Clear Sky Science · fr
Calcul du score de similarité de phrases par apprentissage profond hybride avec un accent particulier sur les phrases négatives
Pourquoi le sens des mots compte pour une correction équitable
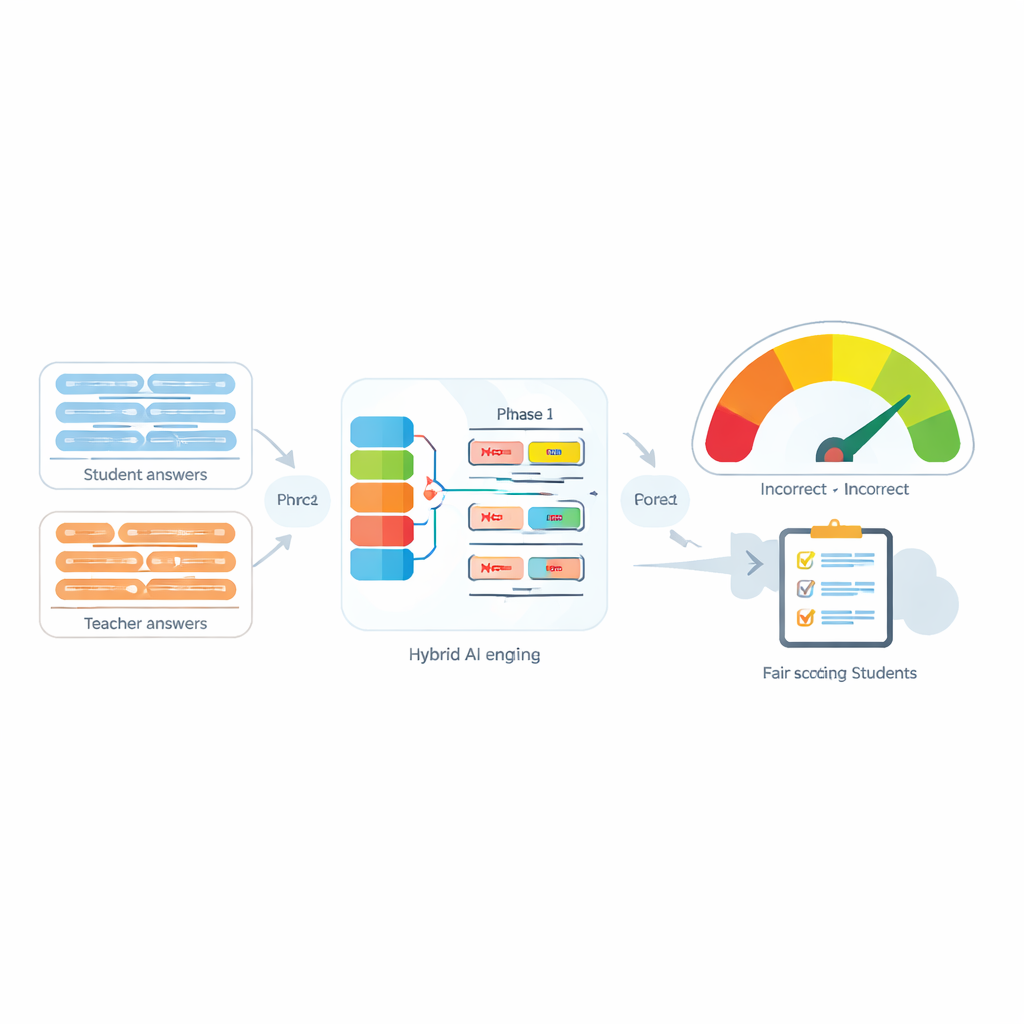
Lorsque des étudiants répondent avec leurs propres mots, les systèmes informatiques qui aident les enseignants à noter ces réponses doivent comprendre plus que des mots-clés partagés. Un petit mot comme « pas » peut inverser le sens d’une phrase, et si les systèmes automatisés ne détectent pas cette inversion, des étudiants peuvent être notés injustement. Cet article s’attaque à ce problème en concevant une nouvelle méthode permettant aux ordinateurs de comparer le sens des phrases tout en portant une attention particulière à la façon dont les mots de négation modifient ce qui est dit.
Le défi des petits mots au grand impact
Les systèmes d’évaluation automatique sont de plus en plus utilisés pour alléger la charge des enseignants en comparant la réponse d’un étudiant à une réponse-modèle. De nombreux outils modernes procèdent en transformant chaque phrase en une « empreinte » numérique puis en mesurant la proximité entre ces empreintes. Ces outils fonctionnent raisonnablement bien en l’absence de négation, mais échouent souvent lorsque des mots comme « pas », « jamais » ou « non » apparaissent. Par exemple, « La méthode est précise » et « La méthode n’est pas précise » peuvent finir par paraître étonnamment similaires à l’ordinateur, alors qu’elles ont des sens opposés. Les auteurs montrent que non seulement la présence de la négation, mais aussi le nombre de mots de négation et leur position dans la phrase peuvent changer complètement le sens voulu.
Construire un jeu de données qui enseigne la nuance
Pour entraîner un système qui comprend vraiment la négation, les auteurs avaient d’abord besoin de données mettant en évidence ces cas délicats. Ils ont créé le Negation-Sentence-Similarity Dataset, contenant 8 575 paires de phrases issues de quatre domaines de l’informatique : systèmes d’exploitation, bases de données, réseaux informatiques et apprentissage automatique. Pour chaque paire, des humains ont attribué un score de similarité tenant déjà compte de la négation. Le jeu de données enregistre aussi combien de mots de négation chaque phrase utilise et quel type de schéma de négation elle suit, comme un seul « pas », un nombre pair ou impair de négations, ou des cas plus complexes où la négation interagit avec des mots de liaison tels que « parce que » ou « mais ». Cet étiquetage détaillé fournit au modèle des indices explicites sur la manière dont la négation façonne le sens.
Un moteur hybride qui fusionne plusieurs points de vue
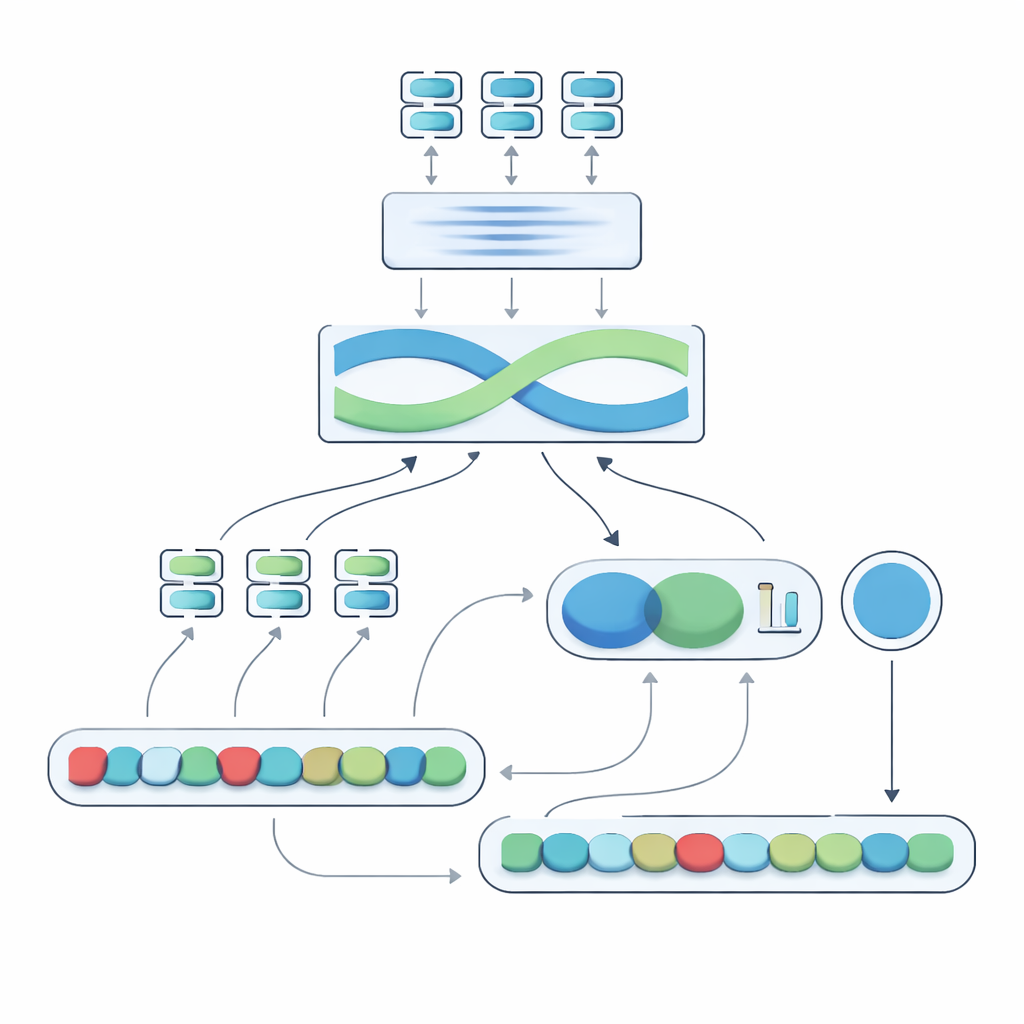
Le cœur du système proposé, appelé Negation-Aligned Similarity Scorer, est un moteur en deux phases. Dans la première phase, le système fait passer chaque phrase à travers plusieurs modèles de langage différents, chacun capturant des aspects légèrement différents du sens. Leurs sorties sont assemblées puis transmises à un réseau récurrent bidirectionnel qui considère la phrase dans son ensemble, prenant en compte l’ordre des mots et le contexte local. Cela produit un résumé compact de chaque phrase, mieux adapté aux tournures subtiles, y compris la position des mots de négation par rapport aux autres mots.
Apprendre au modèle à ressentir l’inversion provoquée par la négation
Dans la deuxième phase, le système compare les deux résumés de phrases et ajoute des informations explicites sur la négation. Il examine à quel point les résumés diffèrent, dans quelle mesure ils se recouvrent, et combine ces signaux avec trois caractéristiques simples : la différence du nombre de mots de négation, si les phrases ont un nombre impair ou pair de négations (ce qui peut inverser ou annuler le sens négatif), et si la négation apparaît à des positions à peu près correspondantes. Tous ces indices sont fusionnés dans un petit réseau de prédiction qui produit un score de similarité de 0 à 100. Entraîné de bout en bout sur le jeu de données constitué, ce score devient sensible à la façon dont la négation remodèle le sens plutôt que de traiter « pas » comme un simple mot de plus.
Quelle est la performance du nouveau score en pratique
Pour tester leur approche, les auteurs l’évaluent à la fois sur leur jeu de données personnalisé et sur une référence largement utilisée pour la similarité de phrases. Comparé à de solides modèles de référence basés sur des transformeurs utilisant des méthodes standard, le nouveau score obtient une erreur de prédiction plus faible et une qualité de classification bien supérieure, avec un F1 proche de 0,97. Dans des exemples choisis avec soin, il attribue de faibles scores de similarité lorsque la négation inverse clairement le sens et des scores élevés lorsque la double négation s’annule effectivement, tandis que les modèles concurrents ont encore tendance à surestimer la similarité. Une étude d’ablation confirme que les deux ingrédients clés — la couche récurrente sensible à la séquence et les caractéristiques explicites de négation — sont importants pour ce gain de performance.
Ce que cela signifie pour les étudiants et les outils futurs
Pour le lecteur non spécialiste, la conclusion est simple : la façon dont nous disons « pas » compte, et on peut apprendre aux machines à le remarquer. En mêlant plusieurs modèles de langage, un traitement contextuel et de simples comptes et positions des mots de négation, le score proposé offre une manière plus juste et plus fiable de juger si deux phrases signifient réellement la même chose. Cela peut aider les systèmes de notation automatique à éviter des erreurs graves, comme traiter « n’est pas autorisé » comme si c’était « est autorisé ». Bien que la méthode demande plus de ressources de calcul et se concentre encore sur des domaines techniques, elle ouvre la voie à des outils futurs qui capturent mieux la logique fine du langage courant, rendant les technologies automatiques du langage à la fois plus intelligentes et plus dignes de confiance.
Citation: M, R., L, J., Ummity, S.R. et al. Computation of sentence similarity score through hybrid deep learning with a special focus on negation sentence. Sci Rep 16, 8904 (2026). https://doi.org/10.1038/s41598-025-34084-2
Mots-clés: similarité de phrases, négation dans le langage, notation automatisée, traitement automatique du langage, modèles d'apprentissage profond