Clear Sky Science · fr
Prédiction de survie inter-cancers à l’aide de modèles d’apprentissage automatique
Pourquoi il est important de prédire la survie du cancer autrement
Les patients atteints de cancer et leurs familles posent souvent une question simple mais déchirante : « Combien de temps me reste‑t‑il ? » Les médecins tentent de répondre en s’appuyant sur leur expérience et des données passées, mais pour de nombreux cancers rares il n’existe tout simplement pas suffisamment de cas comparables pour fournir des prévisions précises. Cette étude examine si des programmes informatiques modernes peuvent « emprunter » en toute sécurité l’expérience de cancers fréquents pour aider à prévoir la survie des cancers moins courants, offrant potentiellement à davantage de patients des attentes plus claires et des soins mieux adaptés. 
Utiliser les patients passés pour orienter les soins futurs
Les chercheurs ont travaillé avec un vaste ensemble de données du monde réel provenant des registres de cancer des hôpitaux de São Paulo, au Brésil. Ces dossiers couvrent plus d’un million de patients traités entre 2000 et 2019 et comprennent des détails tels que l’âge, le stade tumoral, les traitements reçus et si la personne était encore en vie trois ans après le diagnostic. Se concentrer sur ce seuil des trois ans a permis à l’équipe de comparer des cancers aux durées de vie typiques très différentes tout en évitant des jeux de données extrêmement déséquilibrés, où presque tout le monde survit ou meurt.
Enseigner aux ordinateurs à repérer les motifs de survie
Pour transformer ce registre en outil de prédiction, les auteurs ont utilisé deux méthodes d’apprentissage automatique populaires, XGBoost et LightGBM. Ces méthodes n’essaient pas de comprendre la biologie directement ; elles passent plutôt au crible des milliers d’histoires de patients pour trouver des motifs liant des caractéristiques comme le stade de la maladie et le moment des traitements à la survie ultérieure. D’abord, l’équipe a construit des modèles « spécialistes », chacun entraîné uniquement sur un type de cancer, par exemple le sein, le poumon ou l’estomac. Ils ont ensuite évalué la capacité de ces modèles à prédire la survie à trois ans pour de nouveaux patients atteints du même cancer, en utilisant des mesures standard qui équilibrent l’identification correcte des survivants et des non‑survivants.
Un cancer peut‑il aider à prédire un autre ?
Le cœur de l’étude pose une question audacieuse : un modèle entraîné sur un type de cancer peut‑il prédire avec succès la survie d’un cancer différent ? Pour tester cela, les chercheurs ont regroupé les cancers de deux manières : les cancers les plus fréquents (peau, sein, prostate, colorectal, poumon et col de l’utérus) et les cancers du système digestif (cavité buccale, oropharynx, œsophage, estomac, petit intestin, colorectal et anus). Dans une première phase, ils ont entraîné des modèles distincts pour chaque cancer et les ont testés sur les autres, ne retenant que les appariements où la survie et la non‑survie étaient prédites avec un équilibre raisonnable. Dans les phases suivantes, ils ont fusionné les données de cancers sélectionnés en jeux d’entraînement partagés, créant des modèles plus généraux qui s’appuyaient sur des motifs communs à des tumeurs apparentées. 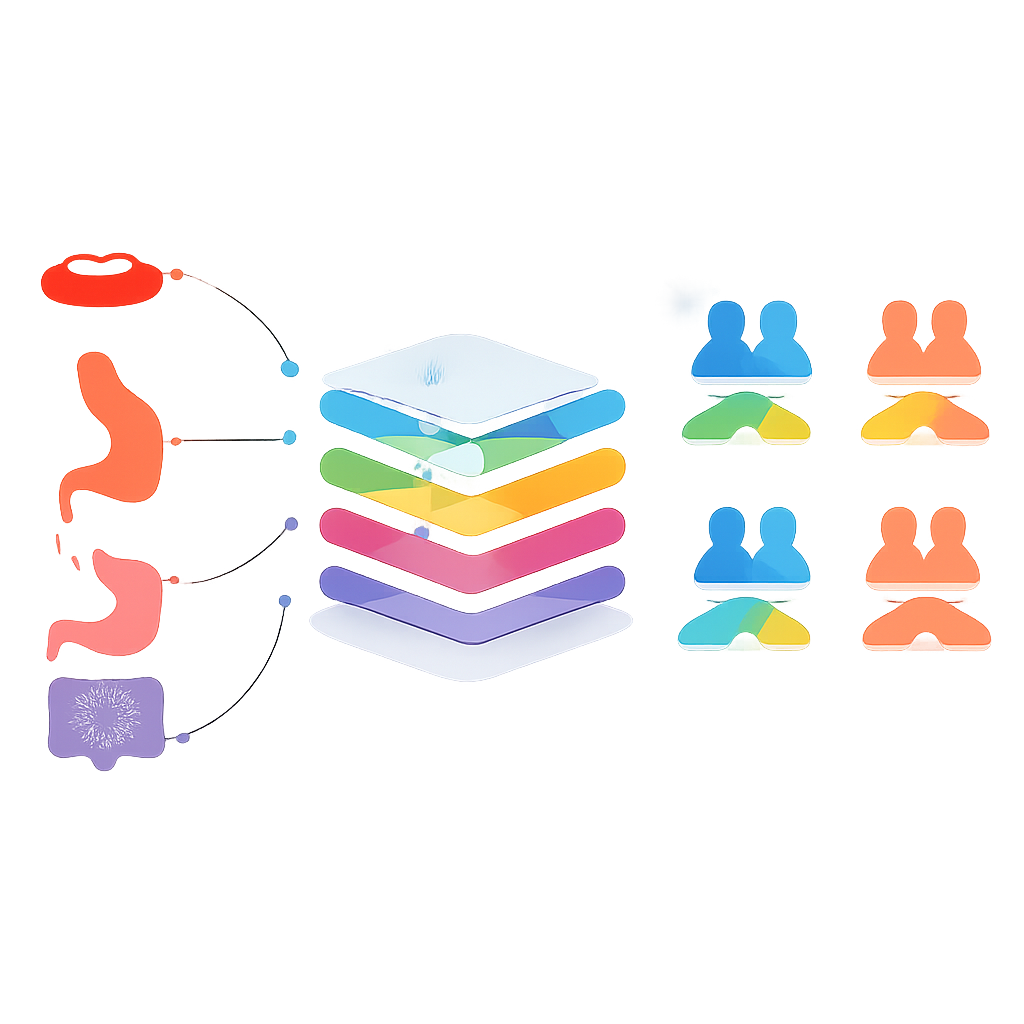
Où l’apprentissage inter‑cancers aide — et où il ne le fait pas
Pour les cancers courants, la combinaison des données entre types n’a pas surpassé les meilleurs modèles spécialistes. Un modèle unique entraîné sur les six cancers courants, par exemple, prédisait moins précisément que des modèles adaptés à chaque cancer séparément. L’histoire était différente pour certains cancers du système digestif. Lorsque les données des cancers de la cavité buccale, de l’œsophage et de l’estomac ont été regroupées, le modèle résultant a prédit la survie à trois ans pour le cancer de l’estomac légèrement mieux que le modèle spécifique à l’estomac, avec une exactitude équilibrée juste au‑dessus de 80 %. Cependant, des tests statistiques ont montré que cette amélioration n’était pas clairement différente du hasard, ce qui signifie que le modèle partagé et le modèle spécialiste étaient essentiellement à égalité. Des résultats similaires « presque mais pas tout à fait meilleurs » sont apparus pour les cancers de la cavité buccale, du petit intestin et colorectal, souvent avec des compromis entre l’identification correcte des survivants et celle des non‑survivants.
Ce que cela signifie pour les patients atteints de cancers rares
Même si les modèles inter‑cancers ont rarement surpassé les meilleurs modèles spécifiques à une maladie, ils s’en approchaient souvent — en n’utilisant que des informations empruntées à d’autres types de cancer. Pour les cancers rares qui manquent de grands jeux de données de haute qualité, c’est un signe encourageant : à l’avenir, les médecins pourraient s’appuyer sur des modèles entraînés sur des cancers plus fréquents pour proposer des estimations de survie utiles lorsque des outils spécialisés sont impossibles à construire. Les auteurs avertissent que ces méthodes ne sont pas encore prêtes pour un usage clinique courant, et qu’elles doivent être testées dans d’autres régions et combinées à des données biologiques plus approfondies. Pourtant, ce travail fait entrevoir un avenir où aucun patient ne serait privé d’orientation simplement parce que son cancer est peu commun.
Citation: Cardoso, L.B., Egydio, J.E., Toporcov, T.N. et al. Cross-cancer survival prediction using machine learning models. Sci Rep 16, 9623 (2026). https://doi.org/10.1038/s41598-025-34133-w
Mots-clés: prédiction de survie du cancer, apprentissage automatique en oncologie, modélisation inter-cancers, cancers rares, registres cliniques