Clear Sky Science · fr
Détection efficace des résumés scientifiques générés par l’IA avec un transformeur léger
Pourquoi il est important de repérer les textes scientifiques écrits par l’IA
À mesure que l’intelligence artificielle devient habile à rédiger, elle peut désormais produire des résumés scientifiques presque indiscernables de ceux rédigés par des humains. Cela soulève des questions délicates : comment les revues, les universités et les lecteurs peuvent-ils s’assurer qu’un résumé reflète vraiment le travail d’un chercheur et non l’invention d’une machine ? Cet article s’attaque à ce problème en développant un outil rapide et compact capable de signaler les résumés scientifiques écrits par l’IA avec une très grande fiabilité, offrant une défense pratique pour l’intégrité académique.
Constituer un banc d’essai d’abstraits réels et synthétiques
Pour mesurer et améliorer la détection de texte IA, les auteurs ont d’abord eu besoin de données fiables. Ils ont collecté 5 000 résumés scientifiques depuis le serveur de prépublications arXiv, couvrant cinq domaines : vision par ordinateur, traitement du signal, biologie quantitative, physique et autres sujets en informatique. Pour chaque résumé rédigé par un humain, ils ont utilisé un grand modèle de langage pour générer une version IA à partir du titre de l’article, en vérifiant soigneusement l’absence de quasi-duplications et en supprimant les indices évidents comme les adresses web ou les extraits de code. Ils ont aussi veillé à ce que les textes IA et humains aient des longueurs similaires, afin que le détecteur ne puisse pas se contenter de statistiques grossières comme le nombre de mots.
Un modèle compact ajusté pour le monde réel
Plutôt que d’utiliser un modèle énorme et coûteux, les chercheurs ont choisi un système plus petit connu sous le nom de DistilBERT, une version allégée d’un modèle de langage populaire. Ils l’ont affiné pour décider, pour chaque résumé, s’il avait été écrit par une personne ou généré par une IA. Le modèle lit jusqu’à 256 tokens—soit environ quelques paragraphes—et produit un score entre zéro et un, interprété comme la probabilité que le texte soit machine‑généré. L’entraînement et l’évaluation ont suivi un protocole strict : les données ont été séparées en ensembles d’entraînement, de validation et de test sans recoupement, et l’équipe a rapporté non seulement l’exactitude mais aussi le comportement du modèle lorsque le taux de fausses alertes autorisé est maintenu très bas, un régime important quand il s’agit d’accuser de vrais auteurs d’avoir utilisé l’IA.
Quelle est la performance du détecteur
Sur les résumés de vision par ordinateur, le principal banc d’essai, le détecteur s’est montré remarquablement précis. Il a correctement étiqueté 499 textes sur 500 générés par l’IA et 495 sur 500 écrits par des humains, atteignant environ 99,4 % d’exactitude et un score quasi parfait sur une courbe de performance standard. Quand les auteurs ont contraint le système à ne commettre au plus qu’une fausse accusation pour cent cas, il détectait encore environ 90 % des textes IA ; avec une tolérance légèrement plus élevée de cinq fausses alertes pour cent, il en captait environ 97 %. Comparé à diverses alternatives—y compris des outils statistiques plus simples et d’autres modèles transformeurs—le détecteur compact s’est montré systématiquement supérieur, surtout dans les scénarios les plus exigeants.
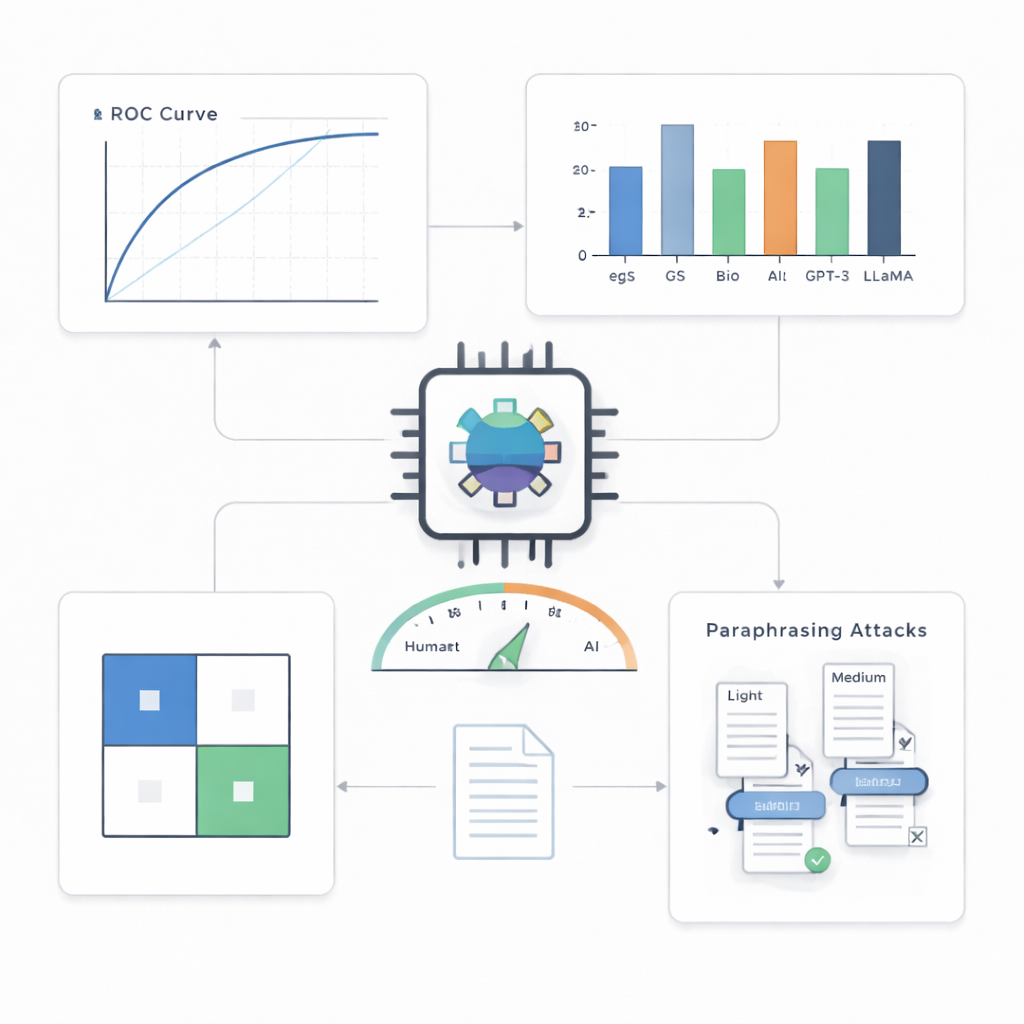
Au-delà d’un seul domaine, d’un seul modèle et des astuces simples
Une question clé est de savoir si un tel détecteur peut gérer des styles d’écriture et des systèmes d’IA qu’il n’a jamais vus. Les auteurs l’ont testé sur des résumés d’autres disciplines scientifiques et sur des textes produits par plusieurs modèles de langage avancés différents. À travers les domaines, les performances sont restées solides, avec seulement des baisses modestes, ce qui suggère que le système capture des traits généraux de l’écriture IA plutôt que les particularités d’un seul champ. Face à des modèles d’IA inconnus, il a également bien performé, quoique moins parfaitement que dans son environnement d’origine. Le défi le plus difficile est venu des attaques de paraphrase : lorsqu’une autre IA réécrivait des résumés générés par machine pour qu’ils paraissent différents tout en conservant leur sens, la détection devenait sensiblement plus difficile. Sous une réécriture de force moyenne, la part de textes IA qui passaient entre les mailles est montée à près de 30 %, montrant que même des détecteurs sophistiqués peuvent être trompés par une dissimulation délibérée.
Ce que cela signifie pour la science et ses garde-fous
L’étude montre que, pour l’instant, les résumés scientifiques écrits par l’IA laissent encore des traces subtiles qu’un modèle bien conçu peut repérer, même lorsque ce modèle est assez petit pour tourner sur du matériel modeste. Cela rend faisable pour les éditeurs, les conférences et les universités de filtrer de grands volumes de soumissions sans coûts informatiques énormes. En même temps, la vulnérabilité aux paraphrases souligne que ces outils ne constituent pas une solution miracle. Les auteurs soutiennent que la détection de texte IA devrait être combinée à d’autres garde-fous—tels que le jugement éditorial, les contrôles de plagiat et les exigences de transparence—pour protéger la fiabilité de la communication scientifique à mesure que les systèmes d’IA continuent de s’améliorer.
Citation: Zhang, C., Zhou, W. Efficient detection of AI-generated scientific abstracts with a lightweight transformer. Sci Rep 16, 4975 (2026). https://doi.org/10.1038/s41598-026-35203-3
Mots-clés: détection de texte IA, résumés scientifiques, intégrité académique, grands modèles de langage, texte généré par machine