Clear Sky Science · fr
Approche par apprentissage automatique pour l’identification des variétés de blé à partir d’images de graines isolées
Pourquoi un tri des semences plus intelligent est important
Pour les agriculteurs et les semenciers, distinguer une variété de blé d’une autre est crucial. Planter le mauvais type peut entraîner des rendements plus faibles, une moindre résistance aux maladies et des cultures inadaptées au sol ou au climat locaux. Pourtant, à l’œil nu, les différentes variétés de blé semblent presque identiques. Cette étude explore comment l’intelligence artificielle et des photographies numériques de graines isolées peuvent distinguer de manière fiable des variétés étroitement apparentées, ouvrant la voie à un contrôle de la qualité des semences plus rapide, moins coûteux et plus objectif.
De l’évaluation experte aux contrôles par caméra
Aujourd’hui, de nombreux systèmes d’inspection des semences reposent encore sur des experts humains qui jugent visuellement la variété et la pureté des graines. Ce processus est lent, coûteux et sujet aux divergences d’avis, surtout parce que de nombreux cultivars de blé ne diffèrent que par des variations subtiles de forme ou de motif de surface. Les auteurs ont cherché à remplacer cette approche subjective par un système automatisé utilisant des images de grains individuels prises dans une petite boîte à illumination contrôlée. En standardisant soigneusement l’éclairage, la distance et la couleur de fond, ils ont créé un registre visuel net de six variétés de blé iraniennes courantes, générant des dizaines de milliers de photos de graines pour entraîner et tester les modèles informatiques.
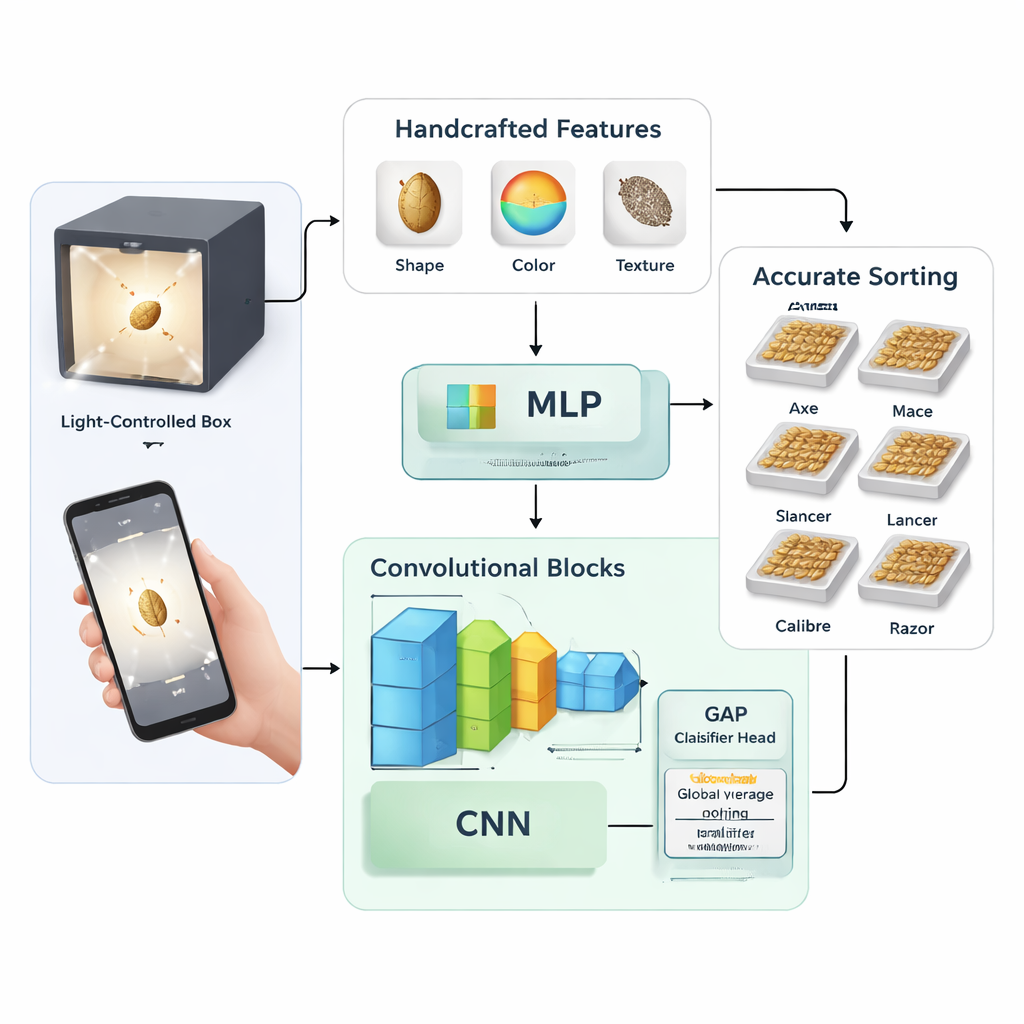
Deux façons d’apprendre à une machine à voir les graines
L’étude compare deux grandes stratégies pour apprendre à une machine à reconnaître les variétés de blé. Dans la première, les chercheurs ont extrait manuellement 58 mesures numériques de chaque image de graine, incluant des caractéristiques de forme basiques (comme la longueur et la surface), des statistiques de couleur dans différents espaces colorimétriques et des motifs de texture. Ils ont ensuite utilisé une technique appelée analyse en composantes principales pour condenser ces mesures en 27 caractéristiques clés, qui ont été injectées dans un réseau de neurones traditionnel appelé perceptron multicouche. Dans la seconde stratégie, ils ont évité la conception manuelle de caractéristiques et entraîné des réseaux de neurones convolutionnels—des modèles d’IA spécialisés pour les images—afin qu’ils apprennent directement des motifs utiles à partir des pixels bruts.
Construire un modèle d’apprentissage profond léger mais puissant
L’approche par apprentissage profond a été testée sous plusieurs formes. Les auteurs ont conçu leur propre réseau relativement compact avec deux à quatre blocs convolutionnels empilés et ont expérimenté différents réglages d’entraînement, tels que les taux d’apprentissage, les niveaux de dropout et les tailles de lot. Ils ont également comparé deux façons de terminer le réseau : une couche « entièrement connectée » classique versus une méthode plus compacte appelée global average pooling, qui remplace de larges couches denses par une simple moyenne avant la classification finale. Pour mettre les résultats en perspective, ils ont affiné deux architectures lourdes et largement utilisées—Inception-ResNet-v2 et EfficientNet-B4—sur le même jeu de données de blé afin de comparer un petit modèle sur mesure à des réseaux profonds polyvalents.
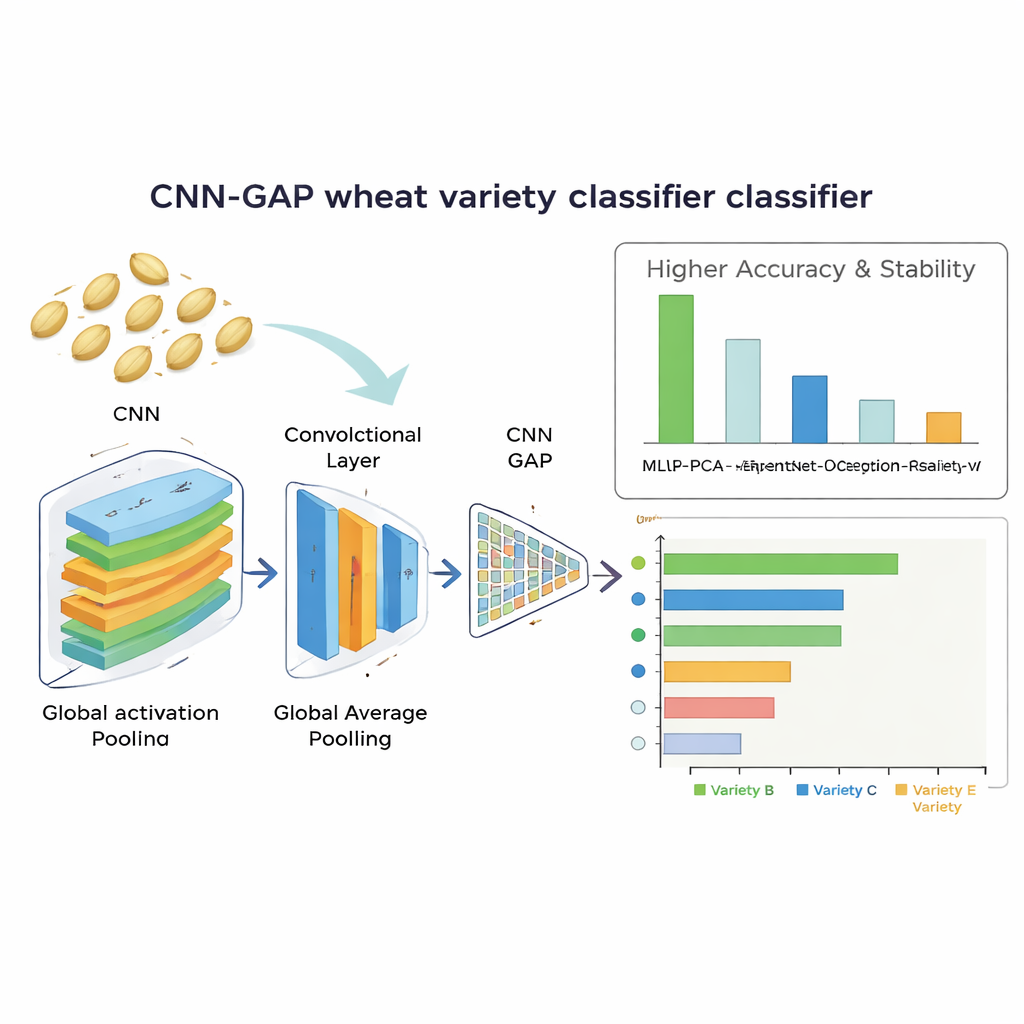
Quelle est la performance du système sur les grains
Le meilleur performer fut le réseau convolutionnel conçu sur mesure utilisant le global average pooling. Il a identifié correctement les variétés de blé à environ 92 % et a présenté des résultats très stables sur des entraînements répétés. Ce modèle a non seulement surpassé les grands réseaux pré-entraînés, mais a aussi devancé l’approche basée sur des caractéristiques extraites manuellement, qui atteignait environ 86 % d’exactitude après réduction de dimensionnalité. L’analyse des erreurs de confusion a montré que le modèle léger séparait particulièrement bien des variétés aux apparences très similaires, tandis que les modèles profonds en transfert d’apprentissage avaient tendance à surajuster sur ce jeu de données limité. Fait important, le réseau gagnant était efficace : il traitait chaque image de graine en environ 13,6 millisecondes et ne contenait qu’environ 2,1 millions de paramètres ajustables, le rendant réaliste pour une utilisation dans des équipements de tri en temps réel et à faible coût.
Limites, usage réel et perspectives
Lorsqu’on a testé le même modèle sur une culture entièrement différente—des graines de pois chiche—son exactitude a chuté nettement, révélant qu’un système réglé sur des différences fines entre grains de blé ne se généralise pas automatiquement à d’autres espèces. De même, parce que toutes les images d’entraînement provenaient d’une chambre contrôlée, les performances peuvent décliner sous un éclairage de plein champ variable ou avec des grains partiellement masqués. Malgré cela, ce travail montre qu’un modèle d’apprentissage profond compact et bien conçu, alimenté par des images standardisées de graines isolées, peut distinguer de manière fiable des variétés de blé presque indiscernables à l’œil. Avec des données d’entraînement plus larges et des conditions d’imagerie plus variées, des systèmes similaires pourraient devenir des outils pratiques pour la certification automatisée des semences, aidant les agriculteurs à obtenir des lots de semences plus purs et des récoltes plus prévisibles.
Citation: Bagherpour, H., Shamohammadi, S. Machine learning approach for wheat variety identification using single-seed imaging. Sci Rep 16, 6472 (2026). https://doi.org/10.1038/s41598-026-35252-8
Mots-clés: graines de blé, apprentissage profond, classification par image, qualité des semences, agriculture de précision