Clear Sky Science · fr
Ségrégation et classification automatiques basées sur l’apprentissage profond pour la détection du cancer du col de l’utérus en utilisant un U‑Net amélioré et des méthodes d’ensemble
Pourquoi les tests de Pap ont encore besoin d’un coup de pouce numérique
Le cancer du col de l’utérus est l’un des rares cancers très évitables lorsqu’il est détecté précocement, et pourtant de nombreuses femmes meurent encore parce que des altérations cellulaires dangereuses sont manquées ou trouvées trop tard. Le test de Pap familier sauve déjà des vies, mais examiner des milliers d’images cellulaires à l’œil nu est un travail lent et fatigant, et même les experts peuvent être en désaccord. Cet article explore comment l’intelligence artificielle moderne peut agir en tant qu’assistant infatigable, détectant et triant automatiquement les cellules cervicales sur les images de frottis de Pap pour aider les médecins à repérer les signes avant-coureurs plus rapidement et de façon plus fiable.
Apprendre aux ordinateurs à repérer les cellules problématiques
Les chercheurs se sont donné pour objectif de construire un système informatique capable d’accomplir deux tâches clés : d’abord, extraire chaque cellule cervicale de l’arrière‑plan d’une image de frottis de Pap, puis décider si la cellule paraît normale ou présente des signes associés au cancer. Pour cela, ils ont utilisé l’apprentissage profond, une forme d’IA qui apprend des motifs directement à partir d’un grand nombre d’images d’exemple plutôt que d’après des règles écrites à la main. Leur système se concentre sur la cellule entière — à la fois le noyau sombre et le matériau environnant (cytoplasme) — car des modifications de taille, de forme et de texture sur l’ensemble de la cellule peuvent indiquer une maladie.
Une manière plus intelligente de délimiter les cellules
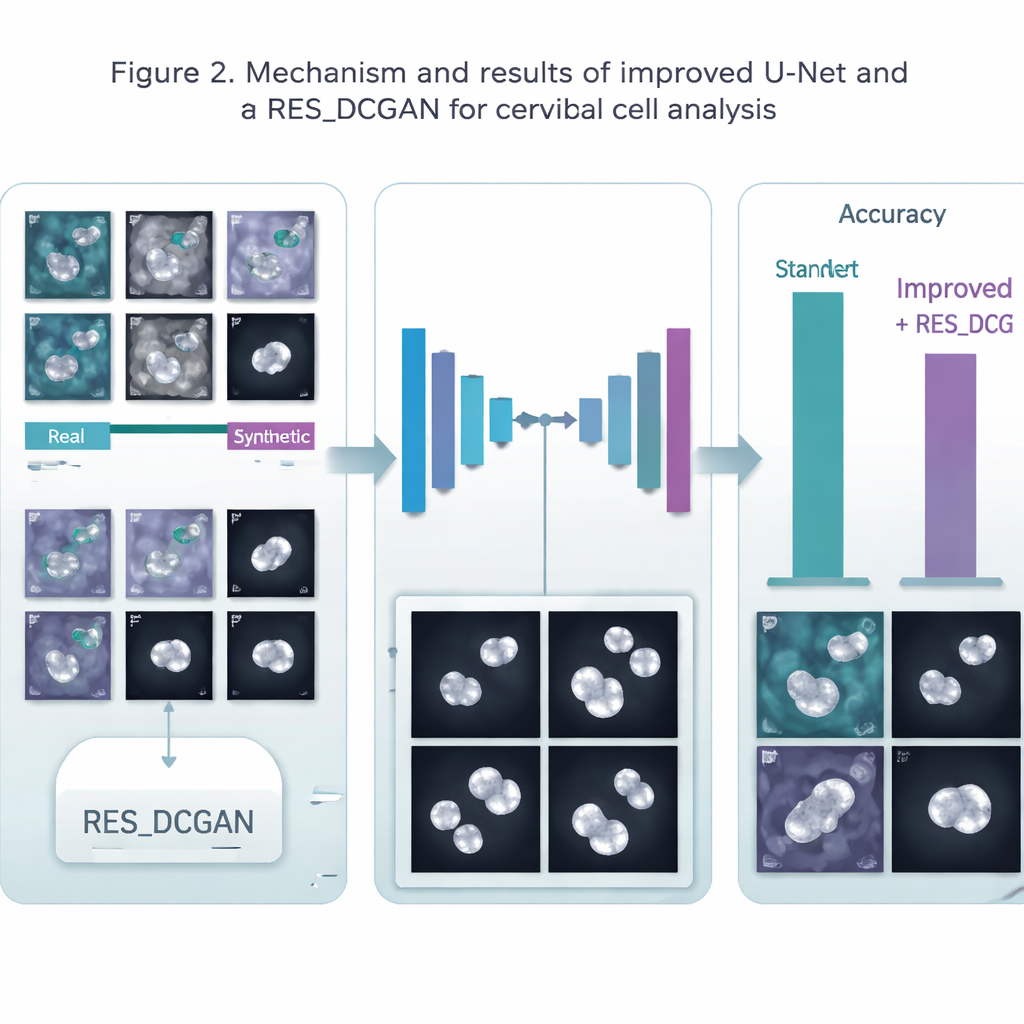
Au cœur du système se trouve une version améliorée d’un modèle d’imagerie médicale populaire appelé U‑Net, particulièrement performant pour tracer des contours précis autour d’objets dans les images. Les auteurs ont modifié l’U‑Net pour qu’il puisse examiner les détails de l’image à plusieurs échelles à la fois et rester stable même lorsqu’il est entraîné sur de petits lots de données, une limitation fréquente en milieu médical. Ce réseau amélioré apprend à peindre un masque simple sur chaque image : blanc là où une cellule est présente, noir pour l’arrière‑plan. En isolant uniquement les zones cellulaires, les étapes ultérieures du pipeline peuvent se concentrer sur l’essentiel plutôt que d’être distraites par des colorations, des débris ou des zones vides.
Créer plus d’exemples d’entraînement à partir de rien
Un défi majeur en médecine est que les images étiquetées de haute qualité sont rares et coûteuses à obtenir. Pour y remédier, l’équipe a utilisé un modèle génératif appelé RES_DCGAN, qui apprend à créer des images de frottis de Pap synthétiques réalistes à partir des images réelles. Ces images supplémentaires « fabriquées mais convaincantes » sont intégrées au processus d’entraînement, à la fois avant l’étape de segmentation des cellules et ensuite lors de l’étape de classification. En voyant beaucoup plus de variations de cellules — y compris des motifs rares et subtils — l’IA devient plus robuste et a moins tendance à sur‑adapter un petit ensemble de patients ou des conditions d’imagerie particulières.
Des contours aux alertes précoces
Une fois les cellules segmentées, un second groupe de modèles d’apprentissage profond prend le relais pour classer chaque cellule comme normale ou appartenant à différentes catégories anormales. Les auteurs ont utilisé un modèle de reconnaissance d’images performant appelé ResNet50V2 et l’ont combiné avec plusieurs autres réseaux bien connus dans un « ensemble », où plusieurs modèles votent ensemble pour la décision finale. Ils ont testé six pipelines différents sur trois jeux de données provenant de Pologne (Pomeranian), du Danemark (Herlev) et de Grèce (SIPaKMeD), couvrant à la fois des cas simples normale vs anormale et des problèmes multi‑classes plus détaillés. Dans ces tests, la segmentation des cellules en amont a systématiquement amélioré la précision de classification, et l’ajout d’images synthétiques a généralement encore rehaussé les performances, en particulier pour le tracé des contours cellulaires.
Quelle a été la performance de l’assistant numérique ?
Le système a atteint des scores très élevés. Pour le tracé des contours cellulaires, la précision a atteint environ 99,5 % sur un jeu de données et autour de 98 % sur un autre, surpassant largement un U‑Net standard. Pour la détermination du type cellulaire, l’ensemble de modèles a correctement étiqueté environ 95–96 % des cellules dans les tâches les plus complexes et jusqu’à 99 % dans les décisions binaires plus simples sur le risque de cancer. Ces résultats égalent ou dépassent de nombreuses études antérieures, tout en montrant qu’un pipeline unifié peut fonctionner à travers différents laboratoires et sources de données. Les gains ont été plus modestes sur un jeu de données particulièrement hétérogène, soulignant que la diversité du monde réel reste un défi.
Ce que cela signifie pour les patientes et les médecins
Concrètement, ce travail montre qu’un assistant IA peut apprendre à tracer soigneusement les cellules cervicales et à les classer par niveau de risque avec une remarquable régularité. Il ne remplace pas le pathologiste, mais il peut pré‑dépister les lames, mettre en évidence les cellules suspectes et réduire le risque que des signes précoces soient négligés dans des cliniques surchargées ou dans des régions où les spécialistes sont peu nombreux. Avec des tests supplémentaires sur des échantillons plus grands et plus complexes et des masques validés par des experts, des systèmes de ce type pourraient aider à rendre le dépistage fiable du cancer du col de l’utérus accessible à davantage de femmes dans le monde, détectant plus tôt les changements dangereux et améliorant les chances d’un traitement réussi.
Citation: Wubineh, B.Z., Rusiecki, A. & Halawa, K. Deep learning-based automatic segmentation and classification for cervical cancer detection using an improved U-Net and ensemble methods. Sci Rep 16, 5184 (2026). https://doi.org/10.1038/s41598-026-35299-7
Mots-clés: dépistage du cancer du col de l’utérus, images de frottis de Pap, apprentissage profond, segmentation d’images médicales, diagnostic assisté par ordinateur