Clear Sky Science · fr
Recherche IP haute performance par accélération GPU pour soutenir un routage évolutif et efficace dans les réseaux de communication pilotés par les données
Pourquoi des voies Internet plus rapides comptent
Chaque photo que vous partagez, chaque vidéo que vous diffusez ou chaque message que vous envoyez doit traverser un dédale de carrefours numériques appelés routeurs. Chaque routeur doit décider rapidement où envoyer chaque paquet de données ensuite. Alors que l’usage mondial d’Internet explose, ces décisions se prennent des milliards de fois par seconde, et de très petits retards peuvent se traduire par une navigation plus lente ou des réseaux congestionnés. Cet article explore une nouvelle manière d’accélérer l’une des étapes les plus chronophages de ce processus décisionnel en exploitant la puissance parallèle massive des processeurs graphiques, les mêmes puces qui animent les jeux vidéo et l’IA, afin de maintenir les réseaux futurs rapides et évolutifs.
Le carnet d’adresses caché d’Internet
Au cœur de chaque routeur se trouve un énorme carnet d’adresses, appelé table de routage, qui associe des plages d’adresses IP au saut suivant du trajet. Lorsqu’un paquet arrive, le routeur doit rechercher l’entrée qui correspond le mieux à la destination du paquet, en appliquant la règle du « plus long préfixe correspondant » : parmi toutes les correspondances partielles, on choisit la plus spécifique. Les méthodes logicielles classiques stockent ces préfixes dans des structures arborescentes et les parcourent pas à pas. Cela fonctionne, mais à mesure que les tables atteignent des dizaines ou des centaines de milliers d’entrées, le processus devient plus lent et plus gourmand en mémoire, surtout sur des processeurs centraux ordinaires qui ne gèrent qu’un nombre limité de tâches simultanément.
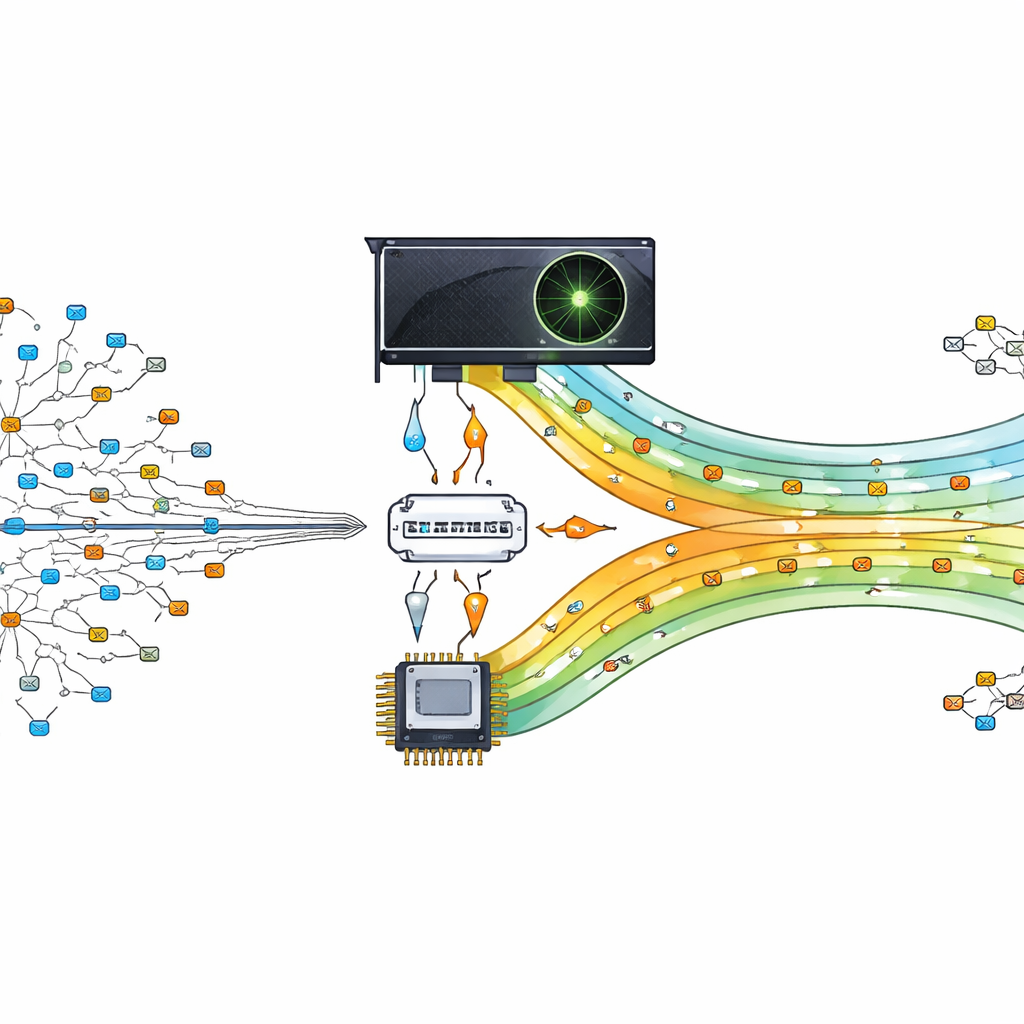
Transformer une puce graphique en agent de circulation
Les auteurs proposent de décharger ce lourd travail de recherche vers une unité de traitement graphique (GPU), une puce conçue pour exécuter des milliers de petites tâches en parallèle. Leur conception traite le GPU comme un assistant du processeur principal. Le processeur central prépare et organise la table de routage, puis envoie des versions compactes des données au GPU. Lorsque des paquets arrivent, leurs adresses de destination sont découpées et envoyées au GPU, où de nombreux threads recherchent simultanément la meilleure correspondance. En laissant des centaines ou des milliers de recherches se dérouler en parallèle, le routeur peut suivre le rythme des demandes de communication modernes, pilotées par les données.
Réduire les adresses pour accélérer les décisions
Un insight clé du travail est que des adresses plus courtes se recherchent plus vite. Plutôt que d’utiliser des adresses IP brutes, les auteurs les compressent à l’aide d’une méthode sans perte appelée codage de Huffman, qui attribue des codes plus courts aux motifs d’adresse les plus fréquents. Cela réduit le nombre moyen de bits nécessaires pour représenter chaque entrée, diminuant à la fois l’usage mémoire et la hauteur de la structure de recherche sous-jacente. Ils stockent ensuite les préfixes dans un arbre « multibit » qui examine plusieurs bits à la fois, plutôt qu’un seul, réduisant encore le nombre d’étapes nécessaires. Pour tirer parti des forces du GPU, ils transforment cet arbre en tableaux unidimensionnels simples, remplaçant les suivis de pointeurs complexes par des calculs d’indices réguliers que des milliers de threads peuvent exécuter efficacement.
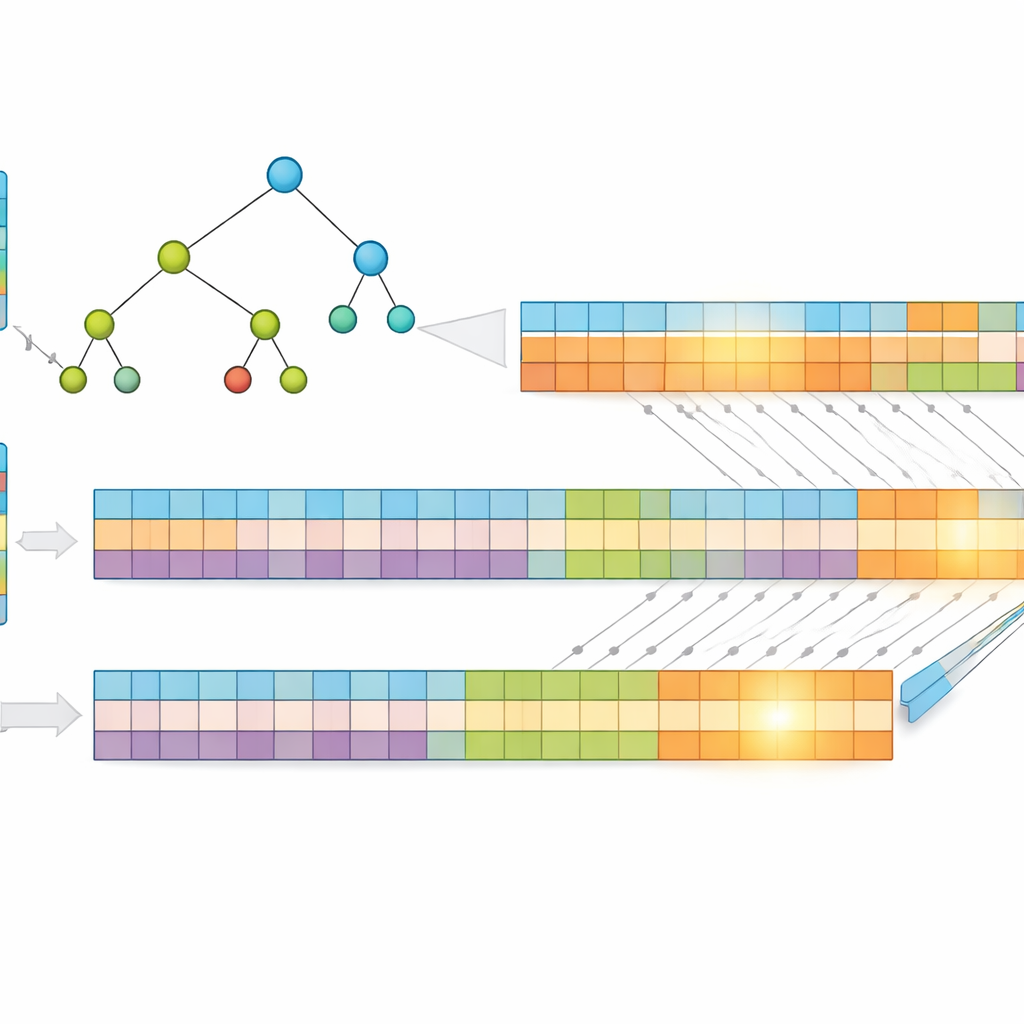
Diviser le problème pour un parallélisme massif
Pour pousser la performance plus loin, les chercheurs divisent chaque adresse compressée en deux moitiés égales et construisent deux arbres séparés — un pour la première moitié, un pour la seconde. Lorsqu’un paquet arrive, le GPU parcourt les deux arbres en parallèle. Chaque recherche renvoie un petit ensemble de correspondances possibles, et la réponse finale provient de l’intersection de ces ensembles pour trouver le préfixe partagé le plus spécifique. Parce que le travail est réparti et traité simultanément, le temps d’exécution dépend principalement de la longueur maximale du préfixe et du nombre de bits examinés par étape, et non du nombre d’entrées dans la table. Des tests utilisant de vraies données de routage Internet montrent que cette conception maintient un temps de recherche quasi constant même lorsque la table grandit.
Ce que révèlent les expériences
L’équipe a comparé leur méthode basée sur le GPU à une variété d’approches bien connues, y compris les arbres binaires classiques, les arbres compressés et d’autres schémas accélérés par GPU tels que le hachage et les arbres de recherche binaires. Sur des jeux de données de routage réels, leur système a délivré des gains spectaculaires : environ 83–91 % plus rapide que les méthodes arborescentes populaires basées sur processeur central, et 89–97 % plus rapide que les méthodes GPU antérieures. La compression a également réduit l’utilisation mémoire d’environ un tiers en moyenne, allégeant la pression sur la mémoire limitée sur puce et aidant à garder les structures de recherche du GPU peu profondes et efficaces. Fait important, les performances de la méthode sont restées stables quelle que soit la taille des tables de routage, soulignant son adéquation aux réseaux en croissance.
Ce que cela signifie pour les utilisateurs quotidiens
Pour un non‑spécialiste, la conclusion est que les auteurs montrent comment transformer une puce graphique en un agent de circulation très efficace pour les données Internet, en utilisant un rétrécissement et un découpage astucieux des informations d’adresse. En combinant compression, agencements d’arbres plus intelligents et recherche parallèle massive, leur approche trouve bien plus rapidement le meilleur chemin pour chaque paquet que de nombreuses techniques existantes, sans être ralentie à mesure que les carnets d’adresses d’Internet s’étendent. Bien que le travail soit démontré principalement pour le système d’adresses actuel, les mêmes idées pourraient être étendues à un espace d’adressage plus grand demain, contribuant à garder les services en ligne réactifs à mesure que notre appétit pour les données continue de croître.
Citation: Sonai, V., Bharathi, I., Alshathri, S. et al. High performance IP lookup through GPU acceleration to support scalable and efficient routing in data driven communication networks. Sci Rep 16, 9612 (2026). https://doi.org/10.1038/s41598-025-33233-x
Mots-clés: routage GPU, recherche IP, scalabilité réseau, transmission de paquets, informatique parallèle