Clear Sky Science · fr
Une approche d’apprentissage multimodal et de simulation pour la perception dans les systèmes de conduite autonome
Des voitures autonomes plus intelligentes
Les voitures autonomes promettent des routes plus sûres et moins d’embouteillages, mais seulement si elles peuvent vraiment comprendre le monde qui les entoure. Cet article explore une nouvelle manière d’aider les véhicules autonomes à « voir », « ressentir » et « anticiper » leur environnement de façon plus proche d’un conducteur humain prudent — en combinant différents capteurs, en testant en toute sécurité dans une copie virtuelle du monde réel et en rendant les décisions de la voiture plus transparentes pour les personnes.
Voir la route avec de nombreux « sens »
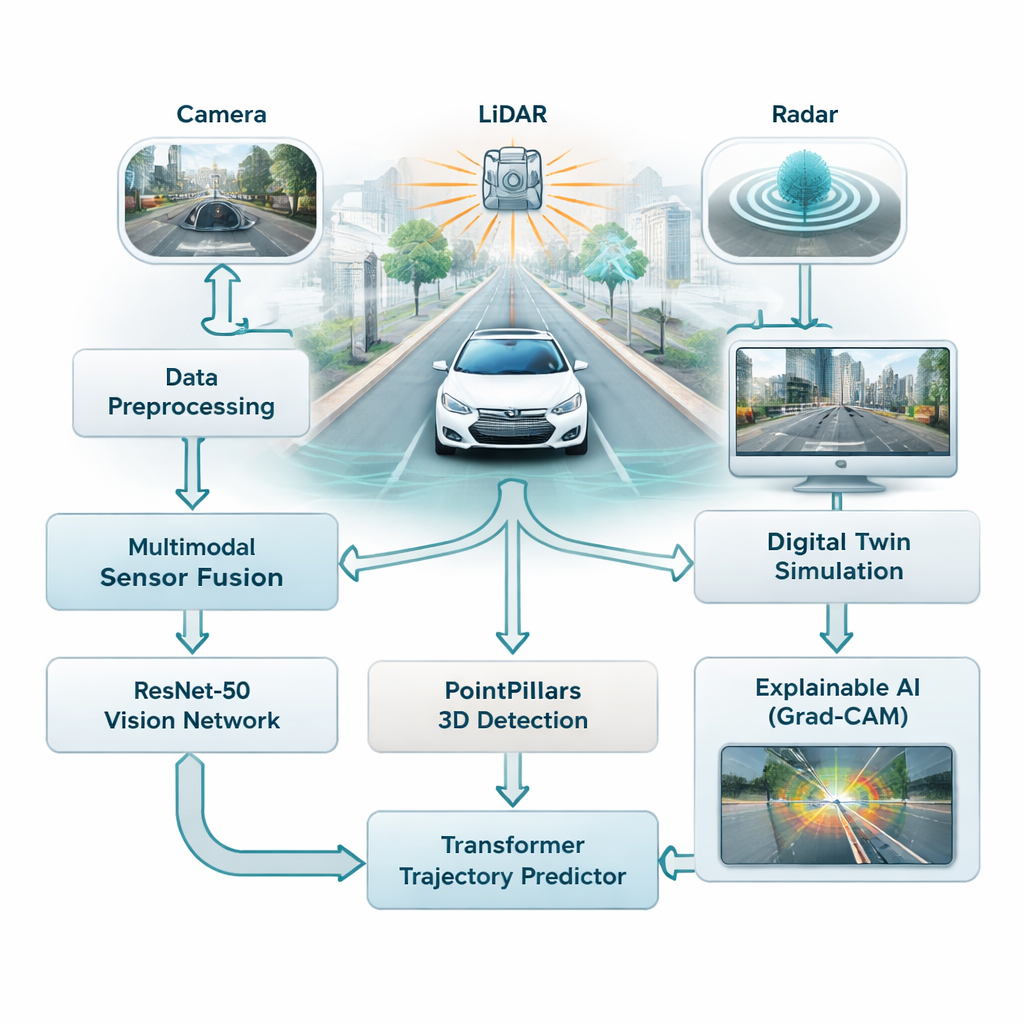
La plupart des systèmes d’assistance à la conduite s’appuient aujourd’hui fortement sur les caméras, qui fonctionnent bien par bonne luminosité mais peinent dans le brouillard, la pluie ou la nuit. Cette étude combine trois types de capteurs — caméras, scanners laser (LiDAR) et radar — afin que la voiture ne dépende pas d’une source d’information unique et fragile. Les caméras saisissent la couleur et les détails, le LiDAR construit une image 3D précise de la scène, et le radar reste fiable par mauvais temps. Les auteurs fusionnent ces trois flux en une vue unique du trafic, offrant au véhicule une compréhension plus complète et plus robuste des routes, des piétons et des autres véhicules.
Apprendre à la voiture à reconnaître et anticiper
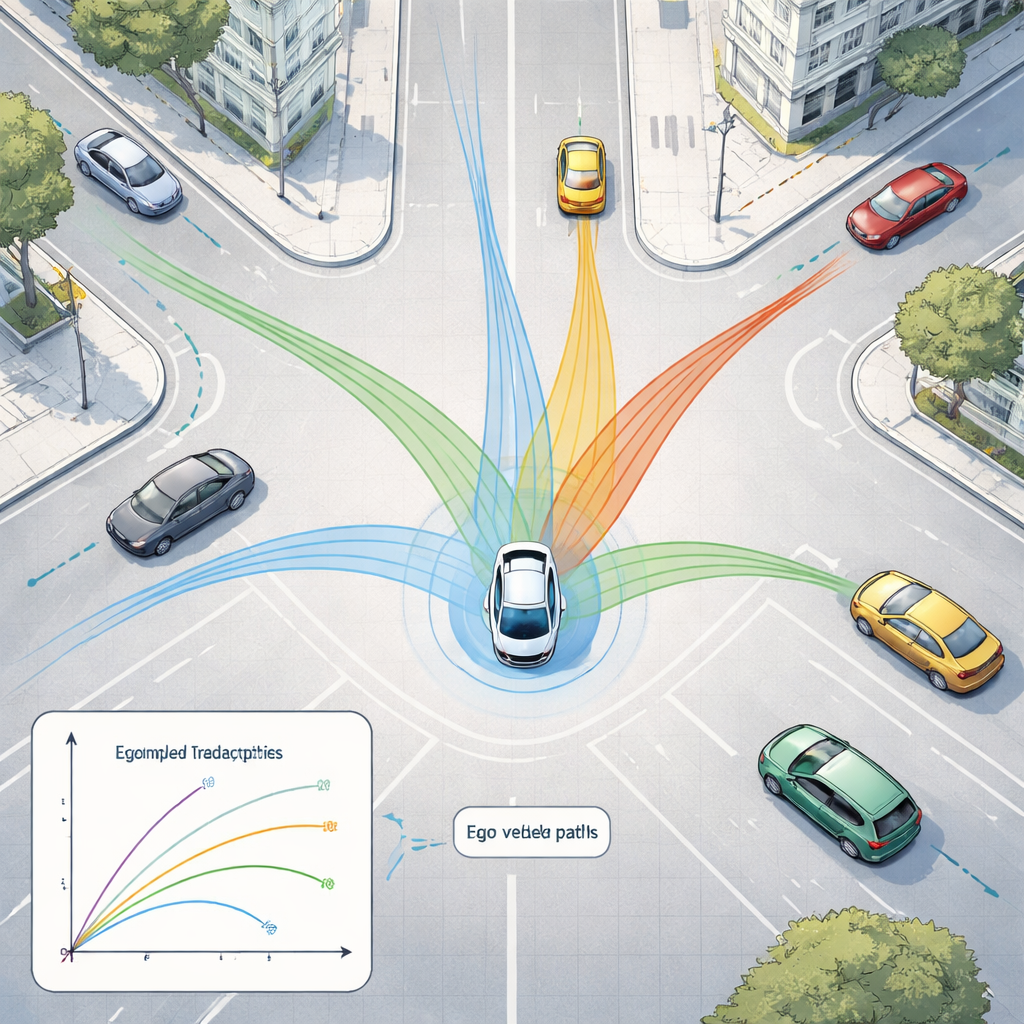
Pour donner un sens à ce flot de données, le cadre utilise deux familles de modèles d’IA modernes. D’abord, un réseau d’images profond appelé ResNet-50 analyse les images des caméras pour saisir la situation globale — l’encombrement de la route, l’emplacement des voies visibles et la disposition de la scène. En parallèle, un modèle 3D nommé PointPillars exploite les nuages de points LiDAR pour localiser véhicules et autres objets en trois dimensions. Ces signaux sont ensuite injectés dans un Transformer, un type d’IA initialement conçu pour le langage, qui excelle à comprendre les évolutions dans le temps. Ici, il apprend à prédire comment les voitures proches et les autres objets mobiles vont probablement se déplacer au cours des prochaines secondes, en tenant compte à la fois de leurs mouvements passés et de la structure de la route.
Construire une piste d’essai virtuelle et sûre
Plutôt que de tester des situations risquées directement sur la voie publique, les chercheurs connectent leur système à un jumeau numérique — une réplique virtuelle de rues réelles basée sur un large jeu de données public provenant de Boston et de Singapour. Dans ce monde simulé, les capteurs, les mouvements et l’environnement de la voiture sont rejoués et modifiés à volonté, tandis que l’IA tente de suivre les objets et de prévoir leurs trajectoires futures. Le système peut exécuter ces scénarios « et si ? » en temps réel, avec des temps de réponse inférieurs à 50 millisecondes, permettant aux ingénieurs d’explorer des cas limites tels que freinages soudains, virages serrés ou intersections encombrées sans mettre personne en danger.
Regarder à l’intérieur de la « boîte noire » de l’IA
Une critique fréquente de l’apprentissage profond est qu’il peut être difficile de comprendre pourquoi le modèle a pris une décision particulière. Pour y remédier, les auteurs utilisent une méthode appelée Grad-CAM, qui met en évidence les parties d’une image ayant le plus influencé la sortie du modèle. Ces cartes de chaleur montrent, par exemple, si le réseau se concentre sur un autre véhicule, un piéton ou une marquage de voie lorsqu’il estime des trajectoires. Bien que cette étape d’explication s’exécute hors ligne et non dans la boucle temps réel de la voiture, elle aide les ingénieurs et les évaluateurs de sécurité à vérifier que le système prête attention aux bons indices, ce qui est crucial pour instaurer la confiance du public.
À quel point conduit-il mieux ?
Testé sur des centaines de scènes urbaines, le cadre proposé détecte les objets 3D avec précision et prédit les mouvements plus finement que des règles physiques simples supposant une vitesse constante ou une accélération régulière. Ses erreurs de prévision — l’écart entre les positions prédites et la réalité — sont sensiblement plus faibles que celles de tels modèles de référence et proches d’un solide modèle récurrent d’IA, tout en restant suffisamment rapides pour une utilisation en temps réel. Des expériences soignées comparant différentes architectures montrent qu’un modèle d’image plus profond et un détecteur 3D de profondeur moyenne offrent le meilleur compromis entre précision et rapidité, et que le système peut être déployé sur des ordinateurs embarqués plus modestes après compression des modèles.
Ce que cela signifie pour les conducteurs au quotidien
Pour les non-spécialistes, le message est que des voitures autonomes plus sûres et plus fiables sont susceptibles d’émerger d’une approche qui combine plusieurs capteurs, prédit l’évolution de la scène et est testée rigoureusement dans des mondes virtuels réalistes. En réunissant perception, prédiction, simulation et explications compréhensibles par les humains dans une même conception, ce travail rapproche les véhicules autonomes d’un comportement de partenaires prudents et transparents sur la route plutôt que d’appareils mystérieux.
Citation: Almadhor, A., Al Hejaili, A., Alsubai, S. et al. A multimodal learning and simulation approach for perception in autonomous driving systems. Sci Rep 16, 5505 (2026). https://doi.org/10.1038/s41598-026-35095-3
Mots-clés: conduite autonome, fusion de capteurs, prédiction de trajectoire, détection d’objets 3D, simulation jumeau numérique