Clear Sky Science · fr
Un jeu de données à grande échelle sur les choix et les temps de réponse en choix intertemporels
Pourquoi attendre plutôt que maintenant compte
La vie quotidienne regorge de choix entre une récompense plus petite maintenant et une récompense plus grande plus tard : dépenser de l’argent aujourd’hui ou épargner pour la retraite, manger un dessert ou respecter un régime. La manière dont nous prenons ces décisions « maintenant contre plus tard » — appelées choix intertemporels — façonne notre santé, nos finances et nos relations. Pourtant, les scientifiques débattent encore de ce qui se passe dans nos esprits au cours de ces décisions. Cet article présente un nouveau jeu de données ouvert massif qui rassemble des enregistrements détaillés de la façon dont près de douze mille personnes ont fait de tels choix, incluant non seulement ce qu’elles ont choisi mais aussi combien de temps elles ont mis pour décider.
Rassembler des études éclatées sous un même toit
Pendant des décennies, économistes et psychologues ont réalisé des expériences où des personnes choisissent, par exemple, entre une somme d’argent plus faible bientôt et une somme plus importante plus tard. Beaucoup de ces études se sont focalisées uniquement sur le choix final, en ignorant le processus de décision lui‑même. Les auteurs soutiennent que cela fait manquer une source importante d’informations : les temps de réponse — le nombre de secondes que met une personne pour décider. Les temps de réponse peuvent révéler la facilité ou la difficulté d’un choix et aider à tester des théories sur la manière dont le cerveau pèse les récompenses immédiates par rapport aux récompenses futures. Pour dépasser les résultats isolés, les auteurs ont rassemblé les données brutes essai par essai de 100 études distinctes, couvrant au total 11 852 participants et 1 172 644 décisions individuelles.
Traquer et unifier les données
L’équipe a d’abord réalisé une recherche systématique étendue dans la littérature scientifique, via deux bases de données majeures, pour trouver toute expérience publiée ayant utilisé une tâche intertemporelle standard sur ordinateur avec des montants d’argent et des durées d’attente clairement définis. À partir de plus de quatre mille résultats initiaux, elle a appliqué des critères stricts pour exclure les études qui ne correspondaient pas à la tâche, n’étaient pas évaluées par des pairs, utilisaient des sujets non humains, n’étaient pas en anglais ou ne comportaient pas de données primaires. Ce criblage a laissé 1 709 articles potentiellement adaptés. Pour chacun d’eux, les chercheurs ont soit localisé des fichiers de données déjà ouverts, soit contacté les auteurs directement, envoyant au total plus de 1 600 demandes formelles de données pour obtenir les informations au niveau des essais.
À quoi ressemble le jeu de données combiné
Grâce à cet effort, les auteurs ont obtenu 112 jeux de données issus de 98 publications et, après autorisations finales et contrôles de qualité, ont publié 100 jeux de données provenant de 87 articles. Chaque ligne du fichier combiné correspond à un seul essai de choix et inclut ce qui a été proposé (un montant plus petit‑plus proche et un montant plus grand‑plus lointain), quelle option a été choisie et combien de temps la personne a mis pour répondre. Des champs supplémentaires décrivent le participant (par exemple l’âge et le pays), la façon dont la tâche a été menée (en ligne versus en laboratoire, si les choix étaient payés réellement, s’il y avait une contrainte de temps) et comment les données doivent être filtrées (par exemple les essais avec des valeurs manquantes). Toutes les données sont fournies dans des formats courants et partagent la même structure de variables, ce qui facilite leur analyse par d’autres chercheurs avec différents outils logiciels.
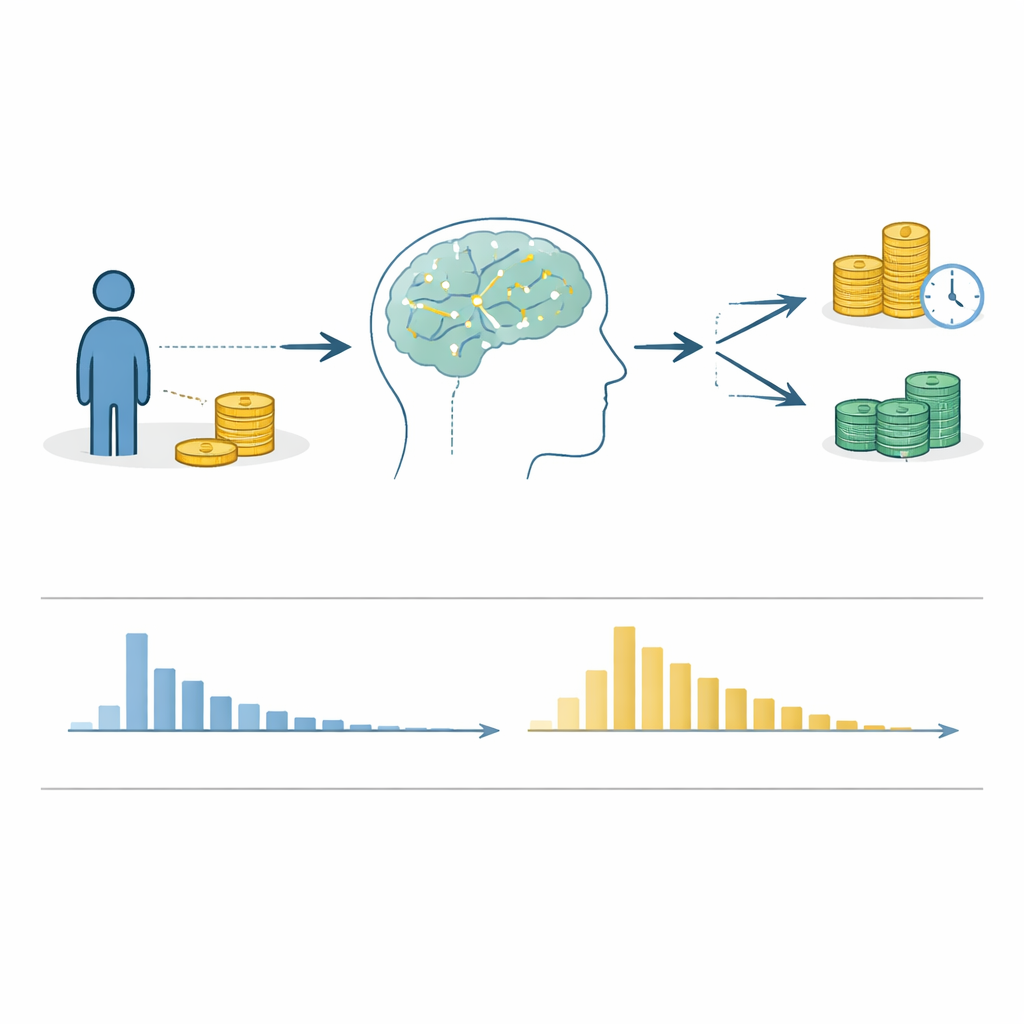
Vérifier les données en coulisses
Parce que le jeu de données combine de nombreuses études indépendantes, les auteurs ont réalisé des contrôles techniques étendus pour s’assurer que les chiffres sont cohérents. Ils ont comparé les tailles d’échantillon et le nombre d’essais reportés dans chaque article avec ce qui figure réellement dans les fichiers, documenté les discordances éventuelles et inspecté les motifs de réponses manquantes. Ils ont vérifié que l’option « plus petite‑plus proche » était bien réellement plus petite et plus proche que l’option « plus grande‑plus lointaine » et ont relancé les auteurs originaux quand quelque chose paraissait étrange. Ils ont aussi testé si les choix des participants suivaient un comportement raisonnable — par exemple, si des récompenses plus grandes et des délais plus courts augmentaient généralement la probabilité qu’une option soit choisie. Pour les temps de réponse, ils ont filtré les valeurs impossibles, comme des durées négatives ou des décisions improbablement rapides ou lentes, et examiné si la plupart des participants montraient le schéma typique de nombreuses réponses rapides et de moins de réponses lentes.
Une ressource vivante pour de futurs enseignements
Les auteurs ont publié une capture statique de ce jeu de données à grande échelle, attachée à l’article, ainsi qu’une base de données en ligne vivante qui continuera de s’enrichir au fur et à mesure que d’autres chercheurs contribueront leurs données. Outre le fichier maître combiné, tous les jeux de données individuels sont également disponibles en téléchargements séparés lorsque les autorisations le permettent. Bien que les scripts de traitement bruts originaux ne soient pas partagés dans tous les cas, les données résultantes sont documentées et sous licence pour une large réutilisation à des fins non commerciales. Cette ressource ouvre la voie aux scientifiques pour tester de nouveaux modèles sur la manière dont les gens arbitrent entre récompenses présentes et futures, pour explorer pourquoi les résultats diffèrent parfois selon les contextes et les groupes, et pour concevoir des théories de la prise de décision plus robustes. Pour le lecteur non spécialiste, la conclusion essentielle est que les chercheurs disposent désormais d’une base partagée puissante pour comprendre pourquoi attendre un meilleur lendemain peut être si difficile — et comment cette difficulté varie d’une personne à l’autre et d’une situation à l’autre.
Citation: Pongratz, H., Schoemann, M. A large-scale dataset of choice and response-time data in intertemporal choice. Sci Data 13, 323 (2026). https://doi.org/10.1038/s41597-026-06947-4
Mots-clés: choix intertemporel, dévalorisation temporelle, temps de réponse, prise de décision, jeu de données ouvert