à se concentrer sur des « moments d’or » dans le temps, ce travail montre que les machines peuvent reconnaître des mouvements humains complexes plus précisément tout en consommant moins de ressources. Bien que l’étude porte sur la danse, la même idée pourrait aider des systèmes à repérer des éléments clés dans des routines sportives, des vidéos de surveillance, ou toute longue vidéo où les événements importants sont brefs et dispersés. Autrement dit, regarder de manière plus intelligente — et non plus regarder — pourrait être l’avenir de la compréhension vidéo.
Citation: Yin, P., Li, X. A deep reinforcement learning approach to dance movement analysis. Sci Rep 16, 5541 (2026). https://doi.org/10.1038/s41598-026-35311-0
Mots-clés: reconnaissance de la danse, analyse vidéo, apprentissage profond, apprentissage par renforcement, mouvement humain