Clear Sky Science · fr
Un modèle d’évaluation intelligent hybride pour l’enseignement de la traduction en anglais avec BERT et SVM améliorés
Pourquoi une notation de traduction plus intelligente importe
Chaque année, les enseignants de langues passent d’innombrables heures à corriger des traductions d’élèves. Décider si une phrase est « suffisamment bonne » est lent, subjectif et peut varier considérablement d’un enseignant à l’autre. Cet article examine si l’intelligence artificielle peut partager cette charge — en fournissant des notes rapides et cohérentes et des indications sur les erreurs — sans remplacer l’enseignant. Il présente un nouveau modèle informatique, appelé BERT-SVM EduScore, conçu spécifiquement pour juger la qualité des traductions en anglais dans un contexte éducatif.
Du simple appariement de mots à une compréhension plus profonde
Pendant des décennies, les ordinateurs ont évalué les traductions principalement en comptant combien de mots ou de courtes expressions correspondent à une réponse de référence. Des outils bien connus comme BLEU ou METEOR font cela très rapidement, mais ils peinent face à la flexibilité du langage naturel : deux phrases peuvent exprimer la même idée avec des formulations très différentes. En classe, où les étudiants expérimentent synonymes et structures variées, ces métriques anciennes peuvent pénaliser à tort des paraphrases valides et fournir peu d’informations sur des erreurs spécifiques. Les chercheurs se sont donc tournés vers des méthodes plus récentes qui comparent les sens plutôt que les formes de surface, en utilisant de puissants modèles de langage entraînés sur d’énormes corpus de textes.
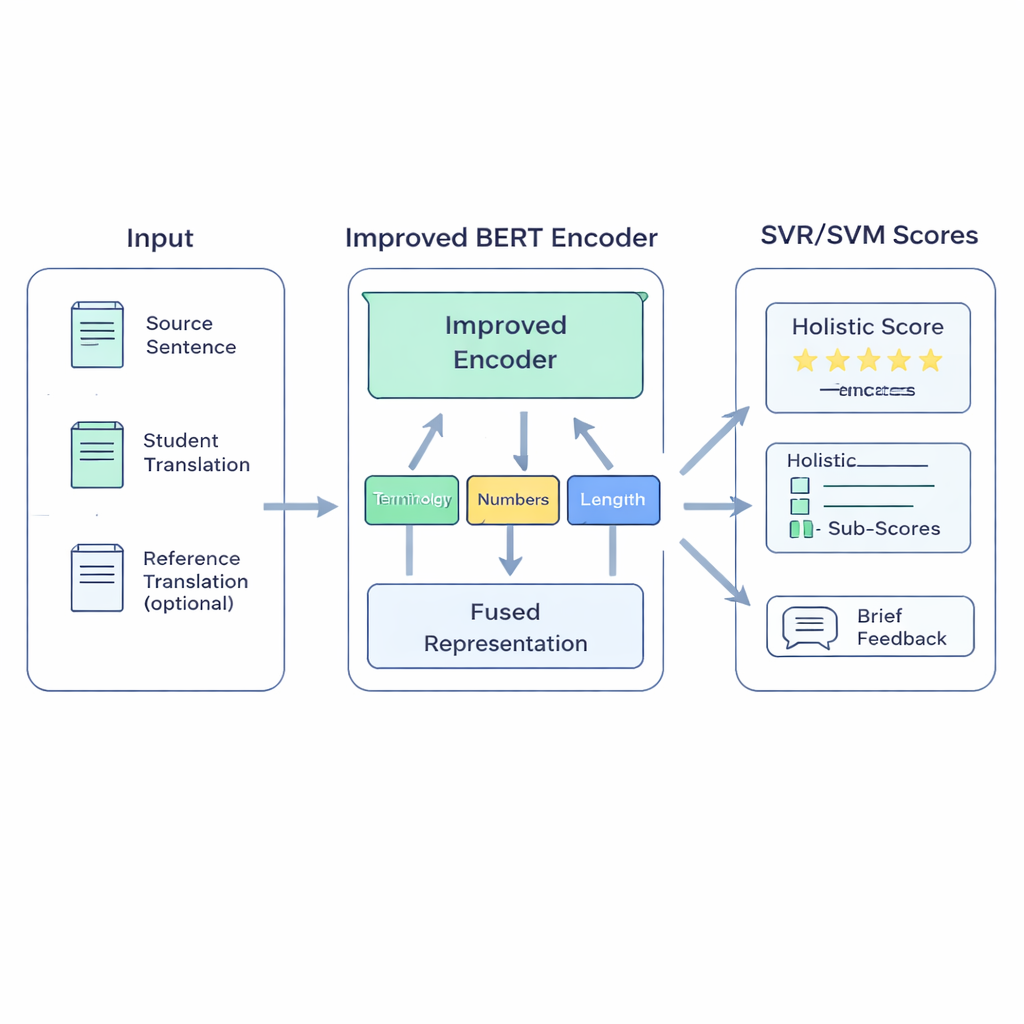
Un modèle hybride conçu pour la salle de classe
Le système proposé BERT-SVM EduScore combine deux idées : une compréhension profonde du langage et des statistiques classiques robustes. D’abord, il utilise une version améliorée du modèle de langage BERT pour lire trois éléments de texte : la phrase d’origine, la traduction de l’élève et, lorsque disponible, une traduction de référence. BERT transforme ces éléments en un riche résumé numérique qui reflète non seulement quels mots apparaissent, mais aussi dans quelle mesure les sens concordent. Par-dessus cela, le système ajoute un petit ensemble de contrôles manuels qui importent aux enseignants — par exemple si les termes techniques sont traduits de manière cohérente, si les nombres et unités sont préservés, si la ponctuation est raisonnable et si la longueur de la traduction correspond à l’original.
Comment le système apprend à noter comme un enseignant
Ces signaux sont ensuite alimentés dans des machines à vecteurs de support, une famille d’algorithmes réputée pour bien fonctionner avec des données limitées. Une partie prédit une note globale ; d’autres parties peuvent produire des notes distinctes pour des domaines comme l’exactitude ou la fluidité, ou classer les traductions en paliers de qualité. Pour aider le modèle à s’adapter au langage de type scolaire, les auteurs réentraîneront d’abord BERT sur des textes similaires au travail des élèves — une approche appelée adaptation de domaine. Ils affinent ensuite la capacité de BERT à discerner similitude et différence en le faisant s’exercer à distinguer des versions correctes et des versions légèrement altérées de phrases. Enfin, lorsque des métriques automatiques de haute qualité comme COMET ou BLEURT sont disponibles, le système apprend à imiter certains de leurs jugements, empruntant leurs forces tout en restant accordé aux évaluations humaines.
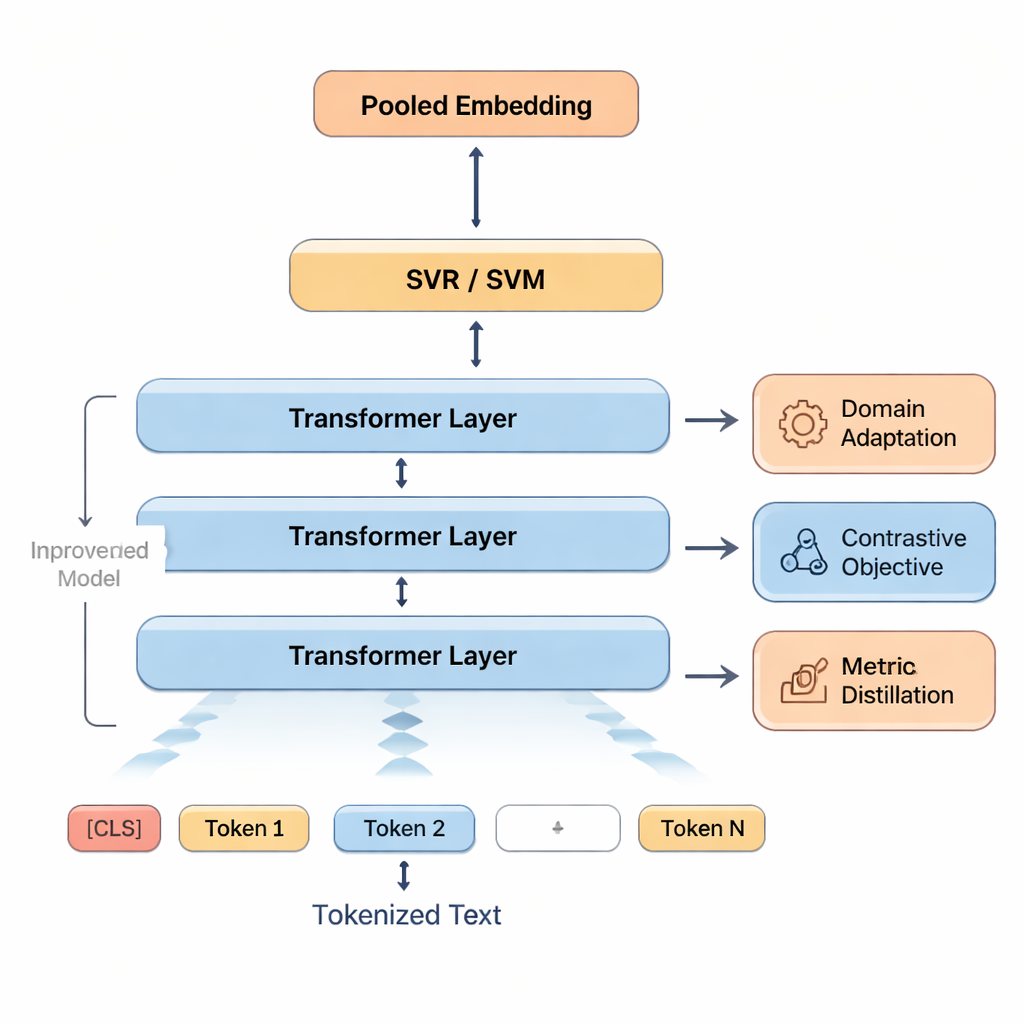
Mettre le modèle à l’épreuve
Les chercheurs évaluent BERT-SVM EduScore sur un large jeu de données public contenant des traductions automatique anglais–chinois notées par des humains. Bien qu’il ne s’agisse pas de devoirs d’élèves, leurs notations au niveau de la phrase ressemblent à des corrections en classe et fournissent un test de stress réaliste. Le nouveau système est comparé aux scores traditionnels basés sur les mots, aux nouveaux scores basés sur le sens et à plusieurs modèles neuronaux performants. Il ne se contente pas de mieux s’aligner sur les jugements humains — montrant un accord plus élevé et des erreurs moyennes plus faibles — il s’exécute aussi assez rapidement pour traiter environ 44 phrases par seconde sur du matériel graphique standard. Des expériences soignées montrent que l’adaptation de BERT au type de texte approprié apporte le gain le plus important, tandis que les astuces d’apprentissage supplémentaires fournissent des améliorations régulières et plus modestes sans ralentir notablement le système.
Ce que cela pourrait signifier pour enseignants et élèves
En termes simples, l’étude montre qu’un hybride soigneusement conçu de deep learning et de méthodes classiques peut noter les traductions plus fiablement que les outils automatiques existants, tout en restant assez rapide pour un usage en temps réel en classe. BERT-SVM EduScore n’est pas encore un substitut prêt à l’emploi aux enseignants : il n’a été testé que sur des traductions automatiques, pas sur de véritables travaux d’élèves, et il n’a pas subi d’essais en classe ni de vérifications d’équité. Mais les résultats suggèrent qu’un tel système pourrait bientôt aider les enseignants en fournissant des notes stables et en mettant en évidence les problèmes probables — comme une terminologie mal traduite ou des nombres manquants — afin que les retours humains puissent se concentrer sur des aspects plus profonds et créatifs de la traduction.
Citation: Lin, C. A hybrid intelligent assessment model for English translation education with improved BERT and SVM. Sci Rep 16, 5466 (2026). https://doi.org/10.1038/s41598-026-35042-2
Mots-clés: évaluation de la traduction, enseignement des langues, BERT, machines à vecteurs de support, estimation de la qualité