Clear Sky Science · fr
Prédiction des protéines associées aux racines à l’aide d’un grand modèle de langage protéique et de réseaux convolutionnels hypergraphes
Pourquoi les racines et leurs aides cachées comptent
Quand on pense à maintenir les cultures en bonne santé, on imagine généralement les feuilles et les fruits. Mais une grande part du succès d’une plante se joue hors de la vue, dans le sol. Là, des protéines spécifiques associées aux racines aident la plante à absorber l’eau et les nutriments et à faire face à des stress comme la sécheresse ou la pauvreté du sol. Repérer ces protéines cruciales uniquement par des expériences en laboratoire est lent et coûteux. Cette étude présente un puissant modèle informatique, nommé Hypergraph-Root, capable d’analyser rapidement des séquences protéiques et de prédire lesquelles sont susceptibles d’être associées aux racines, offrant une voie plus rapide vers des cultures plus robustes et de meilleures récoltes.
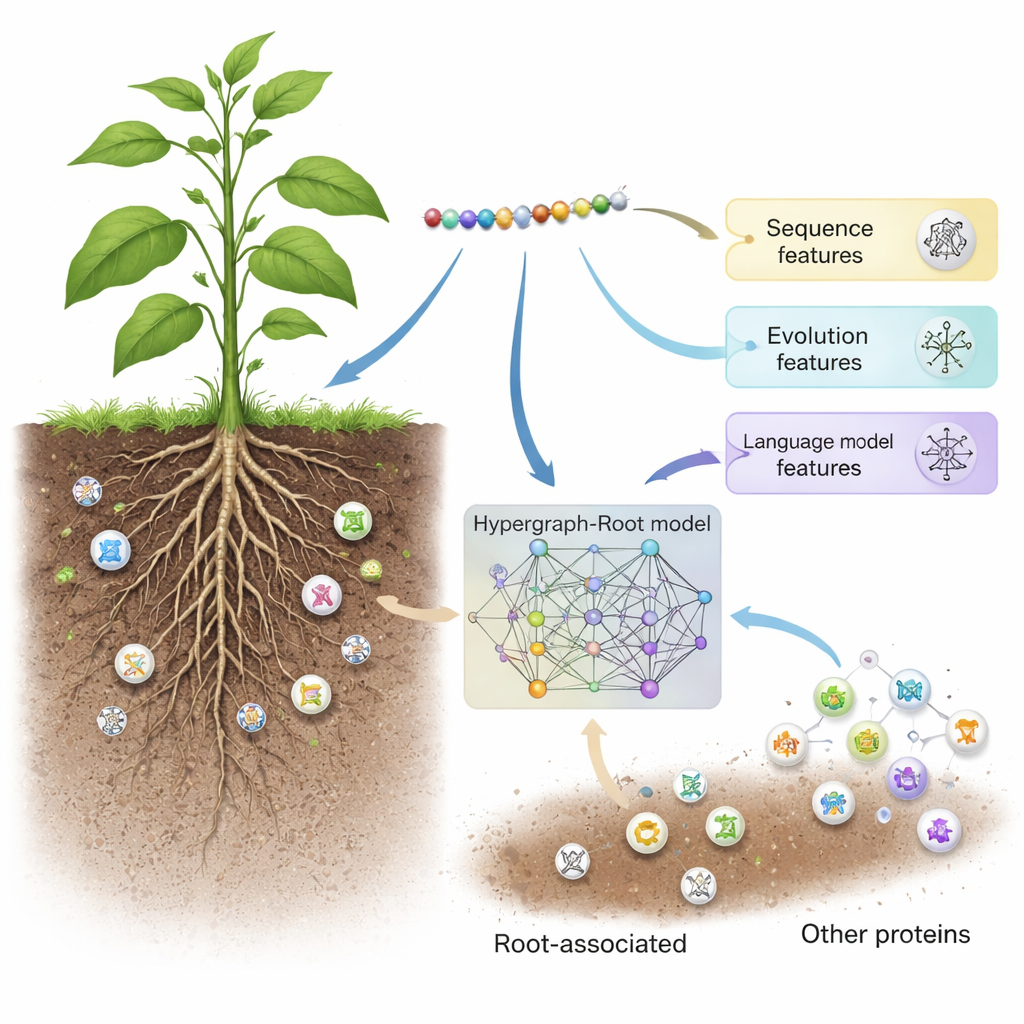
Des ouvriers discrets dans le sol
Les racines des plantes font bien plus que fixer la plante au sol. Elles détectent en permanence leur environnement, prélèvent des minéraux et communiquent avec les microbes du sol. Les protéines associées aux racines sont au centre de tout cela : elles influencent la croissance des racines, leur réponse à la chaleur, à la sécheresse ou au manque de nutriments, et leurs interactions avec des microbes utiles. Parce que ces protéines ont une forte influence sur le rendement et la résilience, agriculteurs et sélectionneurs s’y intéressent même s’ils ne les voient jamais directement. Pourtant, beaucoup de ces protéines restent à découvrir, principalement parce que les méthodes traditionnelles—comme la protéomique et les études d’expression génique—exigent des instruments coûteux, des analyses complexes et des expériences minutieuses.
Transformer les séquences protéiques en indices
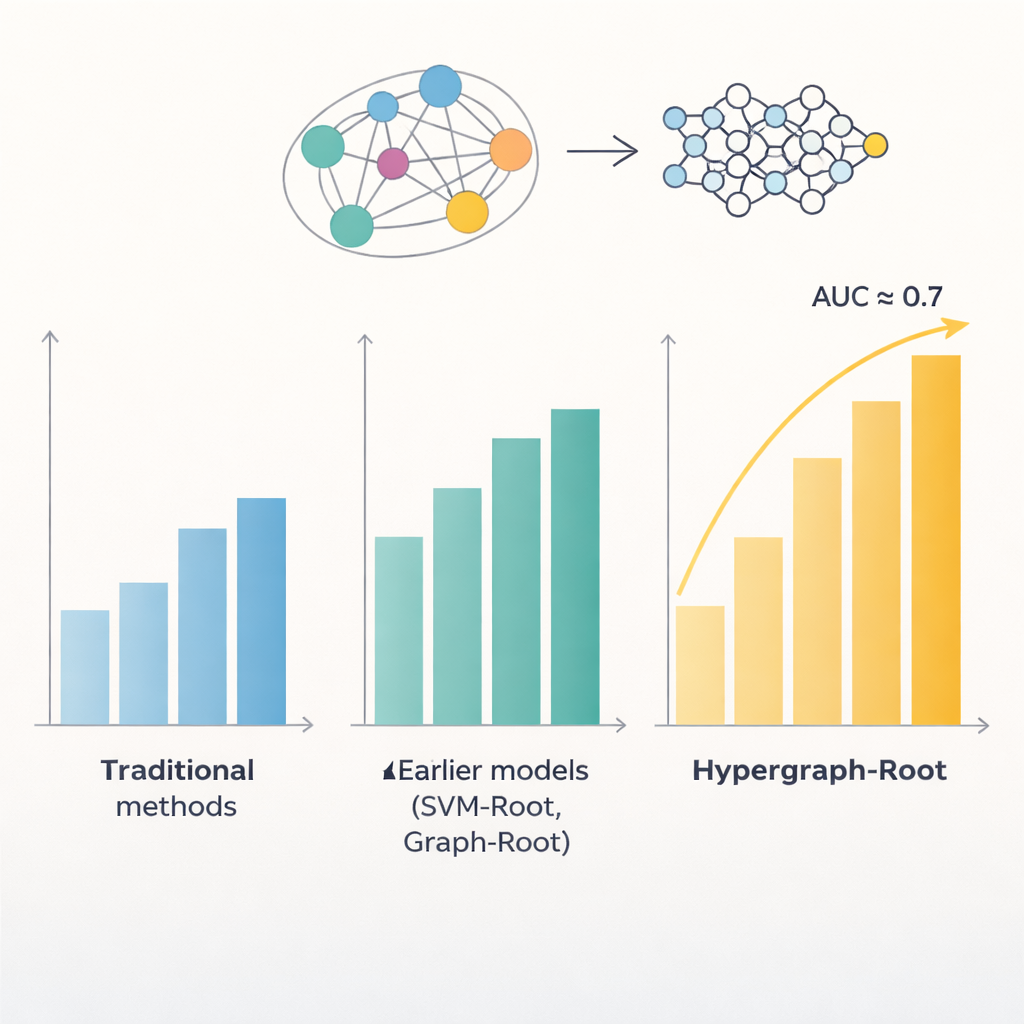
Les protéines sont constituées d’enchaînements d’acides aminés, et des motifs dans ces séquences révèlent souvent où la protéine agit dans la plante et ce qu’elle fait. Des modèles informatiques antérieurs ont tenté d’exploiter ces motifs pour repérer les protéines associées aux racines, mais leur précision plafonnait en dessous de 80 %. Un problème est qu’ils traitaient les relations entre acides aminés de façon assez simple, généralement par paires. Un autre problème est qu’ils s’appuyaient sur des types limités de caractéristiques extraites des séquences. Les auteurs ont émis l’hypothèse que des représentations plus riches de chaque protéine, combinées à des façons plus intelligentes de modéliser les relations entre acides aminés, pourraient révéler des motifs plus subtils liés aux fonctions racinaires.
Emprunter des astuces au langage et aux réseaux
Hypergraph-Root commence par décrire chaque protéine de trois manières complémentaires. Il utilise des schémas de scoring de séquence traditionnels (BLOSUM62 et matrices de score positionnelles) qui capturent comment les acides aminés se substituent les uns aux autres au cours de l’évolution. Il ajoute ensuite une troisième description, plus moderne, issue d’un modèle de langage protéique appelé ProtT5—un logiciel entraîné sur des millions de séquences protéiques, un peu comme un moteur de prédiction de texte est entraîné sur des langues humaines. ProtT5 produit un « embedding » numérique riche pour chaque acide aminé, encodant des indices structuraux et fonctionnels. Ensemble, ces trois perspectives fournissent l’empreinte détaillée de chaque protéine étudiée.
Cartographier des connexions complexes au sein des protéines
Pour aller au-delà des comparaisons simples par paires, les chercheurs ont prédit la proximité des acides aminés dans la structure 3D d’une protéine et ont utilisé cette information pour construire un hypergraphe—un réseau dans lequel une même connexion peut relier plus de deux acides aminés à la fois. Un réseau neuronal spécialisé, le réseau convolutionnel hypergraphe, traite cette structure sensible au contexte et affine les empreintes des protéines en des caractéristiques de niveau supérieur. Un module d’attention multi-têtes apprend ensuite quelles parties de la protéine contiennent les signaux les plus utiles pour décider si elle est associée aux racines. Enfin, un classifieur standard transforme ces caractéristiques distillées en un score de probabilité : associée aux racines ou non. Sur de nombreux entraînements et sur des jeux de test équilibrés ou déséquilibrés, Hypergraph-Root a atteint des précisions supérieures à 83 % et une aire sous la courbe ROC (AUC) autour de 0,9, surpassant nettement les modèles antérieurs.
Ce que le modèle révèle et pourquoi c’est important
Au-delà de la simple précision, le modèle a fourni des indications sur les informations les plus déterminantes. Les caractéristiques issues du modèle de langage ProtT5 ont contribué davantage que les caractéristiques de séquence et d’évolution traditionnelles, ce qui suggère que de grands modèles pré-entraînés peuvent capter des signaux biologiques subtils que les méthodes plus anciennes manquent. La composante hypergraphe s’est également révélée importante : la supprimer ou la remplacer par un modèle de graphe plus simple réduisait les performances. Quand les chercheurs ont appliqué Hypergraph-Root à des protéines jusque-là non étiquetées comme associées aux racines, il a mis en évidence un petit nombre de candidats dont les fonctions connues—comme le transport membranaire et l’étiquetage des protéines dans les racines—suggèrent fortement qu’elles jouent un rôle en biologie des racines. Ces candidats offrent désormais aux biologistes expérimentaux des listes courtes et ciblées à tester en laboratoire.
Des prédictions intelligentes vers des cultures plus robustes
En termes simples, Hypergraph-Root agit comme un bibliothécaire expert en biologie végétale : à partir des seules « lettres » d’une protéine, il estime si cette protéine travaille probablement dans les racines. En combinant les informations du modèle de langage, l’histoire évolutive et des relations structurelles complexes, il améliore considérablement les outils de prédiction existants. S’il ne remplace pas les expériences, il peut réduire des milliers de possibilités à quelques centaines ou dizaines gérables, économisant temps et argent. À long terme, de tels modèles pourraient accélérer la découverte de protéines associées aux racines qui aident les cultures à survivre à la chaleur, à la sécheresse ou aux sols pauvres—une étape importante vers une agriculture plus résiliente face au changement climatique.
Citation: Chen, L., Xun, X. & Zhou, B. Root-associated protein prediction using a protein large language model and hypergraph convolutional networks. Sci Rep 16, 4876 (2026). https://doi.org/10.1038/s41598-026-35110-7
Mots-clés: protéines associées aux racines, bioinformatique végétale, apprentissage profond, modèles de langage protéique, résilience des cultures