Clear Sky Science · fr
Approche d’apprentissage incrémental pour la segmentation sémantique d’images histologiques cutanées
Pourquoi apprendre aux ordinateurs à lire les prélèvements cutanés compte
Le cancer de la peau est l’un des cancers les plus fréquents dans le monde, et les médecins se reposent souvent sur des coupes fines de tissu observées au microscope pour évaluer la gravité d’une tumeur et décider du traitement. L’interprétation de ces lames est un travail lent et exigeant, susceptible de varier d’un expert à l’autre. Cette étude explore comment concevoir des systèmes informatiques qui apprennent à reconnaître différents tissus et cancers cutanés sur ces images microscopiques et, surtout, qui continuent à s’améliorer au fil du temps à mesure que de nouveaux types d’images sont ajoutés—à la manière d’un stagiaire humain qui apprend tout au long de sa carrière.
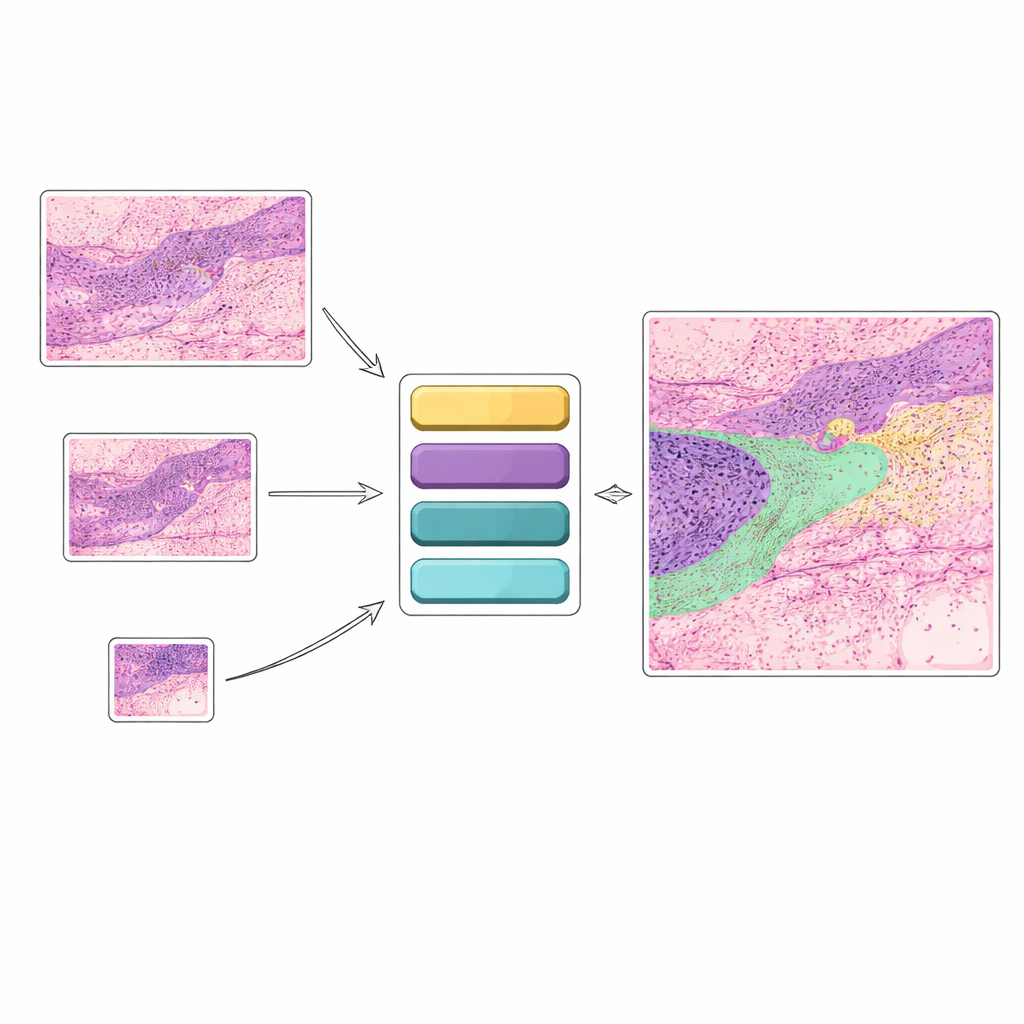
Des réponses simples oui/non aux cartes tissulaires détaillées
De nombreux outils d’intelligence artificielle existants pour le cancer de la peau se contentent d’analyser une image et de répondre à une question restreinte, par exemple « cancer » ou « pas de cancer ». Si utile soit-elle, une telle décision binaire ne rend pas compte de la richesse des détails que voient les pathologistes. En clinique, les médecins s’intéressent à de nombreuses structures simultanément : différents types de cancer, couches cutanées saines, follicules pileux, glandes, zones enflammées, etc. Cette étude se concentre plutôt sur la « segmentation sémantique », où chaque pixel d’une image histologique est attribué à l’une des douze catégories tissulaires. Cela produit une carte codée par couleur montrant précisément l’emplacement des cancers et des tissus normaux, offrant des indications plus claires pour le diagnostic et la planification du traitement.
Pourquoi les systèmes actuels peinent à s’adapter
Les modèles profonds performants d’aujourd’hui supposent généralement que toutes les données d’entraînement sont disponibles simultanément. Une fois entraînés, ils ont tendance à « figer » leurs connaissances. Si des données nouvelles aux propriétés différentes—par exemple des images à une autre augmentation—sont introduites plus tard, l’option la plus sûre est souvent de réentraîner le modèle entier depuis le début. Cela coûte cher et prend du temps, et, pire encore, l’ajout d’informations peut provoquer un « oubli catastrophique », où les performances sur les tâches antérieures déclinent discrètement. Or, en contexte clinique, les données évoluent en permanence : les scanners sont mis à jour, les paramètres d’imagerie changent et les hôpitaux collectent de nouveaux types d’échantillons. Un outil d’IA incapable d’absorber ces changements de façon élégante est difficile à faire confiance au quotidien.
Une stratégie d’apprentissage progressive inspirée de l’apprentissage humain
Les auteurs s’appuient sur une architecture moderne de transformeur de vision appelée SegFormer et la transforment en un système d’« apprentissage incrémental » pour le cancer cutané non mélanique. Plutôt que de voir toutes les données d’un coup, le modèle est entraîné par étapes en utilisant des lames histologiques d’un jeu de données public de l’Université du Queensland. D’abord, il apprend à partir d’images à fort grossissement (10×), où les détails fins sont nets. Ensuite, des images en 5× puis en 2× sont ajoutées, tout en conservant une portion des données initiales à haute résolution. Des fonctions de perte spéciales aident la nouvelle version du modèle à conserver ce qu’elle savait auparavant des motifs tissulaires, même lorsqu’elle s’adapte aux vues plus larges et moins détaillées. Cet « apprentissage sans oubli » est guidé par une technique appelée distillation des connaissances, où un modèle antérieur joue le rôle de professeur pour le nouveau, et par un terme de distillation mutuelle qui pousse les représentations anciennes et nouvelles à demeurer en harmonie.
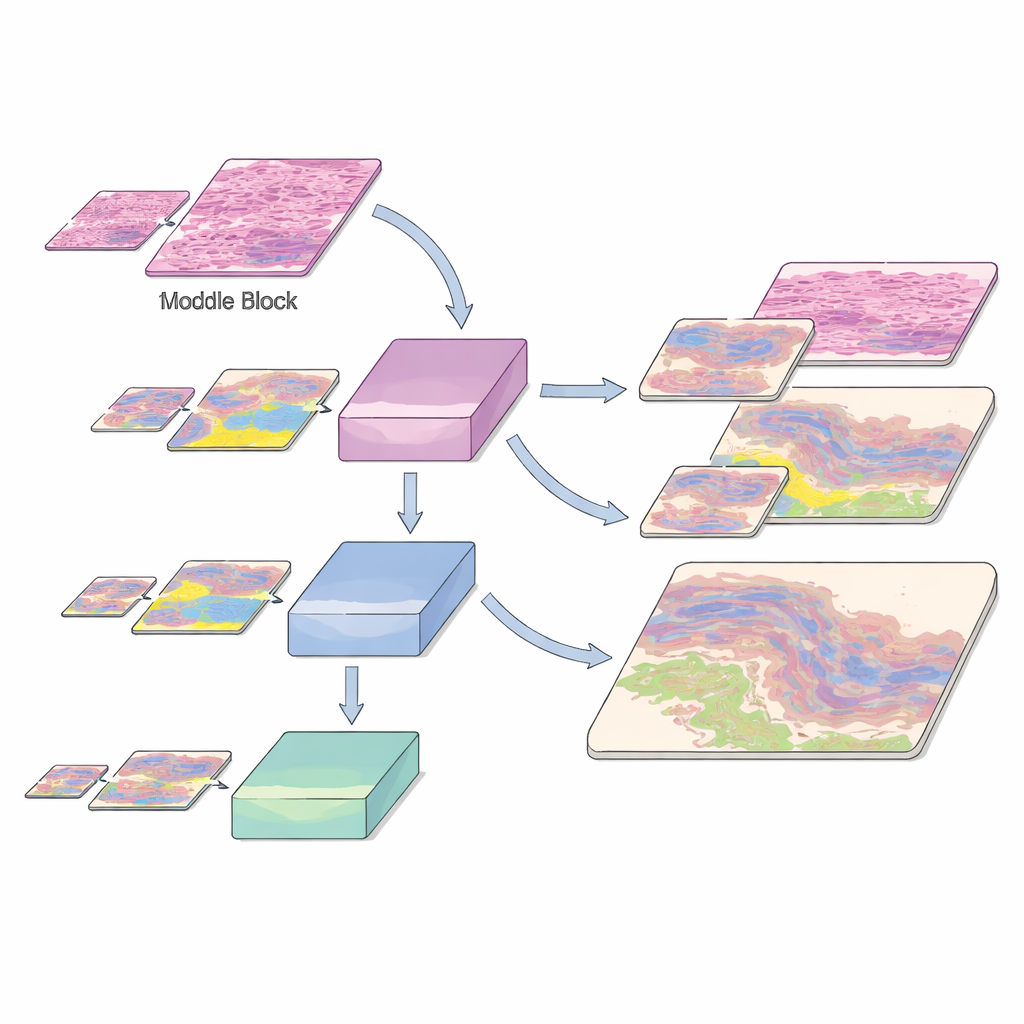
Apprendre à travers les niveaux de zoom et les types tissulaires rares
Les images histologiques sont difficiles non seulement parce qu’il existe de nombreux types tissulaires, mais aussi parce que certaines structures importantes sont rares. Le jeu de données inclut des cancers courants comme le carcinome basocellulaire et le carcinome spinocellulaire, ainsi que des couches cutanées normales et enflammées, chacune annotée au niveau du pixel par des experts—un processus minutieux demandant des centaines d’heures. Les auteurs découpent ces très grandes lames en petits patchs et entraînent leur modèle en respectant une répartition soigneuse entre ensembles d’entraînement, de validation et de test, préservant la composition des classes tissulaires à chaque grossissement. Pour aider le système à reconnaître des régions rares mais cliniquement cruciales, ils augmentent les classes sous-représentées en faisant tourner les patchs et en exposant le modèle à ces tissus à plusieurs niveaux de zoom. Cette exposition multi-résolution aide l’IA à reconnaître la même structure biologique qu’elle apparaisse en gros plan net ou sous une forme plus floue et éloignée.
Ce que le modèle réalise par rapport aux outils antérieurs
À eux seuls, des modèles SegFormer entraînés séparément à chaque grossissement surpassent déjà de nombreuses conceptions convolutionnelles antérieures comme U-Net sur plusieurs catégories tissulaires. Mais lorsque le schéma d’apprentissage incrémental est appliqué—entraînement d’abord en 10×, puis en 10× plus 5×, et enfin en 10×, 5× et 2× ensemble—les gains deviennent saisissants. La précision globale passe d’environ 89 % avec uniquement des images 10× à plus de 95 % après l’inclusion des trois grossissements. Les mesures de recoupement entre régions prédites et réelles s’améliorent régulièrement, et les performances sur des cancers tels que le carcinome basocellulaire et le carcinome spinocellulaire, ainsi que sur des couches normales clés comme l’épiderme et le derme papillaire, dépassent celles des méthodes concurrentes. Surtout, à mesure que chaque nouveau niveau de zoom est ajouté, le modèle n’oublie pas ce qu’il avait appris auparavant ; au contraire, sa compréhension de la structure tissulaire devient plus robuste et plus générale.
Comment ce travail rapproche le diagnostic assisté par l’IA de la clinique
Pour les non-spécialistes, le message principal est que les auteurs ont créé un « cartographe » des tissus cutanés capable de continuer à étudier de nouveaux types d’images sans perdre ses compétences antérieures. En concevant soigneusement la façon dont le modèle apprend par étapes et réutilise ses propres connaissances passées, ils montrent qu’il est possible de bâtir des outils d’IA qui s’adaptent à l’évolution des pratiques d’imagerie médicale. Bien que des validations supplémentaires soient nécessaires à travers différents hôpitaux et types de maladies, cette approche incrémentale basée sur les transformeurs ouvre la voie à des systèmes d’IA capables de rester à jour avec des données changeantes, d’offrir des explications visuelles détaillées de l’emplacement des cancers et, en fin de compte, de soutenir les pathologistes pour prendre des décisions de traitement plus sûres et plus cohérentes.
Citation: Fatima, S., Salam, A.A., Akram, M.U. et al. Incremental learning approach for semantic segmentation of skin histology images. Sci Rep 16, 9593 (2026). https://doi.org/10.1038/s41598-025-31553-6
Mots-clés: cancer de la peau, images histologiques, segmentation sémantique, apprentissage incrémental, transformeurs en apprentissage profond