Clear Sky Science · fr
Primauté de l’ingénierie des caractéristiques sur la complexité architecturale pour la prévision de la demande intermittente
Pourquoi prédire des ventes rares importe
Derrière chaque atelier de réparation automobile ou chaque entrepôt de pièces se cache une énigme discrète : combien de pièces de rechange peu vendues faut-il garder en stock ? Ces articles se vendent rarement et de façon imprévisible, mais doivent être disponibles quand un véhicule tombe en panne. Surcommander immobilise du capital dans des stocks poussiéreux ; sous-commander fait attendre les clients pendant que les pièces sont expédiées en urgence. Cet article s’attaque à ce problème quotidien mais coûteux en posant une question simple : vaut-il mieux multiplier les modèles de prédiction toujours plus complexes, ou alimenter les modèles existants avec des signaux issus d’une ingénierie des caractéristiques plus intelligente et soignée ?
De longues périodes d’absence à des pics soudains
Dans de nombreuses chaînes d’approvisionnement, en particulier pour les pièces automobiles, la demande n’est pas régulière comme pour le lait ou le pain. On observe plutôt de longues périodes de plusieurs mois sans aucune vente, ponctuées de commandes soudaines de quelques unités. Les auteurs analysent plus de 56 000 combinaisons concessionnaire–pièce, couvrant environ 1,4 million d’enregistrements mensuels, et constatent que la plupart des séries sont extrêmement creuses : en moyenne, il y a beaucoup de mois nuls pour chaque mois avec vente, et la taille des commandes varie fortement. Les méthodes statistiques traditionnelles comme l’approche de Croston et ses raffinements ont été conçues pour ce type de demande « marche–arrêt » et produisent des prévisions stables et interprétables, mais elles traitent chaque pièce isolément et ne peuvent pas facilement exploiter des informations supplémentaires comme les prix ou les attributs produits. Les systèmes modernes d’apprentissage automatique peuvent, en principe, utiliser toutes ces informations, mais ils peinent lorsque les données sont majoritairement constituées de zéros et seulement occasionnellement informatives.
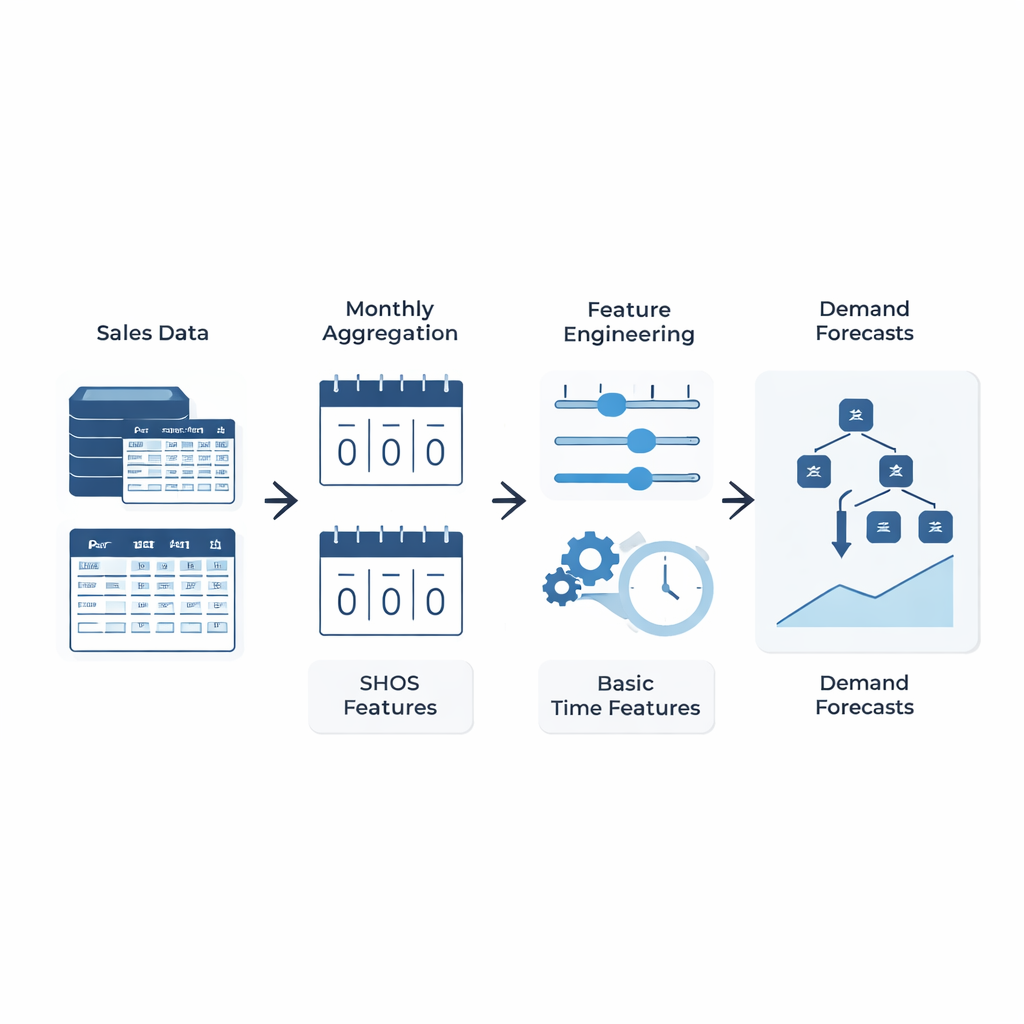
Une idée simple : apprendre au modèle ce qui compte vraiment
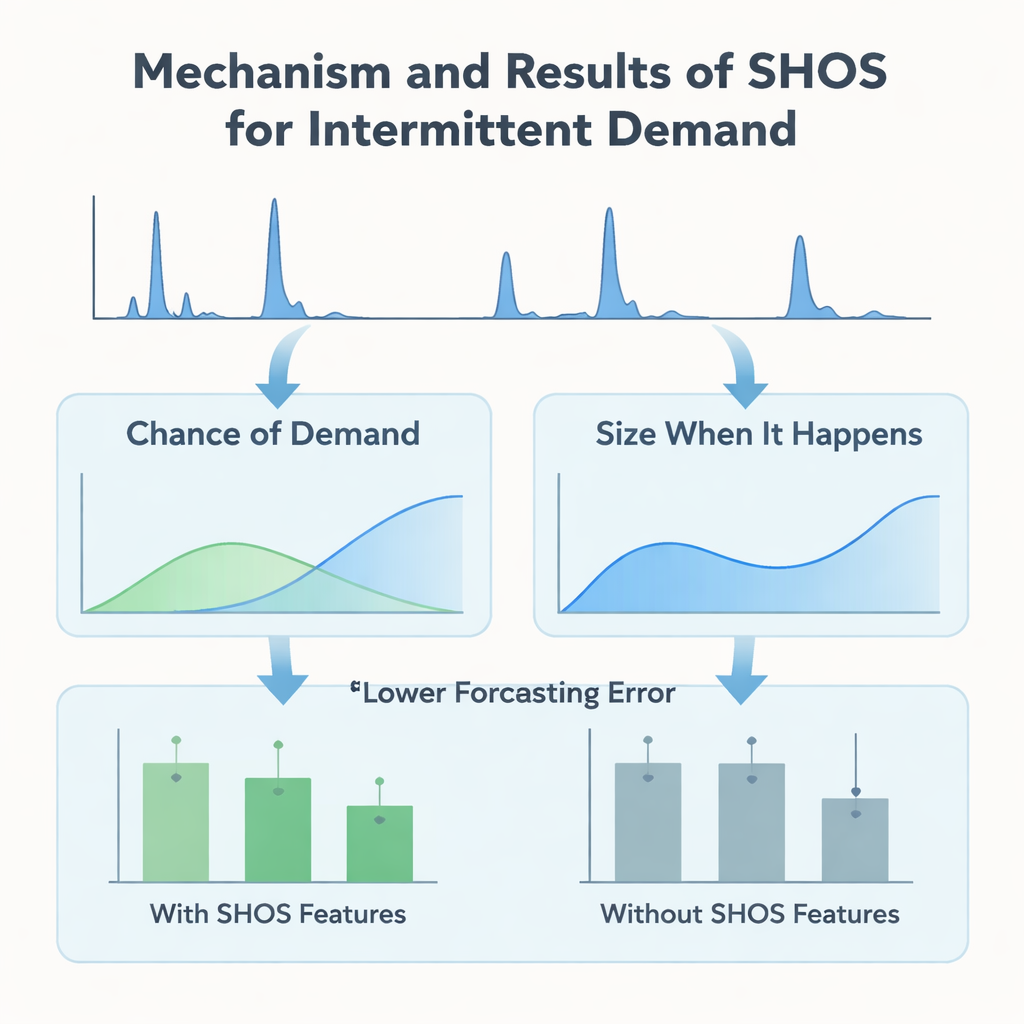
Plutôt que de concevoir des architectures d’apprentissage automatique toujours plus complexes, les auteurs se concentrent sur ce qui est fourni au modèle. Ils présentent le cadre Smoothed Hybrid Occurrence–Size (SHOS), une routine statistique légère qui s’exécute sur chaque historique de demande. À chaque mois, SHOS produit deux nombres : la probabilité estimée qu’une demande se manifeste le mois suivant, et la taille typique de cette demande si elle se produit. Il le fait en lissant soigneusement les zéros et les non-zéros passés, en adaptant son comportement aux séries très creuses, et en réagissant plus rapidement lorsque la demande réapparaît soudainement après une longue accalmie. De façon cruciale, SHOS n’est pas le modèle de prévision final. Ses sorties deviennent des caractéristiques supplémentaires pour des algorithmes d’apprentissage automatique standards, aux côtés d’éléments simples comme les ventes récentes, les moyennes glissantes et les attributs produits statiques.
Mettre la qualité des caractéristiques avant la complexité du modèle
Pour vérifier si ce « pré‑traitement » statistique aide vraiment, les chercheurs construisent une expérience contrôlée. Ils comparent une gamme de modèles populaires — arbres à gradient, forêts aléatoires et méthodes linéaires — avec et sans caractéristiques SHOS, tous entraînés sur le même panel mensuel rempli de zéros et évalués au moyen d’un schéma rigoureux en fenêtres mobiles qui imite le déploiement réel. Ils testent également des modèles à deux étapes plus élaborés, dits « hurdle », qui prédisent séparément si la demande aura lieu et quelle en sera la magnitude. Sur 11 fenêtres de validation, l’ajout des caractéristiques SHOS réduit presque de moitié l’erreur moyenne de prévision pour les articles fortement intermittents et abaisse une métrique commerciale clé, l’erreur absolue moyenne en pourcentage pondérée, de plus de 40 %. Fait surprenant, les architectures en deux étapes, bien que plus complexes et adaptées à ce type de données, ne surpassent pas un régresseur unique et simple qui ingère simplement les signaux SHOS.
Voir comment le modèle prend ses décisions
L’équipe va au‑delà de la précision globale et examine comment les modèles utilisent réellement l’information qui leur est fournie. À l’aide de SHAP, un outil standard pour interpréter les prédictions d’apprentissage automatique, ils montrent que les caractéristiques basées sur SHOS — « probabilité de demande » et « taille lorsqu’elle se produit » — figurent systématiquement parmi les entrées les plus influentes. Pendant les longues périodes sans demande, une faible probabilité SHOS pousse les prévisions vers zéro, évitant une accumulation de stock injustifiée. Lorsqu’un pic de demande survient après une période sèche, un ajustement de récence dans SHOS augmente rapidement les estimations de probabilité et de taille, permettant au modèle de répondre sans surréagir à un seul pic. Ces comportements se retrouvent aussi bien dans le modèle simple à une étape que dans les versions hurdle plus complexes, soulignant que le gain principal provient de la qualité des signaux, et non d’artifices d’architecture.
Ce que cela signifie pour les décisions quotidiennes d’inventaire
Pour les praticiens qui cherchent à garder les bonnes pièces en stock, le message est à la fois pratique et rassurant. L’étude montre que des caractéristiques soigneusement conçues et fondées statistiquement peuvent apporter de grandes améliorations dans la prévision de ventes rares et irrégulières sans recourir à des dispositifs de modèle fragiles et difficiles à maintenir. Un arbre à gradient modeste et bien réglé équipé de caractéristiques SHOS bat ou égalise des chaînes d’outils plus élaborées tout en restant plus simple à déployer et à surveiller sur des dizaines de milliers d’articles. En termes simples, alimenter votre système de prévision par de meilleurs résumés de la fréquence et de la quantité probables de commande par les clients peut compter davantage que de passer au dernier algorithme le plus complexe. Cette mise en avant de blocs de construction simples et interprétables rend l’approche attrayante pour des chaînes d’approvisionnement à grande échelle dans le monde réel et suggère que des stratégies similaires centrées sur les caractéristiques pourraient être payantes dans d’autres secteurs confrontés à une demande intermittente.
Citation: Nathan, B.S., Aravinth, P.M., Reddy, B.V.S. et al. Primacy of feature engineering over architectural complexity for intermittent demand forecasting. Sci Rep 16, 4792 (2026). https://doi.org/10.1038/s41598-026-35197-y
Mots-clés: demande intermittente, prévision des pièces détachées, ingénierie des caractéristiques, analytique de la chaîne d’approvisionnement, apprentissage automatique