Clear Sky Science · fr
Évaluation de ChatGPT-4o et Gemini pour la prise en charge de la goutte : une analyse comparative basée sur les recommandations de l’EULAR
Pourquoi les chatbots intelligents et les articulations douloureuses importent
La goutte, une forme douloureuse d’arthrite qui touche souvent le gros orteil, devient plus fréquente dans le monde. Les médecins disposent déjà de directives claires et fondées sur des preuves pour la diagnostiquer et la traiter, et pourtant de nombreux patients ne reçoivent toujours pas des soins optimaux. Parallèlement, des chatbots d’intelligence artificielle puissants comme ChatGPT-4o et Gemini commencent à faire leur apparition en milieu clinique, ce qui soulève une question simple mais cruciale : ces outils peuvent‑ils réellement fournir des conseils sûrs et conformes aux recommandations sur la goutte, ou risquent‑ils d’induire médecins et patients en erreur ?
Vérifier dans quelle mesure les chatbots respectent le manuel
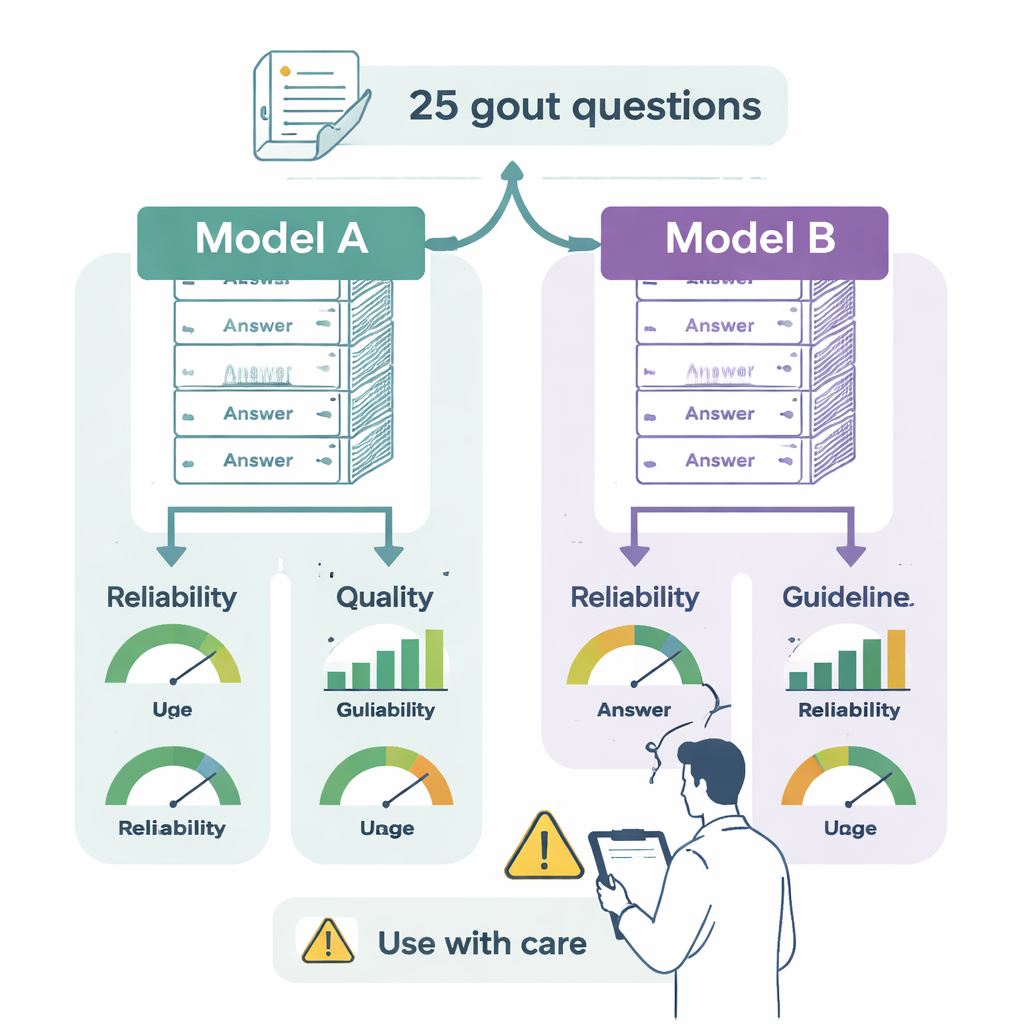
Les chercheurs se sont donné pour objectif d’évaluer deux modèles de langage de premier plan — ChatGPT-4o et Gemini 2.0 Flash — par rapport aux recommandations européennes officielles (EULAR) sur la goutte. Deux spécialistes ont transformé 25 recommandations clés du guide en questions de type médecin portant sur des situations concrètes : comment diagnostiquer la goutte, quand commencer un traitement hypouricémiant, comment gérer les poussées, quels objectifs viser dans les analyses sanguines, et comment adapter le mode de vie ou d’autres traitements. Les deux chatbots ont reçu les mêmes questions dans des sessions distinctes et « propres » afin qu’une réponse antérieure n’influence pas la suivante.
Comment les réponses ont été notées
Chaque réponse a été évaluée par deux cliniciens expérimentés en goutte, qui ignoraient quel modèle avait produit le texte. Ils ont noté trois aspects. D’abord, la fiabilité : la réponse paraît‑elle équilibrée, objective et digne de confiance, ou omet‑elle des éléments clés ou exagère‑t‑elle les bénéfices ? Ensuite, la qualité : la réponse est‑elle claire, bien organisée et utile pour un spécialiste prenant des décisions ? Enfin, l’alignement avec les recommandations : correspond‑elle à ce que recommande l’EULAR, est‑elle partiellement conforme avec des lacunes, ou contredit‑elle directement les règles ? L’équipe a également évalué la difficulté de lecture des réponses à l’aide de tests standard qui estiment le niveau d’études requis pour comprendre un texte.
ChatGPT vs. Gemini : lequel a mieux performé ?
Les deux chatbots ont fourni des réponses généralement sensées et bien rédigées, et tous deux rappelaient souvent de consulter un professionnel de santé. Mais d’importantes différences sont apparues. ChatGPT-4o correspondait pleinement aux recommandations sur la goutte dans 76 % des cas et fournissait des réponses majoritairement correctes mais incomplètes dans 20 % des cas, avec une seule réponse contenant une erreur médicale manifeste. Gemini était pleinement aligné dans 48 % des réponses et partiellement correct mais incomplet dans 32 %. Plus inquiétant, 12 % de ses réponses mélangeaient des éléments corrects et erronés, et 8 % contredisaient carrément les recommandations — par exemple en suggérant un usage large d’une classe puissante d’anti‑inflammatoires (inhibiteurs de l’IL‑1) que l’EULAR réserve à des patients sélectionnés et difficiles à traiter, ou en recommandant systématiquement de commencer un traitement hypouricémiant pendant une poussée aiguë, un domaine où les experts préconisent plus de prudence.
Lisible, mais pas facile à lire
Sur le plan du style, les deux systèmes se sont révélés étonnamment similaires. Selon plusieurs échelles de lisibilité, les textes produits exigeaient au moins un niveau d’études universitaire pour être suivis confortablement. Cela peut convenir aux médecins spécialistes mais reste bien trop complexe pour la plupart des patients. Aucun des modèles n’a fourni de références ou de liens vers les sources, sauf demande explicite, ce qui complique la vérification de l’origine des informations. L’accord entre les évaluateurs a été jugé bon à excellent, ce qui suggère que la notation était cohérente et que les différences observées entre les chatbots reflètent des écarts réels plutôt que des préférences individuelles.
Ce que cela signifie pour les personnes vivant avec la goutte
Globalement, l’étude suggère que les chatbots avancés peuvent être des assistants utiles pour les médecins prenant en charge la goutte, mais qu’ils ne sont pas encore prêts à fonctionner de manière autonome. ChatGPT-4o s’est montré plus fiable, plus complet et plus fidèle aux recommandations d’experts que Gemini, cependant même ses rares erreurs peuvent avoir des conséquences lorsque des médicaments et des questions de sécurité sont en jeu. Les deux outils s’expriment à un niveau trop technique pour la plupart des patients et manquent de transparence intégrée sur leurs sources. Pour l’heure, les auteurs estiment que l’IA doit être considérée comme un outil d’aide prometteur pour les cliniciens et les formateurs — mais seulement si ses conseils sont systématiquement confrontés aux recommandations actualisées et au jugement d’experts, notamment pour des affections comme la goutte où des détails de posologie et de timing peuvent fortement impacter la douleur, les séquelles à long terme et la qualité de vie.
Citation: Meral, H.B., Kolak, E. Evaluation of ChatGPT-4o and Gemini for gout management: a comparative analysis based on EULAR guidelines. Sci Rep 16, 4831 (2026). https://doi.org/10.1038/s41598-026-35166-5
Mots-clés: goutte, recommandations cliniques, intelligence artificielle, grands modèles de langage, rhumatologie