Clear Sky Science · fr
Améliorer la prédiction géochimique de l’or censurée par des modèles spatiaux bayésiens et Random Forest avec une séparation du fond basée sur les fractales
Pourquoi de minuscules traces d’or sont importantes
Lorsque les géologues recherchent de nouveaux gisements d’or, ils travaillent souvent avec des échantillons de sol contenant seulement quelques parties par milliard du métal précieux. Ces valeurs ultra-faibles sont si proches des limites de détection des instruments de laboratoire que de nombreuses mesures sont simplement indiquées comme « inférieures à la détection ». Si ces traces presque invisibles sont mal traitées, des zones minérales prometteuses peuvent être manquées ou cartographiées de façon inexacte. Cette étude présente une méthode plus intelligente pour récupérer l’information contenue dans ces valeurs censurées, aidant les explorateurs à discerner des motifs souterrains plus clairs à partir de données limitées et bruyantes.
Signaux cachés dans des mesures imparfaites
La chimie des sols et des roches est un outil clé pour l’exploration minérale parce que de faibles variations chimiques peuvent signaler des corps minéralisés enfouis. Mais les instruments ne peuvent pas mesurer des quantités infiniment petites. Pour l’or dans cette étude, tout échantillon en-dessous de quelques parties par milliard a été traité comme censuré : le laboratoire pouvait seulement indiquer que la valeur réelle se situait sous cette limite. Des solutions rapides et courantes remplacent simplement tous ces résultats par un nombre constant, comme la moitié de la limite de détection. Bien que commode, cette pratique aplatie la variation naturelle, brouille les anomalies subtiles et déforme la relation de l’or avec d’autres éléments comme le cuivre. Les auteurs soutiennent que, pour lire véritablement les empreintes chimiques de la Terre, il faut conserver l’incertitude associée à ces faibles valeurs plutôt que de l’écraser.
De la carte géologique à un fond plus propre
La recherche se concentre sur un prospect cuivre–or dans la zone du Northern Dalli au centre de l’Iran, où 165 échantillons de sol ont été prélevés sur une grille serrée au-dessus d’un système porphyrique connu. L’or a été mesuré avec 29 autres éléments, et 14 échantillons étaient inférieurs à une limite de détection supposée de 5 parties par milliard. Plutôt que d’alimenter directement tous les données dans un modèle, l’équipe a d’abord utilisé une méthode « fractal » concentration–nombre pour séparer les valeurs de fond des anomalies plus marquées. En analysant comment le nombre d’échantillons évolue avec l’augmentation de la concentration d’or sur un graphe log–log, ils ont identifié des seuils séparant le fond, les faibles anomalies et les fortes anomalies. Seule la population de fond — incluant les valeurs censurées — a servi à construire les modèles de prédiction, réduisant le risque que quelques échantillons à haute teneur ne dominent l’apprentissage.
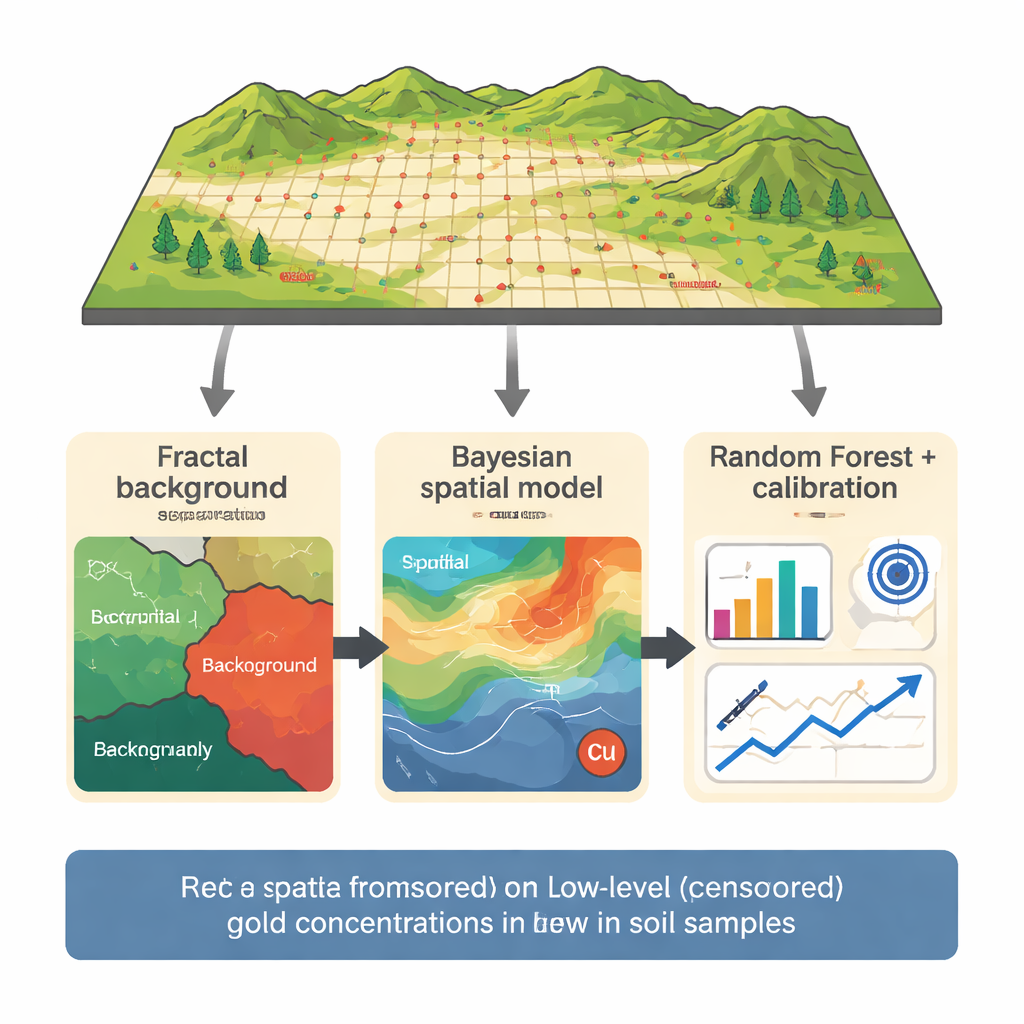
Une carte probabiliste guidée par le cuivre
Pour estimer la teneur réelle en or des échantillons censurés, les auteurs ont ensuite appliqué un modèle bayésien de champ aléatoire gaussien, une approche spatiale probabiliste. Ce modèle considère la concentration en or comme un champ variant en douceur sur la carte, influencé à la fois par la position et par la teneur en cuivre, fortement corrélée à l’or dans ce contexte porphyrique. Plutôt que de deviner un unique nombre pour chaque point censuré, le modèle produit une courbe de probabilité complète qui respecte le fait que la valeur réelle doit se situer sous la limite de détection. Le résultat est un ensemble d’estimations optimales et d’intervalles d’incertitude pour les 14 échantillons censurés, compatibles avec les mesures voisines et avec le lien observé entre or et cuivre dans les roches.
Apprentissage automatique, ajusté là où cela compte
Ces estimations probabilistes alimentent ensuite un modèle Random Forest, une méthode d’apprentissage automatique qui combine de nombreux arbres de décision. Le modèle utilise l’or, le cuivre, le fer, le nickel, le titane et le bore de la population de fond pour apprendre des motifs, avec une validation croisée soigneuse de sorte que chaque échantillon soit testé uniquement contre des modèles qui ne l’ont pas vu auparavant. Les prédictions initiales avaient encore tendance à être un peu trop élevées près de la limite de détection, un problème courant quand peu de valeurs très faibles sont disponibles. Pour corriger cela, les auteurs ont réalisé une calibration ciblée visant spécifiquement la plage 5–8 parties par milliard, puis appliqué une simple étape d’échelle pour garantir que les prédictions ajustées restent dans des limites physiquement significatives. Cette chaîne en trois étapes — séparation fractale, estimation spatiale bayésienne et Random Forest calibré — a produit des prédictions correspondant bien mieux aux faibles teneurs réelles en or que les approches standard.
Détrôner les vieux raccourcis
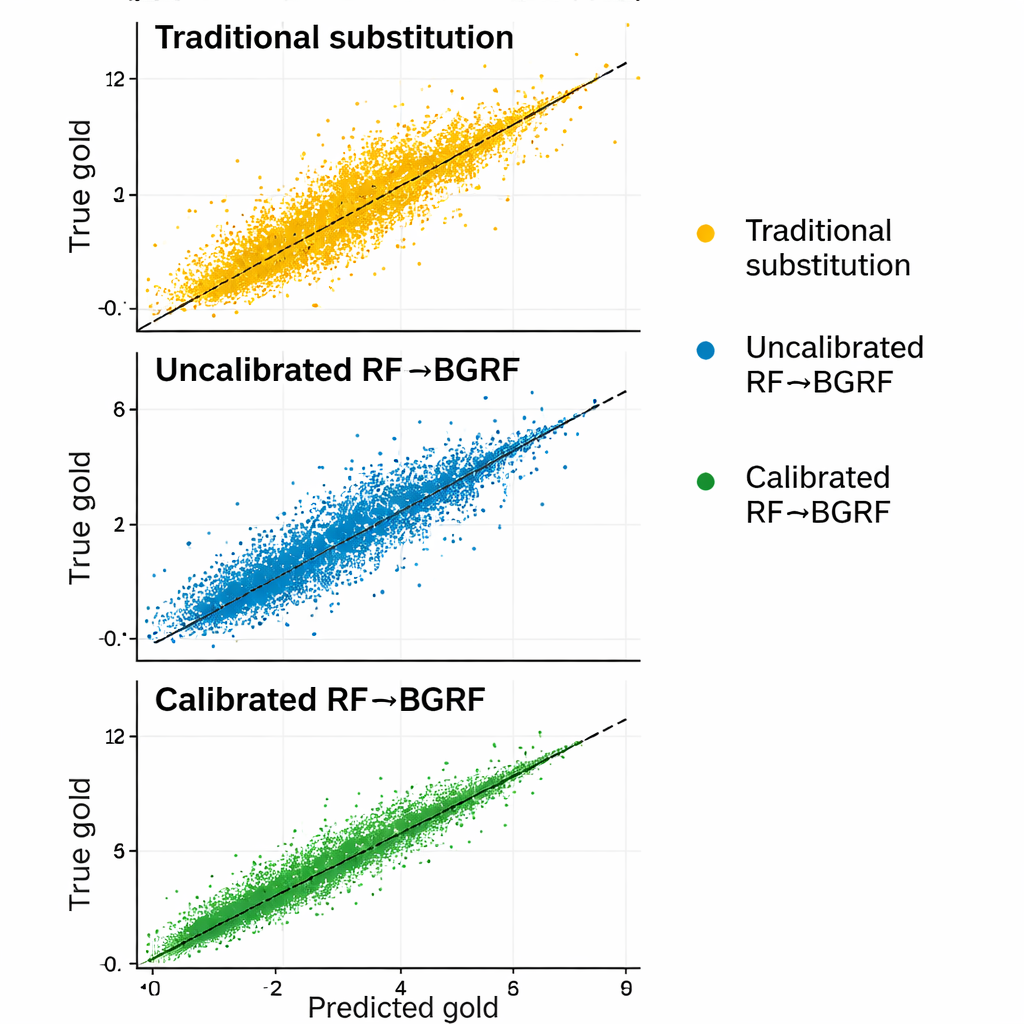
L’étude a comparé le nouveau cadre à la fois à un Random Forest basique et à deux règles classiques de substitution qui remplacent les résultats censurés par des fractions fixes de la limite de détection. Selon plusieurs mesures d’erreur, le modèle hybride calibré et mis à l’échelle était le plus précis et le moins biaisé, en particulier pour les échantillons proches de la limite de détection où de petites erreurs ont le plus d’impact. Il a aussi préservé une variation réaliste et maintenu des relations raisonnables entre or et cuivre, alors que le remplacement par une constante unique pour toutes les valeurs censurées détruisait cette structure. Pour certains échantillons censurés de niveau supérieur, l’erreur relative de la nouvelle méthode était des centaines de fois plus faible que celle des substitutions traditionnelles.
Images chimiques plus nettes pour l’exploration
Pour les non-spécialistes, la conclusion est que la façon dont nous traitons les valeurs « inférieures à la détection » dans les données géochimiques peut faire ou défaire la recherche de nouveaux gisements minéraux. Plutôt que d’effacer l’incertitude avec des remplacements grossiers, ce travail montre que la combinaison de la modélisation spatiale probabiliste, de l’apprentissage automatique et d’une calibration simple peut récupérer une grande partie de l’information cachée dans des mesures de faible niveau. Le résultat est des cartes plus propres des motifs aurifères subtils, une détection d’anomalies plus fiable et, en fin de compte, une meilleure chance de trouver des corps minéralisés avec moins de forages et des données plus honnêtes.
Citation: Mahdiyanfar, H. Advancing censored geochemical Au prediction through Bayesian spatial models and Random Forest with fractal-based background separation. Sci Rep 16, 4763 (2026). https://doi.org/10.1038/s41598-026-34999-4
Mots-clés: exploration géochimique, données censurées, anomalies aurifères, modélisation spatiale bayésienne, apprentissage automatique en géologie