Clear Sky Science · fr
Modèles d’apprentissage profond compacts pour l’histopathologie du côlon : performance et défis de généralisation
Pourquoi cette recherche compte pour les patients et les médecins
Le cancer du côlon fait partie des cancers les plus mortels au monde, et son diagnostic repose encore sur l’examen minutieux par des spécialistes d’images microscopiques de tissus, une tâche lente et sujette à des désaccords. Cette étude explore si des modèles d’intelligence artificielle (IA) très petits et efficaces peuvent aider à repérer les tissus colorectaux cancéreux avec une précision suffisante pour être utiles en clinique quotidienne, y compris dans des établissements disposant de ressources informatiques limitées. Elle met aussi en lumière une faiblesse cachée : des modèles qui paraissent presque parfaits lors du développement peuvent pourtant échouer sévèrement sur des données nouvelles et issues du monde réel.
Apprendre aux ordinateurs à « lire » des images au microscope
Lorsqu’une biopsie du côlon est prélevée, les pathologistes examinent des coupes minces colorées du tissu au microscope. Le tissu cancéreux présente des glandes déformées, des formes cellulaires irrégulières et une invasion des structures environnantes, tandis que le tissu sain montre des motifs ordonnés et réguliers. Les auteurs ont utilisé une collection publique de 24 000 images numériques de ces coupes, réparties équitablement entre adénocarcinome du côlon et tissu bénin. Ils ont redimensionné toutes les images dans un format standard et appliqué des transformations réalistes — petites rotations, retournements, zooms et légères variations de couleur — pour imiter la variation naturelle dans la coupe, la coloration et la numérisation des lames. Cette préparation soigneuse aide les modèles d’IA à se concentrer sur des motifs tissulaires signifiants plutôt que sur des détails superficiels comme l’orientation exacte ou la luminosité.
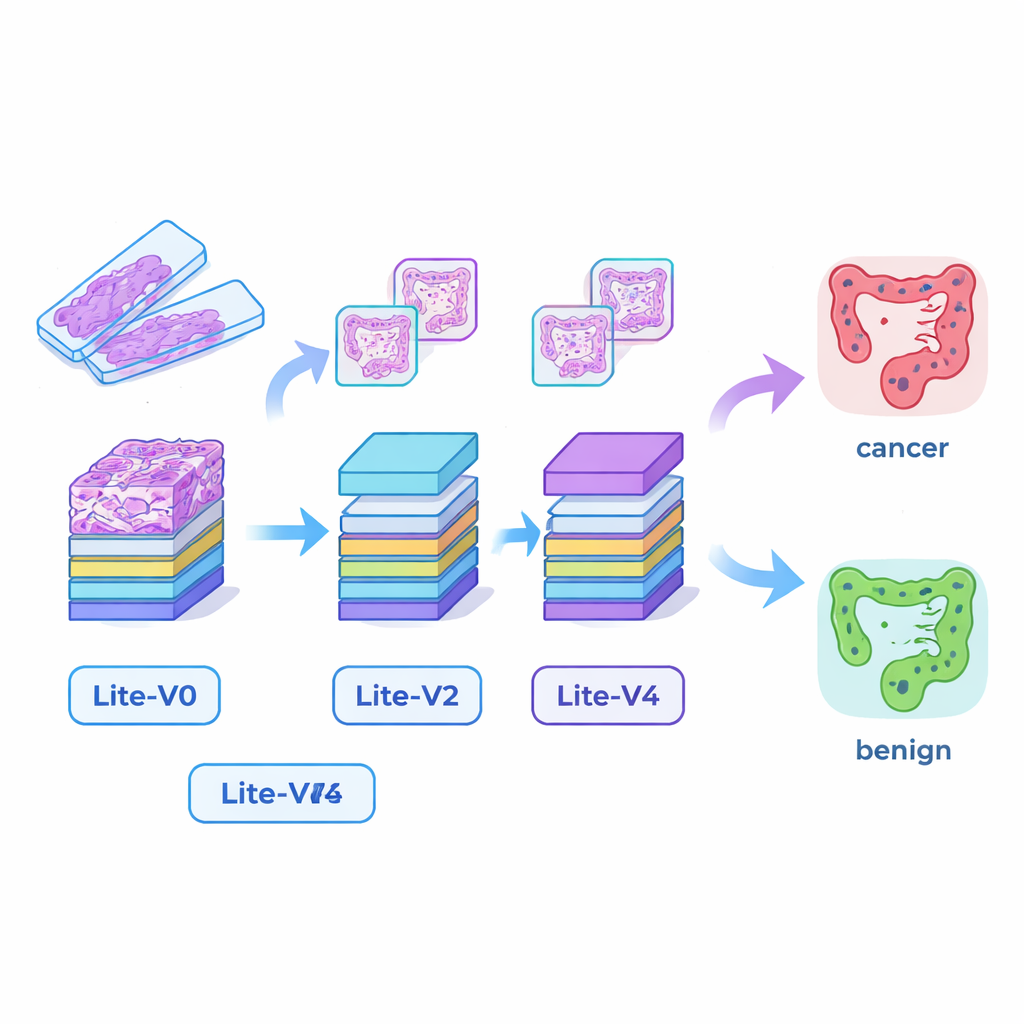
Construire de « petits yeux » d’IA capables
De nombreux systèmes d’IA médicaux performants reposent sur des modèles d’apprentissage profond très volumineux qui exigent des cartes graphiques puissantes et beaucoup de mémoire, ce qui complique leur déploiement dans les hôpitaux modestes ou au chevet. Pour combler ce fossé, les chercheurs ont conçu quatre réseaux de neurones convolutionnels compacts — Lite‑V0, Lite‑V1, Lite‑V2 et Lite‑V4. Chacun analyse les mêmes patchs d’image en entrée, mais ils diffèrent par le nombre de couches et de filtres utilisés pour détecter des caractéristiques visuelles comme les bords, les textures et la forme des glandes. Les quatre partagent une architecture simple et transparente : des blocs répétés de convolution standard, normalisation et pooling, suivis d’un petit « module de décision » qui donne la probabilité de tissu cancéreux ou bénin. L’objectif était de mesurer combien de précision on pouvait extraire de modèles suffisamment petits pour tenir confortablement sur du matériel clinique basique.
Des scores impressionnants en laboratoire
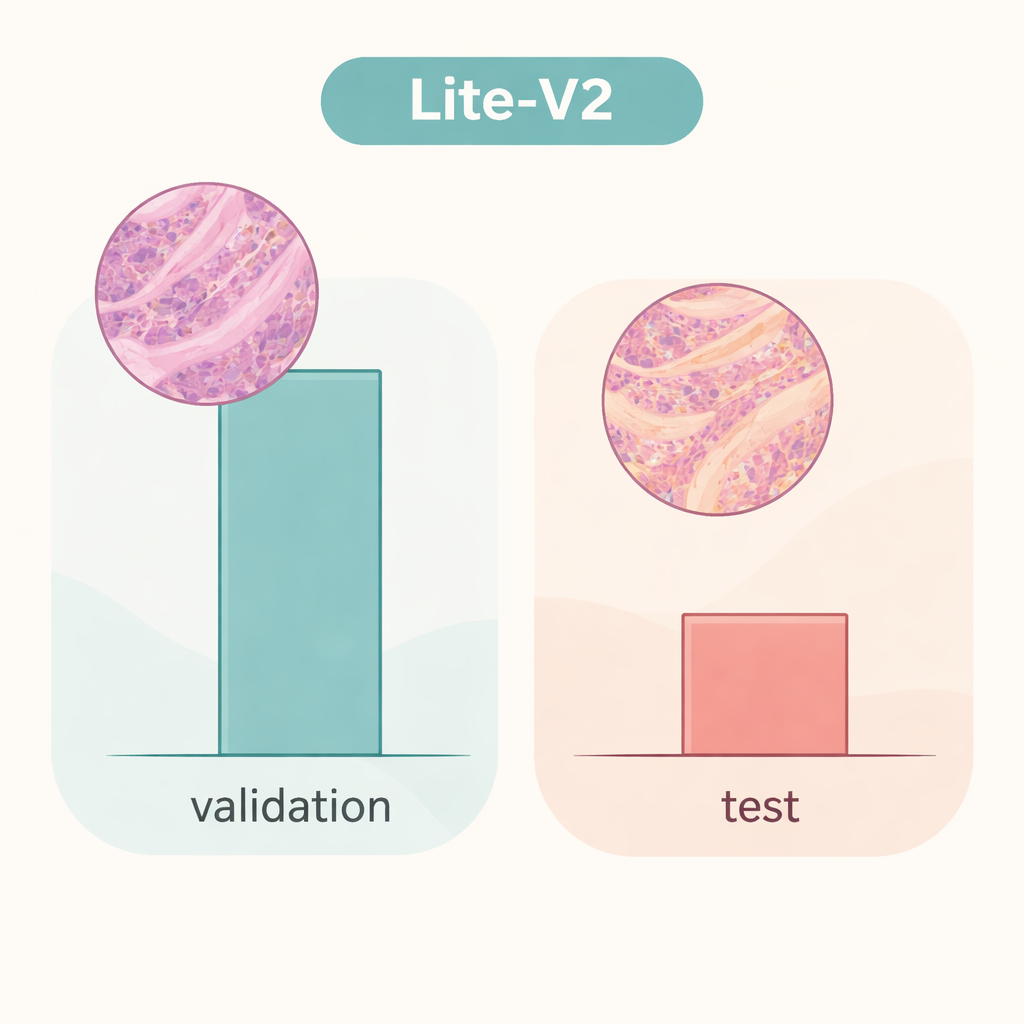
L’équipe a entraîné et comparé les quatre modèles sur une répartition fixe du jeu de données, en utilisant des mesures couramment acceptées : exactitude, F1‑score macro qui pèse également les erreurs des deux classes, matrices de confusion et courbes diagnostiques telles que les courbes ROC et précision‑rappel. Un modèle de taille moyenne, Lite‑V2, s’est imposé comme le meilleur. Malgré sa taille d’environ 1,5 mégaoctet et ses quelque 128 000 paramètres entraînables, il a obtenu des performances presque parfaites sur l’ensemble de validation interne, avec un F1‑score macro d’environ 0,999 et une sensibilité et spécificité quasi parfaites. Autrement dit, dans cet environnement soigneusement préparé, Lite‑V2 distinguait presque toujours le tissu cancéreux du tissu bénin, tout en restant suffisamment rapide et léger pour être utilisé sur des ordinateurs modestes.
Quand la variation du monde réel brise l’illusion
Cependant, la situation change radicalement lorsque le même modèle Lite‑V2 est testé sur un ensemble indépendant d’images qui diffèrent subtilement de façon à reproduire des lames provenant d’un autre laboratoire — ce que les chercheurs appellent un « décalage de domaine ». Sur cet ensemble de test inédit, l’exactitude globale est tombée à environ 50 % et le F1‑score macro a chuté à près de 0,33. Le modèle continuait à reconnaître de nombreux échantillons cancéreux, mais il a eu de grandes difficultés avec le tissu bénin, étiquetant une large partie comme maligne. Cela montre que le réseau avait appris des détails fortement liés à la source de données initiale — comme le style de coloration ou les caractéristiques du scanner — plutôt que des signatures de maladie robustes et transférables. Le travail souligne que des résultats éblouissants en validation interne peuvent donner un faux sentiment de sécurité si les modèles ne sont pas testés sur des données véritablement différentes.
Ce que cela signifie pour les futurs outils de diagnostic par IA
Pour le lecteur général, la conclusion est double. D’une part, des systèmes d’IA compacts peuvent réellement atteindre un niveau de performance comparable à celui d’experts sur des images de tissu colique tout en restant assez petits et efficaces pour un déploiement large, ouvrant la voie à un dépistage plus rapide et à un soutien pour des pathologistes surchargés. D’autre part, et c’est tout aussi important, un modèle qui semble « parfait » sur son jeu de données d’origine peut échouer sévèrement lorsqu’il rencontre des images d’un nouvel hôpital. Les auteurs soutiennent que les travaux futurs doivent se concentrer sur la robustesse de ces modèles légers face aux changements de coloration, de scanners et de populations de patients — en utilisant des stratégies comme l’entraînement robuste aux colorations, l’adaptation de domaine et des jeux de données multicentriques plus larges. D’ici là, l’IA doit être considérée comme un assistant prometteur plutôt que comme un décideur autonome pour le diagnostic du cancer.
Citation: Hanif, F., Raza, A. & Mohammed, H.A. Compact deep learning models for colon histopathology focusing performance and generalization challenges. Sci Rep 16, 5489 (2026). https://doi.org/10.1038/s41598-026-35119-y
Mots-clés: cancer du côlon, histopathologie, apprentissage profond, CNN légère, décalage de domaine