Clear Sky Science · fr
Détection d'objets camouflés via une interaction hiérarchique sensible au contexte et à la texture
Pourquoi repérer les formes cachées est important
Des insectes couleur feuille aux camouflages militaires, en passant par les lésions difficiles à voir sur des examens médicaux, notre environnement regorge d'objets conçus pour se fondre dans le décor. Apprendre aux ordinateurs à détecter de manière fiable ces objets cachés pourrait aider à protéger la faune, améliorer les inspections de sécurité et aider les médecins à détecter les maladies plus tôt. Cet article présente un nouveau système d'intelligence artificielle, appelé CTHINet, qui apprend à voir à travers le camouflage en prêtant attention non seulement au contexte global de la scène mais aussi aux indices texturaux infimes que l'œil humain manque souvent.
Voir la forêt et les arbres
La détection d'objets camouflés est bien plus difficile que la détection d'objets ordinaire parce que la cible se confond souvent avec son environnement en couleur, luminosité et forme. Les méthodes informatiques antérieures s'appuyaient sur des indices simples conçus à la main, comme le mouvement, les contours ou une texture de base, qui échouent dans des scènes encombrées ou bruyantes. Les approches modernes par apprentissage profond ont progressé en entraînant de grands réseaux sur des collections d'images spécialisées d'animaux camouflés et d'objets artificiels. Nombre de ces méthodes ajoutent des signes supplémentaires, comme tracer des contours autour des objets ou estimer l'incertitude, mais elles peuvent être facilement trompées lorsque les bords sont eux-mêmes flous ou ambigus — précisément le cas d'un bon camouflage.
Petits indices texturaux qui trahissent le leurre
Les auteurs soutiennent que même le meilleur camouflage laisse des traces révélatrices dans la texture fine d'une image — de petites différences de grain, de motif ou de rugosité faciles à négliger lorsqu'on se concentre uniquement sur les contours. S'appuyant sur cette idée, CTHINet sépare l'apprentissage en deux branches coordonnées. Une branche « contexte », basée sur une puissante architecture de type vision transformer, capture des informations larges et multi‑échelles sur l'ensemble de la scène : comment les régions se relient, où se situent les grandes formes et quelles zones pourraient raisonnablement contenir un objet. En parallèle, une branche « texture » dédiée se focalise étroitement sur les motifs de surface subtils, entraînée avec des étiquettes texturales spéciales qui indiquent au réseau quels types de détails fins appartiennent à l'objet caché plutôt qu'à l'arrière‑plan.
Comment les deux branches coopèrent
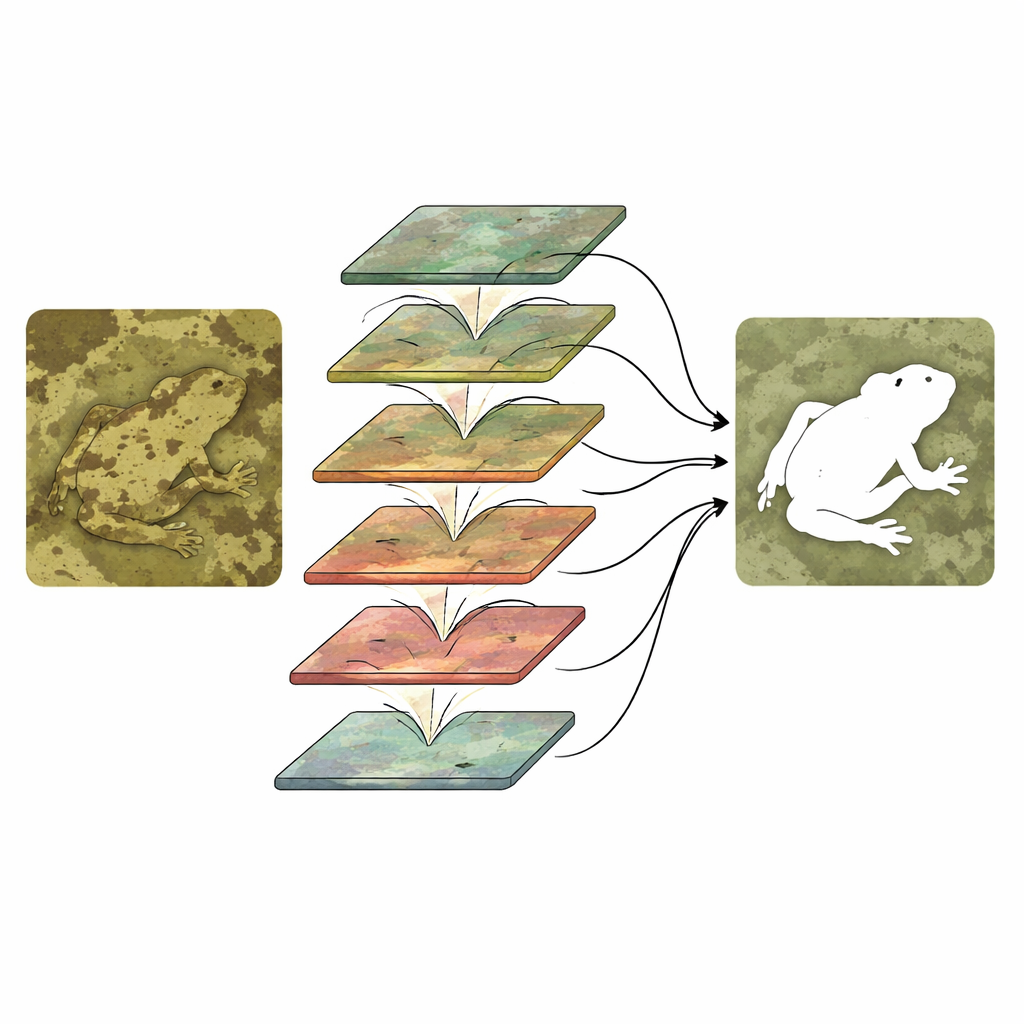
Faire simplement fonctionner deux branches ne suffit pas ; elles doivent interagir intelligemment. CTHINet affine d'abord les caractéristiques de contexte à l'aide d'un module d'agrégation de caractéristiques multi‑têtes. Ce module divise l'information en plusieurs parties, chacune traitée avec un « niveau de zoom » effectif différent, permettant au système de réagir aussi bien aux insectes minuscules qu'aux grands animaux. Il recombine ensuite ces vues pour qu'elles s'éclairent mutuellement sans faire exploser le coût computationnel. Ensuite, une série de modules d'interaction hiérarchique à échelle mixte relie les flux contexte et texture. À chaque étape, le réseau regroupe et mélange des canaux des deux branches, leur permet d'échanger des informations, puis les ré‑pondère de sorte que les combinaisons les plus informatives soient amplifiées tandis que les moins utiles sont atténuées. Cet empilement du grossier au fin aiguise progressivement le contour d'un objet dissimulé et le sépare des détails de fond distrayants.
Preuves d'efficacité en milieu naturel et clinique
Pour évaluer CTHINet, les chercheurs l'ont testé sur trois benchmarks publics difficiles d'animaux et d'objets camouflés, contenant des milliers d'images dans des environnements naturels variés. Sur plusieurs mesures d'exactitude standard, la nouvelle méthode a systématiquement surpassé plus de vingt systèmes de pointe, en particulier sur des scènes difficiles avec de petites cibles, un fort mimétisme de l'arrière‑plan ou une occlusion partielle. L'équipe a également appliqué le même réseau, avec des modifications minimes, à une tâche médicale : la segmentation des polypes dans des images de coloscopie. Les polypes se fondent souvent dans la paroi intestinale de la même manière que les animaux dans le feuillage. Là encore, CTHINet a fourni les meilleurs résultats parmi plusieurs modèles solides d'imagerie médicale, ce qui suggère que sa façon de combiner contexte et texture est largement utile.
Ce que cela signifie pour la détection du presque invisible
En termes simples, CTHINet incarne une idée à la fois simple et puissante : pour trouver quelque chose conçu pour rester caché, un ordinateur doit regarder à la fois la vue d'ensemble et les moindres détails de surface, et laisser ces deux perspectives s'informer mutuellement pas à pas. En concevant un réseau qui sépare clairement ces rôles, puis les réunit via des interactions soigneusement ordonnées, les auteurs obtiennent une détection plus précise des cibles camouflées et montrent un potentiel pour les tâches d'inspection médicale et industrielle où des structures importantes peuvent être facilement négligées. À mesure que les données d'image continuent de croître, de tels systèmes sensibles au contexte et à la texture pourraient devenir des outils clés pour révéler ce qui était destiné à rester invisible.
Citation: Wang, Z., Deng, Y., Shen, C. et al. Camouflaged object detection via context and texture-aware hierarchical interaction. Sci Rep 16, 9328 (2026). https://doi.org/10.1038/s41598-025-32409-9
Mots-clés: détection d'objets camouflés, vision par ordinateur, analyse de texture, segmentation d'images médicales, apprentissage profond