Clear Sky Science · fr
Un ensemble de données unifié pour la conception d’anticorps et de nanocorps comprenant séquence, structure et affinité de liaison
Pourquoi les petits outils immunitaires et les mégadonnées comptent
Les anticorps et leurs petits cousins, les nanocorps, sont les missiles guidés de précision de l’organisme contre les infections et le cancer. Les développeurs de médicaments cherchent désormais à concevoir ces molécules sur ordinateur, de la même manière que des ingénieurs conçoivent des avions. Mais jusqu’à récemment, la matière première pour ce type de conception par intelligence artificielle — des données fiables sur les composants des anticorps, leurs formes et la force avec laquelle ils se lient à leurs cibles — était dispersée dans de nombreuses bases de données incompatibles. Cet article présente l’Antibody and Nanobody Design Dataset (ANDD), une ressource publique et unifiée conçue pour fournir aux chercheurs des données propres et complètes afin de créer la prochaine génération de thérapies ciblées.
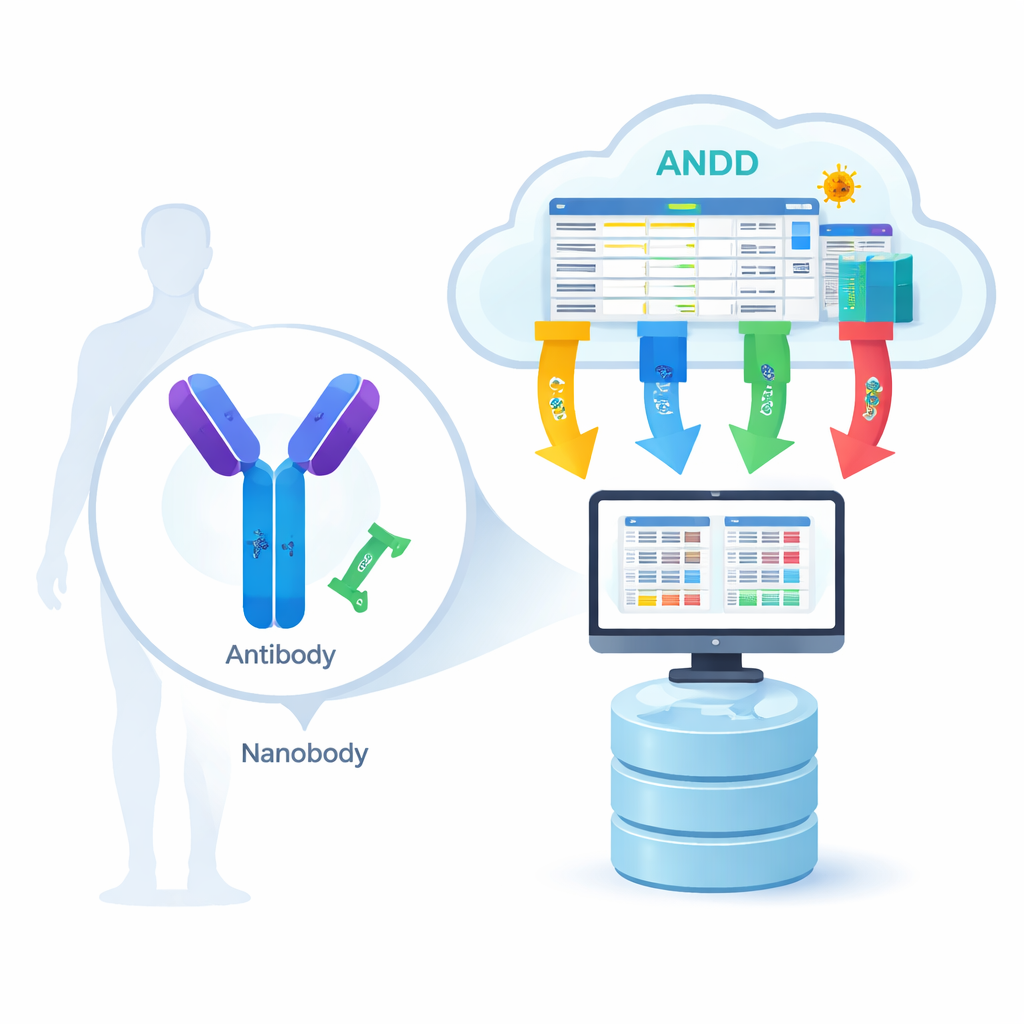
Du verrou biologique à la feuille de route numérique
Les anticorps sont de grandes protéines en forme de Y, tandis que les nanocorps sont des versions beaucoup plus petites en un seul fragment, retrouvées chez des animaux comme les lamas et les alpagas. Les deux reconnaissent des « verrous » spécifiques sur des virus, des cellules cancéreuses ou d’autres protéines liées à la maladie. Pour que des modèles informatiques apprennent comment fonctionne cette reconnaissance, ils ont besoin de quatre types d’informations pour de nombreux exemples : la séquence d’acides aminés (la liste des pièces), la structure 3D (la forme), l’antigène (la cible) et la force de liaison (à quel point les deux s’attachent). Jusqu’ici, la plupart des ressources ne couvraient qu’une ou deux de ces pièces à la fois, obligeant les scientifiques à naviguer entre bases de données et à reconstituer manuellement les éléments, ce qui ralentissait le progrès et introduisait des erreurs.
Rassembler les éléments épars dans une bibliothèque organisée
L’équipe ANDD a rassemblé des données issues de 15 sources majeures, y compris des bases dédiées aux anticorps et nanocorps, des dépôts protéiques généraux et même des documents de brevets. Ils ont ensuite fait passer ces entrées brutes par un pipeline soigneusement scripté : téléchargement, reformatage dans un schéma commun, vérification croisée des identifiants, suppression des doublons et harmonisation des règles de dénomination. Lorsque des bases de données différaient, les sources curatées et les expériences directes ont été privilégiées. Le résultat final est une table unique accompagnée d’un ensemble de fichiers de structure qui relient séquence, structure, cible et information de liaison de manière cohérente, chaque enregistrement étant étiqueté pour que les utilisateurs puissent retracer exactement son origine et son traitement.
Détails superposés pour différents besoins de recherche
Chaque entrée de l’ANDD n’est pas également riche, les auteurs ont donc organisé la collection en couches de détail croissant. Au niveau le plus large, on trouve 48 683 entrées d’anticorps et de nanocorps avec l’information de séquence. Un sous-ensemble important ajoute des structures 3D, et un sous-ensemble plus petit inclut en outre la séquence des protéines cibles. La couche la plus détaillée — des milliers d’entrées — ajoute des mesures ou prédictions d’affinité de liaison. Pour les anticorps, par exemple, 18 464 entrées ont des séquences, le même nombre combine séquence et structure, plus de 8 000 incluent également les séquences d’antigènes, et 7 737 possèdent la séquence, la structure, l’antigène et les données d’affinité complètes. Une hiérarchie parallèle existe pour les nanocorps, offrant aux expérimentateurs et aux constructeurs de modèles la flexibilité de choisir de larges ensembles de données simples ou des sous-ensembles plus petits et riches en informations.
Combler les vides sur la force de liaison
La force de liaison est cruciale pour la conception de médicaments, mais les valeurs expérimentales sont rares et rapportées de manière inégale. Pour combler cette lacune sans brouiller la frontière entre données et prédictions, les auteurs ont utilisé un outil d’apprentissage profond spécialisé, ANTIPASTI, pour estimer la force de liaison uniquement pour les entrées qui disposaient de structures mais manquaient de mesures. Ces 2 271 valeurs prédites sont clairement étiquetées et maintenues séparées des quelque 7 000 valeurs mesurées expérimentalement. L’équipe a ensuite vérifié la cohérence globale à l’aide d’un autre modèle, AlphaBind, et en comparant des mesures de liaison liées mathématiquement. De fortes corrélations et de faibles erreurs ont suggéré que les valeurs expérimentales curatées sont fiables, et que les valeurs prédites suivent des tendances cohérentes sans être traitées comme des vérités absolues.
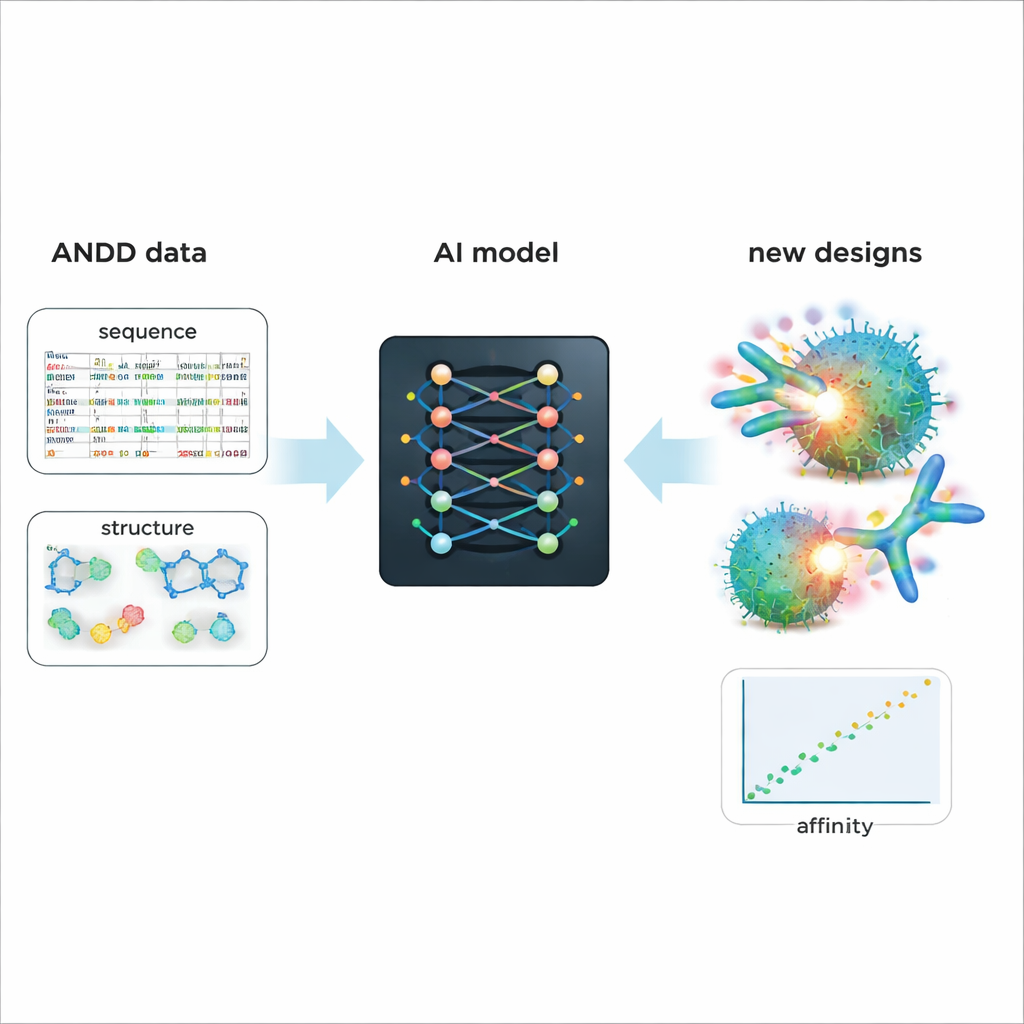
Alimenter une conception plus intelligente des médicaments futurs
Pour démontrer la valeur pratique de l’ANDD, les auteurs ont affiné un modèle d’IA générative existant qui conçoit des anticorps et des nanocorps. L’entraînement sur les informations combinées de séquence, structure, cible et affinité de l’ANDD a produit des molécules générées avec une affinité prédite meilleure et des formes plus réalistes que celles issues d’un modèle de référence entraîné sur des données plus anciennes et plus simples. Au-delà de cette étude de cas, l’ANDD est disponible ouvertement sous une licence permissive, accompagnée d’une documentation complète et d’un pipeline de construction reproductible, et est conçu pour être mis à jour régulièrement. Pour les non-spécialistes, le message principal est que l’ANDD transforme un patchwork désordonné de données sur les anticorps en une bibliothèque cohérente et digne de confiance — donnant aux outils d’IA un point de départ bien meilleur pour concevoir des médicaments biologiques plus précis et plus efficaces.
Citation: Wu, Y., Liu, X., Hrovatin, K. et al. A Unified Dataset for Antibody and Nanobody Design Including Sequence, Structure, and Binding Affinity Data. Sci Data 13, 295 (2026). https://doi.org/10.1038/s41597-026-06878-0
Mots-clés: conception d’anticorps, nanocorps, affinité de liaison, thérapeutiques biologiques, découverte de médicaments par IA