Clear Sky Science · fr
Sélection de caractéristiques hybride avec un nouveau modèle d’apprentissage profond pour la prédiction du risque COVID-19
Pourquoi prédire le risque COVID-19 reste important
Même si le monde apprend à vivre avec le COVID-19, le virus n’a pas disparu. De nouveaux variants continuent d’émerger, les hôpitaux peuvent encore être sous tension et les personnes vulnérables restent exposées à un risque élevé de maladie grave ou de décès. Les médecins ont donc besoin de moyens rapides et fiables pour estimer la probabilité qu’un patient infecté devienne gravement malade. Cet article présente un nouveau modèle informatique qui utilise des données hospitalières et une intelligence artificielle avancée pour prédire le risque COVID-19 de manière plus précise, aidant potentiellement les cliniciens à décider qui nécessite une surveillance plus étroite, un traitement précoce ou des soins intensifs.
Des dossiers patients bruts à des signaux exploitables
L’étude commence par un très grand jeu de données cliniques : plus d’un million de patients anonymes, chacun décrit par 21 caractéristiques simples, pour la plupart binaires, telles que la tranche d’âge, les comorbidités et d’autres facteurs de risque. Les données hospitalières du monde réel sont désordonnées, donc la première étape consiste à les « nettoyer ». Les auteurs appliquent une astuce mathématique appelée mise à l’échelle logarithmique, qui comprime les valeurs extrêmes et étire les amas de très petites valeurs. Cette transformation rend les données plus stables et plus faciles à traiter par les algorithmes, réduisant la probabilité que des valeurs inhabituelles ou des indicateurs rares induisent le modèle en erreur.
Choisir les signes les plus révélateurs
Toute variable enregistrée n’est pas également utile pour la prédiction, et un trop grand nombre de signaux faibles peut en réalité embrouiller un système d’intelligence artificielle. Les chercheurs réalisent donc une sélection de caractéristiques, un processus qui filtre les informations moins utiles et conserve les facteurs les plus informatifs. Leur approche hybride combine deux idées : une mesure évalue la capacité d’une caractéristique à séparer les patients à haut risque des patients à faible risque, et une autre vérifie à quel point les caractéristiques se recouvrent entre elles. En équilibrant ces deux points de vue sur une échelle commune, la méthode favorise les caractéristiques à la fois puissantes et non redondantes. Cet élagage accélère l’entraînement, réduit le surapprentissage et concentre le modèle sur les motifs cliniquement les plus pertinents.
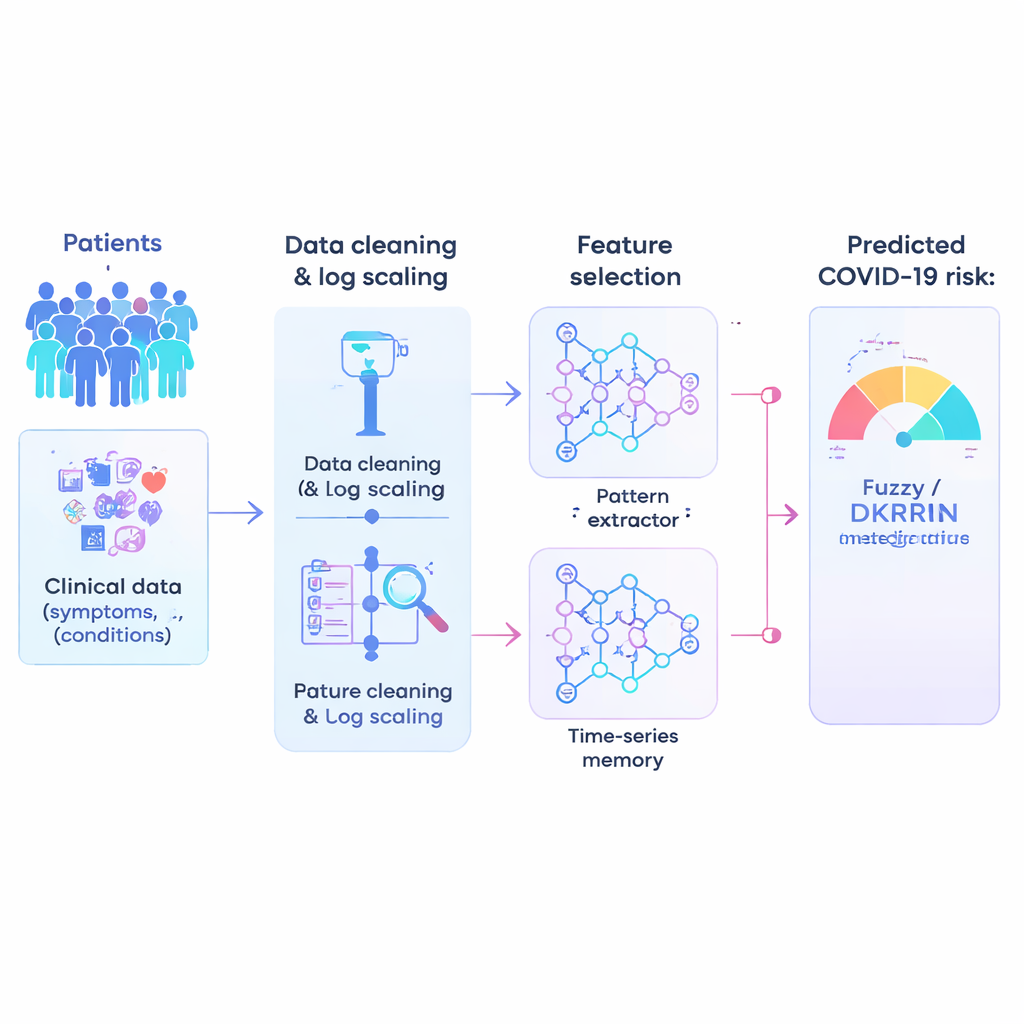
Mélanger reconnaissance de motifs et raisonnement flou
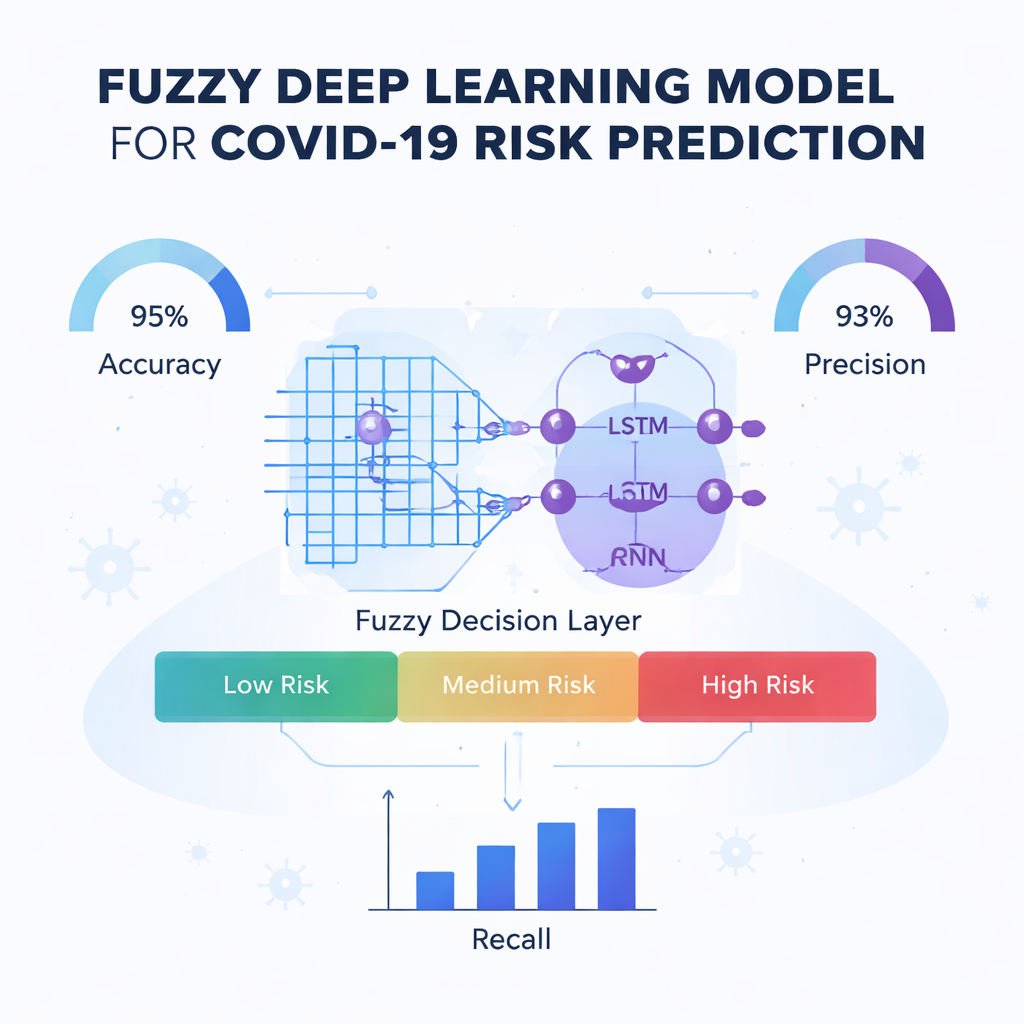
Le cœur de l’article est un nouveau moteur de prédiction appelé Fuzzy-Deep Kronecker Recurrent Neural Network, ou Fuzzy-DKRNN. Il combine plusieurs techniques complémentaires. Un composant, un Deep Kronecker Network, est conçu pour découvrir des motifs compacts et structurés cachés dans les données cliniques. Un autre composant, un réseau récurrent profond, est bien adapté pour capturer des dépendances et des tendances, par exemple lorsque la combinaison de facteurs au fil du temps influence le risque. Par-dessus ces éléments, les auteurs superposent un système de logique floue. Plutôt que de ne prendre que des décisions nettes oui/non, les règles floues expriment des assertions telles que « si plusieurs indicateurs de risque sont modérément élevés, le patient est probablement à haut risque ». Chaque règle porte un degré de certitude, permettant au modèle de gérer l’incertitude et les zones grises fréquentes en médecine.
Quelle est la performance du modèle ?
Les auteurs testent rigoureusement leur modèle Fuzzy-DKRNN face à plusieurs alternatives de pointe, y compris des systèmes basés sur des radiographies thoraciques, des méthodes d’apprentissage automatique traditionnelles et d’autres approches d’apprentissage profond. En utilisant des mesures standard telles que la précision, la précision positive, le rappel et le score F1, leur méthode se classe systématiquement en tête. Dans sa meilleure configuration, le modèle classe correctement environ 91 % des cas au total, avec une forte capacité à la fois à détecter les patients qui deviendront gravement malades et à éviter les fausses alertes chez ceux qui ne le deviendront pas. Ces gains se maintiennent lorsque la quantité de données d’entraînement et les paramètres de validation interne varient, ce qui suggère que l’approche est robuste plutôt que finement adaptée à un scénario spécifique.
Ce que cela signifie pour les patients et les hôpitaux
En termes simples, ce travail montre que combiner un nettoyage soigneux des données, une sélection intelligente des principaux facteurs de risque et un hybride d’apprentissage profond avec logique floue peut produire des prédictions de risque COVID-19 plus fiables à partir d’informations cliniques de routine. Un tel outil ne remplacera pas les médecins, mais il pourrait servir d’assistant d’alerte précoce — signalant les patients qui méritent une surveillance accrue, guidant la répartition de ressources rares comme les lits de soins intensifs et, en fin de compte, contribuant à réduire les décès évitables. La même stratégie pourrait également être adaptée à d’autres maladies où la détection précoce du risque à partir de données cliniques complexes est cruciale.
Citation: P, G.S., Kathiravan, M., Shanthi, S. et al. Hybrid feature selection with novel deep learning model for COVID-19 risk prediction. Sci Rep 16, 4106 (2026). https://doi.org/10.1038/s41598-026-35013-7
Mots-clés: Prédiction du risque COVID-19, apprentissage profond, logique floue, support à la décision clinique, modèles d’IA médicaux