Clear Sky Science · fr
Modèle d'extraction de relations spatiales en chinois intégrant des caractéristiques sémantiques géographiques
Apprendre aux ordinateurs à comprendre où se trouvent les lieux
Chaque jour, nous décrivons des emplacements avec des phrases simples : une ville se trouve au sud d'une rivière, un parc est près d'une université, une autoroute traverse une province. Transformer ce type de langage courant en connaissance numérique précise est essentiel pour les cartes intelligentes, les applications de navigation et la recherche géographique. Cet article présente une nouvelle méthode, nommée PURE‑CHS‑Attn, qui aide les ordinateurs à lire des textes en chinois et à déterminer automatiquement les relations spatiales entre lieux avec une précision supérieure à celle des approches précédentes.
Pourquoi le langage spatial est important
Les relations spatiales sont des mots et des expressions qui indiquent comment les lieux sont reliés dans l'espace, comme « à l'intérieur », « à côté de », « au nord de » ou « à 30 kilomètres de ». Elles forment un pont entre le monde réel que l'on voit sur les cartes et les concepts que nous utilisons mentalement. Dans les systèmes d'information géographique (SIG), ces relations sous-tendent l'organisation, la recherche et l'analyse des données. Elles jouent aussi un rôle central dans d'autres domaines : par exemple, la combinaison d'images satellites, le suivi de mouvements dans des vidéos, la planification d'implantations industrielles ou l'étude de l'influence du climat et des formes du relief sur la biodiversité. Comme une grande partie de cette information est rédigée en langage naturel, disposer d'outils fiables capables de lire des textes et d'extraire automatiquement les relations spatiales devient de plus en plus important.
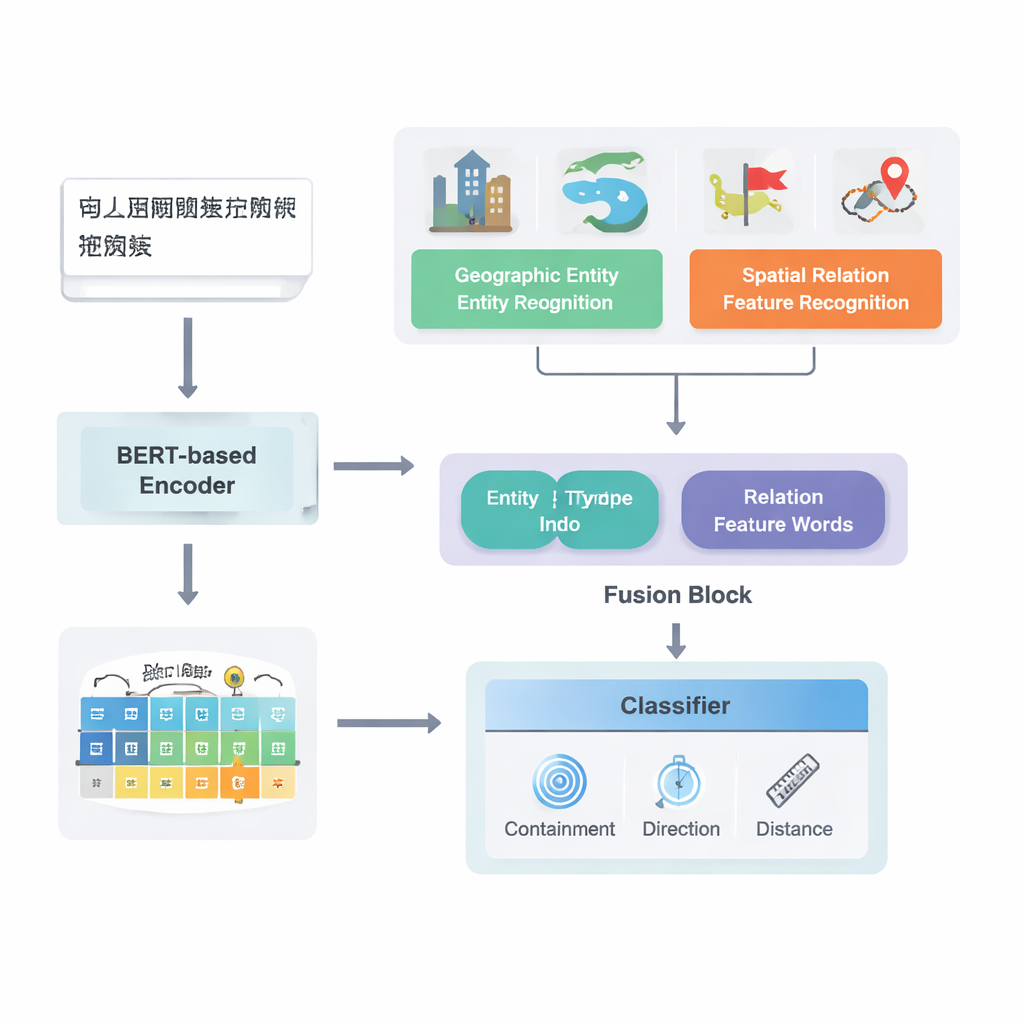
Du texte brut aux relations cartographiées
Les auteurs se concentrent sur les textes en chinois et s'appuient sur un solide modèle de pipeline d'apprentissage profond existant connu sous le nom de PURE. Leur modèle amélioré, PURE‑CHS‑Attn, fonctionne en plusieurs étapes. D'abord, il analyse les phrases pour repérer les entités géographiques telles que montagnes, rivières, villes et divisions administratives, en étiquetant chacune selon son type (par exemple, surface terrestre, plan d'eau, équipement public, site historique ou division administrative). Ensuite, il détecte les « mots‑caractéristiques » de relation spatiale comme « borde », « traverse », « au sud de » ou « près de », qui signalent comment deux lieux sont reliés. Un puissant modèle de langage, BERT‑wwm‑ext, convertit les caractères de chaque phrase en vecteurs numériques qui capturent leur sens et leur contexte. Ces vecteurs alimentent des composants séparés qui reconnaissent les entités et les mots de relation, puis transmettent leurs résultats à un module de fusion.
Mélanger connaissance humaine et apprentissage automatique
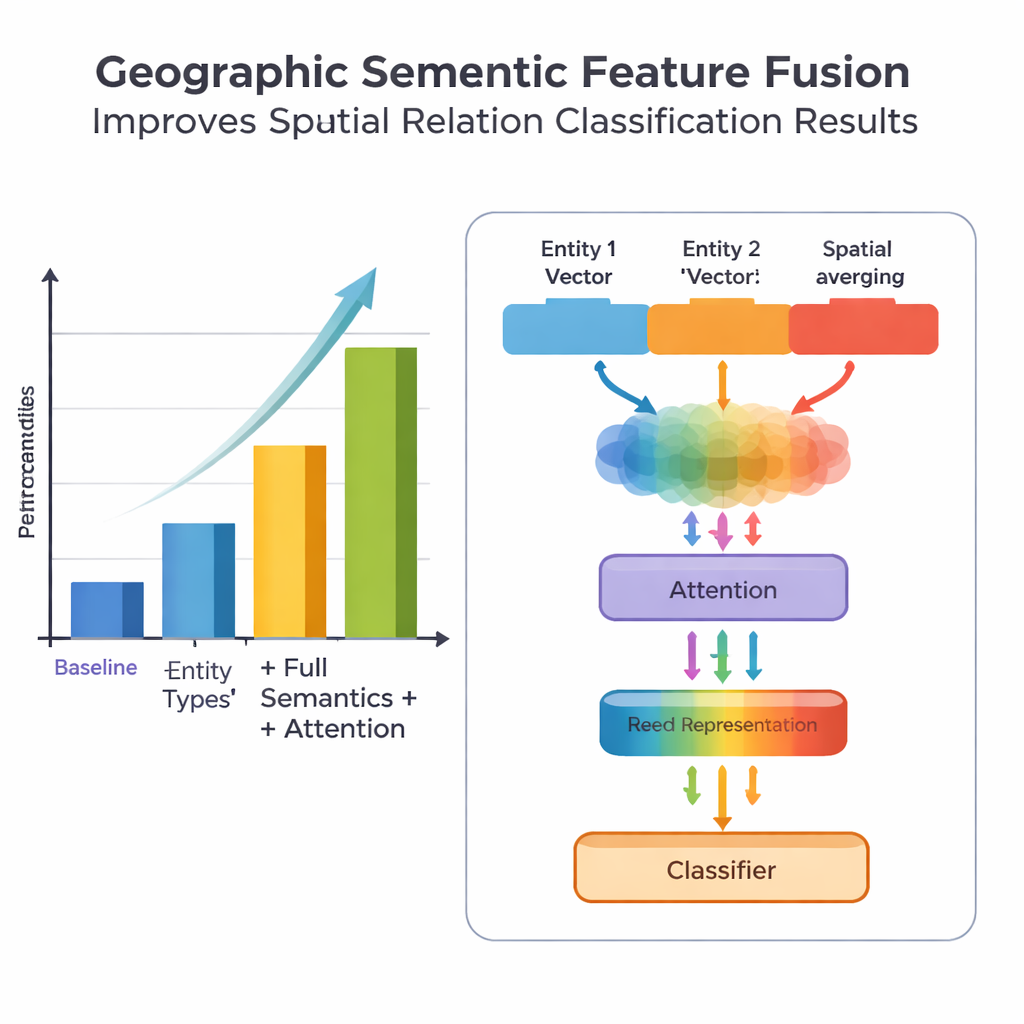
Une nouveauté clé de ce travail réside dans la manière dont il fusionne la connaissance géographique avec les motifs textuels appris. Plutôt que de traiter chaque mot de manière égale, le modèle exploite deux types d'informations sémantiques que les humains utilisent naturellement : le type de chaque entité géographique et les mots‑caractéristiques spatiaux qui les relient. Le module de fusion combine d'abord les vecteurs des deux entités en utilisant des poids dépendant de la fréquence avec laquelle différents types de lieux (par exemple deux divisions administratives versus une rivière et un comté) participent à différents types de relations. Il incorpore ensuite les vecteurs des mots‑caractéristiques spatiaux. Au‑dessus de cette « fusion de base », les auteurs ajoutent un mécanisme d'attention qui permet au modèle de se concentrer dynamiquement sur les portions les plus informatives de la combinaison entité–mot. La représentation finale fusionnée est transmise à un classificateur, qui peut attribuer un ou plusieurs types de relation — topologique (comme inclusion ou adjacency), directionnelle (nord, sud, etc.) ou basée sur la distance — entre chaque paire de lieux dans la phrase.
Mettre le modèle à l'épreuve
Pour évaluer leur approche, l'équipe a constitué et annoté avec soin un jeu de données tiré de l'Encyclopedia of China: Chinese Geography, contenant 1381 phrases et 368 paires de relations spatiales. Ils ont comparé plusieurs versions du modèle : un point de référence n'utilisant que des informations de localisation grossières, une version avec des types d'entités plus fins, une version ajoutant aussi les mots‑caractéristiques spatiaux, et leur modèle complet PURE‑CHS‑Attn avec la nouvelle conception de fusion et d'attention. Selon les métriques standards de précision, rappel et F1, PURE‑CHS‑Attn a amélioré la performance d'environ 7 % en précision, 6,5 % en rappel et 6,7 % en F1 par rapport au point de référence. Il s'est montré particulièrement performant pour reconnaître les relations topologiques et directionnelles, et a mieux géré les types de relations rares (« few‑shot ») que des modèles plus simples. Comparé à trois systèmes récents de pointe, y compris un basé sur de grands modèles de langage, PURE‑CHS‑Attn se classe en deuxième position de peu tout en restant beaucoup plus léger et facile à déployer.
Défis et voies futures
Malgré ces progrès, le modèle rencontre encore des difficultés avec les relations de distance, surtout lorsqu'il n'existe que quelques exemples d'entraînement. Les auteurs montrent que leur jeu de données contient très peu de tels cas, ce qui limite ce que toute méthode gourmande en données peut apprendre. Ils notent également que la simple moyenne de nombreux mots‑caractéristiques spatiaux dans une phrase peut introduire du bruit, que leur mécanisme d'attention atténue mais ne résout pas entièrement. Pour l'avenir, ils proposent deux pistes prometteuses : élargir et équilibrer les données d'entraînement via l'augmentation, et combiner leur fusion sémantique géographique avec des techniques issues des grands modèles de langage et de l'apprentissage par incitation (prompting) pour améliorer encore les performances dans les scénarios peu fournis en données tout en conservant l'efficacité du système.
Ce que cela signifie pour la cartographie au quotidien
En termes simples, cette recherche apprend aux ordinateurs à lire les descriptions spatiales en chinois de manière plus humaine, en prêtant attention aux types de lieux mentionnés et à la formulation exacte des relations. Le modèle PURE‑CHS‑Attn montre que le mélange de connaissances géographiques structurées et d'apprentissage profond moderne conduit à une extraction plus précise et plus robuste du « qui est où, par rapport à quoi » à partir des textes. Cela ouvre la voie à des systèmes SIG plus intelligents et automatisés, à des graphes de connaissances géographiques plus riches et à de meilleurs outils pour explorer la manière dont l'espace est décrit en science, en politique et dans la communication quotidienne.
Citation: Ye, P., Wang, Y., Jiang, Y. et al. Chinese spatial relation extraction model by integrating geographic semantic features. Sci Rep 16, 5537 (2026). https://doi.org/10.1038/s41598-026-35282-2
Mots-clés: extraction de relations spatiales, IA géospatiale, sémantique géographique, exploration de textes chinois, automatisation SIG