Clear Sky Science · fr
Évaluation de la précision des données nucléaires apprises par machine dans les analyses Monte Carlo neutronics et d’efficacité informatique pour des cœurs de réacteur complets
Pourquoi des simulations de réacteur plus rapides comptent
Les centrales nucléaires s’appuient sur des modèles informatiques détaillés pour prévoir le comportement du combustible sur des mois et des années d’exploitation. Ces modèles sont cruciaux pour la sûreté, l’efficacité et la conception de nouveaux réacteurs, mais ils sont notoirement lents et gourmands en mémoire. Cet article examine si l’apprentissage automatique peut réduire l’envergure des gigantesques tables de données nucléaires qui pilotent ces simulations — diminuant fortement le coût informatique — sans compromettre la précision physique sur laquelle s’appuient les ingénieurs.
Réduire les données derrière la physique
Chaque fois qu’un neutron simulé se déplace dans un cœur de réacteur virtuel, le code consulte de grandes tables qui décrivent la probabilité qu’il soit diffusé, absorbé ou qu’il provoque une fission. Ces tables, appelées bibliothèques de données nucléaires, encodent des probabilités sur des milliers de points d’énergie pour de nombreux isotopes présents dans le combustible et ses produits de fission. Les auteurs s’appuient sur une méthode d’apprentissage automatique antérieure qui « amincit » ces tables : elle supprime des points d’énergie redondants tout en préservant les caractéristiques nettes telles que les seuils de réaction et les pics de résonance, où les probabilités varient rapidement. Plutôt que de régénérer les données via une longue chaîne de traitement traditionnelle, la méthode édite directement les fichiers HDF5 natifs d’OpenMC, ne conservant qu’environ 10 à 50 % des points de grille d’origine pour 23 nuclides particulièrement importants.
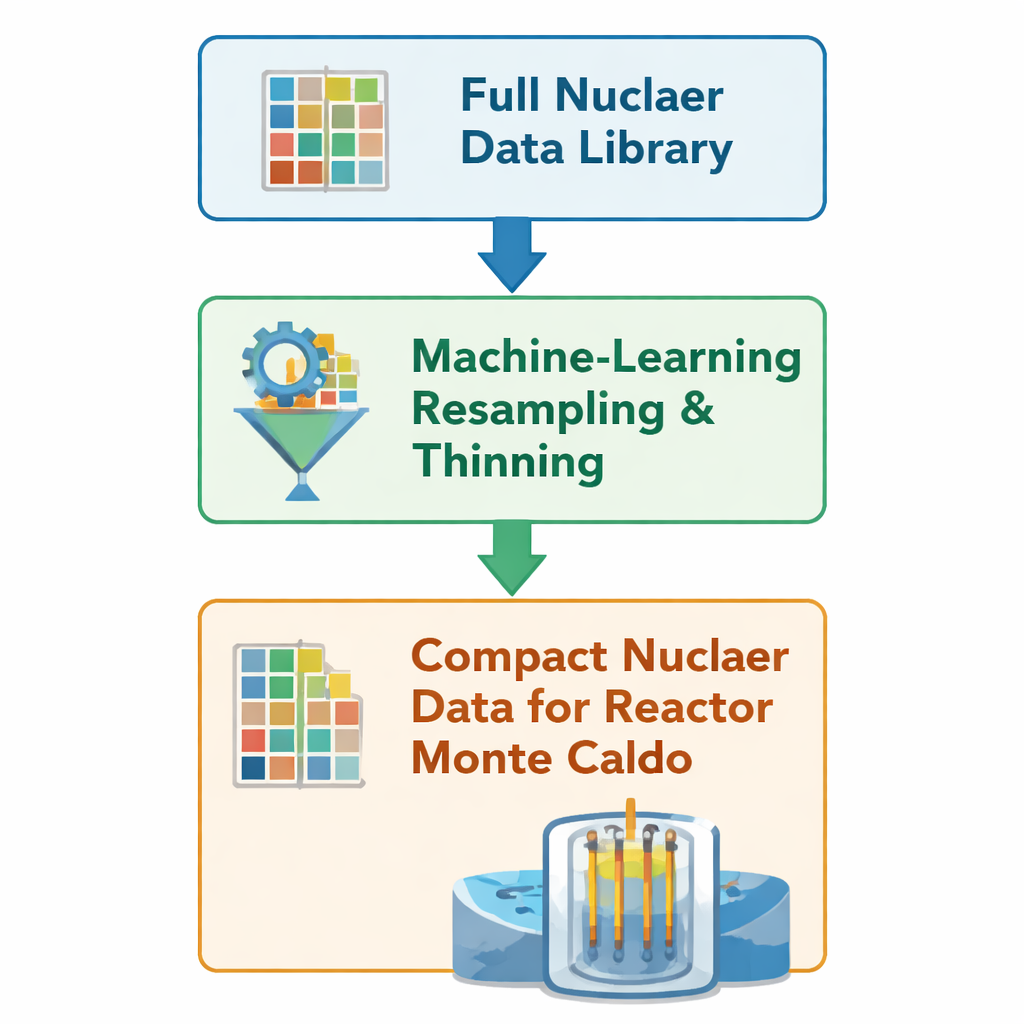
Tester l’idée sur des cœurs de réacteur complets
Pour vérifier si ces données allégées produisent encore des résultats fiables dans des configurations réalistes, l’équipe exécute des simulations d’un an sur deux grands réacteurs à eau sous pression : un European Pressurized Reactor (EPR) et un VVER‑1000, en utilisant le code Monte Carlo open source OpenMC. Pour chaque cœur, ils réalisent deux campagnes par ailleurs identiques : l’une avec la bibliothèque complète et l’autre avec la version amincie par apprentissage automatique. Toute la géométrie, les conditions d’exploitation et les paramètres numériques sont maintenus constants ; seules diffèrent les tables de données derrière la physique. Ils désactivent d’autres fonctionnalités d’accélération dans OpenMC afin que toute variation de vitesse ou de mémoire puisse être attribuée directement aux données réduites, et non à des changements d’algorithmes ou de réglages.
Gains de vitesse avec des marges d’erreur serrées
Le gain est substantiel. Pour le cas EPR, le temps d’exécution total diminue d’environ 18 %, et pour le VVER‑1000 la durée d’exécution se réduit d’environ 43 %. L’utilisation mémoire évolue de façon plus modeste : l’usage maximal baisse d’environ 4 % pour l’EPR et augmente d’environ 5 % pour le VVER‑1000, reflétant des différences dans la proportion de temps que chaque modèle consacre à la consultation des données nucléaires par rapport au suivi des trajectoires de particules dans la géométrie. Surtout, les principales mesures au niveau du réacteur restent très proches des valeurs d’origine. Sur une année complète dans le VVER‑1000, le facteur de multiplication effectif — en substance, le nombre moyen de neutrons produits par fission — ne dévie jamais de plus d’environ 100 parties par million, et typiquement de seulement quelques dizaines de parties par million. Pour des canaux de réaction clés comme la fission de l’uranium‑235 et de l’uranium‑238 et la capture de neutrons par le xénon‑135 et le samarium‑149, les différences moyennes restent bien en dessous d’un dixième de pour cent.
L’évolution du combustible et les poisons restent alignés
Parce que le comportement à long terme d’un réacteur dépend non seulement des réactions instantanées mais aussi de l’accumulation et de l’épuisement des produits de fission, les auteurs suivent aussi les inventaires évolutifs des isotopes importants. Ils examinent les principaux isotopes d’uranium, une famille d’isotopes de plutonium issus de la transmutation de l’uranium‑238, et des nuclides « poisons » puissants qui absorbent les neutrons, en particulier le xénon‑135 et le samarium‑149. Même après un an complet, les différences d’inventaire entre les cas avec données complètes et réduites sont minimes : de l’ordre de quelques centièmes de pour cent pour le xénon et le samarium, et généralement inférieures à un dixième de pour cent pour les espèces de plutonium. L’uranium‑235 et l’uranium‑238, qui dominent la production d’énergie et l’équilibre neutronique du cœur, sont reproduits avec une précision bien supérieure à un centième de pour cent. Lorsque les erreurs relatives dépassent brièvement un pour cent pour certains isotopes du plutonium, cela survient tôt dans le cycle alors que leurs quantités absolues sont encore extrêmement faibles, de sorte que l’effet pratique sur le comportement du réacteur est négligeable.
Ce que cela implique pour la modélisation future des réacteurs
Pour les non‑spécialistes, le message essentiel est qu’une procédure d’apprentissage automatique soigneusement entraînée peut rendre les « tables de consultation » nucléaires à l’intérieur de simulations avancées de réacteurs beaucoup plus compactes et plus rapides à utiliser, tout en conservant un comportement simulé du réacteur presque indistinguable de l’approche traditionnelle. L’étude le démontre pour deux cœurs industriels sur une année complète d’exploitation, avec des marges d’erreur faibles par rapport à d’autres incertitudes typiques des analyses de réacteur. Les auteurs précisent que leurs conclusions s’appliquent actuellement aux réacteurs à eau sous pression en régime permanent utilisant une bibliothèque de données et des réglages de code spécifiques, et que des travaux supplémentaires sont nécessaires pour tester d’autres types de réacteurs et des conditions transitoires. Néanmoins, les résultats suggèrent une voie prometteuse vers des simulations nucléaires haute fidélité plus rapides et plus efficaces, permettant de réaliser davantage d’études de conception et d’analyses de sûreté avec des ressources informatiques limitées.
Citation: Hashemi, A., Macián-Juan, R. & Ohlerich, M. Evaluating machine learned nuclear data precision in full core nuclear reactor Monte Carlo neutronics and computational efficiency analyses. Sci Rep 16, 1314 (2026). https://doi.org/10.1038/s41598-026-35227-9
Mots-clés: simulation de réacteur nucléaire, apprentissage automatique, Monte Carlo neutronics, bibliothèques de données nucléaires, réacteurs à eau sous pression