Clear Sky Science · fr
Jeu de données PreprintToPaper : relier les préprints bioRxiv aux publications en revue
Pourquoi la recherche précoce nous concerne tous
Bien avant qu’une découverte scientifique n’apparaisse dans une revue à grand tirage, elle est souvent publiée sous forme de « préprint » – une version préliminaire partagée gratuitement. Pendant la pandémie de COVID‑19, ces préprints ont influencé les manchettes, les débats publics et même les politiques de santé. Pourtant, il a été étonnamment difficile de retracer quelles études initiales se sont ensuite transformées en articles de revue, et lesquelles ne l’ont jamais fait. Cet article présente le jeu de données PreprintToPaper, une cartographie vaste et soigneusement vérifiée reliant les préprints en sciences de la vie déposés sur le serveur bioRxiv à leurs publications ultérieures en revue, offrant au grand public, aux journalistes et aux chercheurs une vision plus claire du parcours des résultats scientifiques précoces dans le système.
Suivre le trajet du brouillon à l’article
Les auteurs se sont concentrés sur bioRxiv, un serveur en ligne majeur où les chercheurs en sciences de la vie déposent des préprints. Ils ont rassemblé des informations sur 145 517 préprints issus de deux périodes clés : 2016–2018, avant la pandémie de COVID‑19, et 2020–2022, pendant la frénésie de publications liée à la pandémie. Pour chaque préprint, ils ont enregistré des éléments tels que le titre, le résumé, les auteurs, les institutions, la discipline, la licence et les dates de soumission. Ils ont ensuite utilisé Crossref, un registre central d’articles de revues, pour récupérer les informations correspondantes sur les articles publiés : noms de revues, dates de publication et listes complètes d’auteurs. En combinant ces sources, ils ont construit un enregistrement riche et unifié qui suit une étude depuis sa première apparition publique en tant que préprint jusqu’à sa forme finale dans une revue scientifique.
Classer les préprints en groupes clairs
Pour donner du sens à cette vaste collection, l’équipe a classé chaque préprint dans l’un des trois groupes. Les préprints « Publiés » disposaient d’un lien numérique clair de bioRxiv vers un article de revue. Les éléments « Préprint seulement » étaient mis en ligne sur le serveur sans aucun signe d’une publication ailleurs. Le groupe le plus intrigant, appelé la « Zone grise », contient des cas qui semblent avoir été publiés dans une revue mais qui n’ont pas de lien officiel sur bioRxiv. Pour capturer l’évolution des préprints dans le temps, les chercheurs ont aussi élaboré un fichier d’historique des versions répertoriant chaque version disponible pour les préprints qui avaient une version originale et au moins une mise à jour ultérieure. Cela permet à d’autres d’étudier comment les titres, les listes d’auteurs et d’autres détails évoluent entre le premier brouillon et la dernière version du préprint.
Détecter les correspondances cachées et les vérifier manuellement
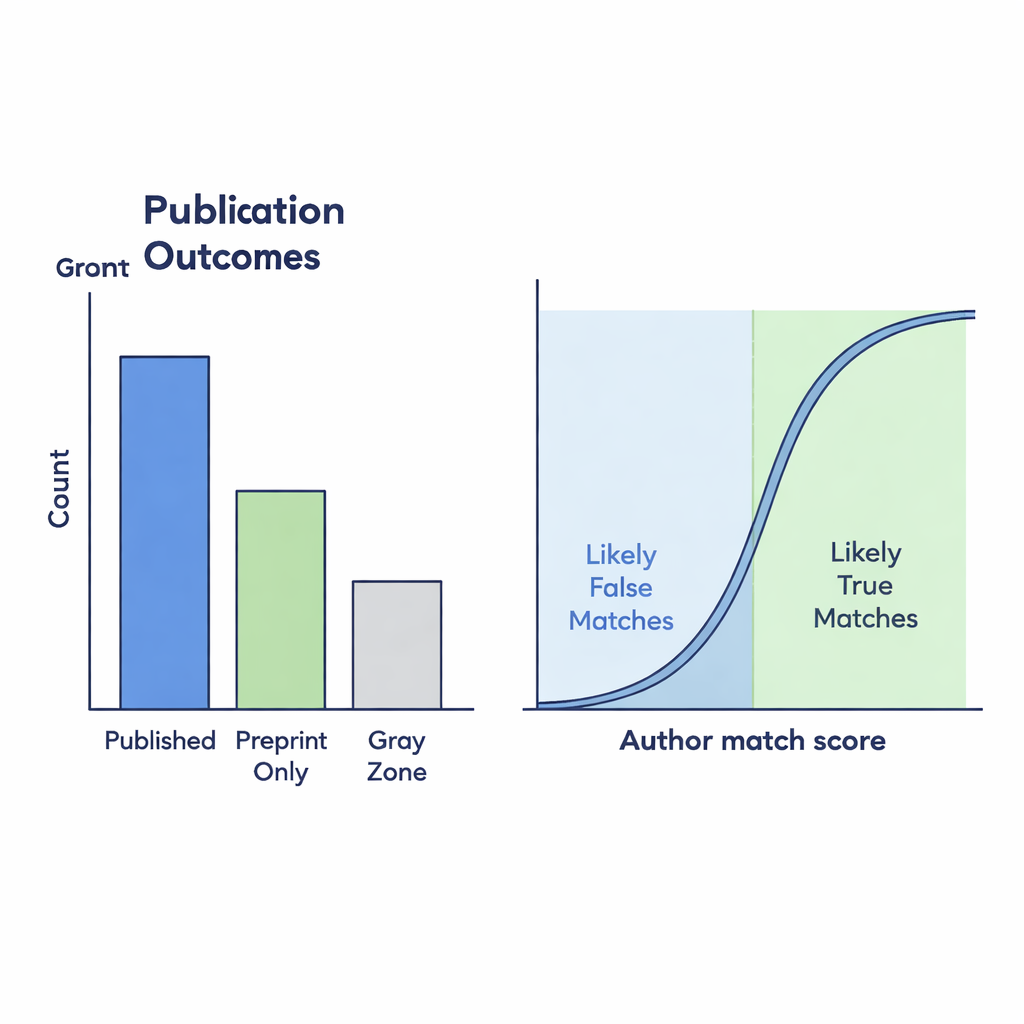
Beaucoup de préprints effectivement publiés ne reçoivent jamais de lien de retour adéquat sur bioRxiv, créant des angles morts pour quiconque tente de suivre la production scientifique. Pour découvrir ces connexions manquantes, les auteurs ont comparé les titres et les listes d’auteurs des préprints avec les enregistrements de revues de Crossref. Ils ont utilisé un score de similarité compris entre 0 et 1 pour mesurer la concordance des titres ; les correspondances potentielles de la Zone grise nécessitaient un score d’au moins 0,75. Ils ont ensuite affiné ces candidats avec des mesures basées sur les auteurs : la différence du nombre d’auteurs et la similarité apparente des noms. Pour vérifier la fiabilité de ces règles automatisées, deux annotateurs humains ont examiné manuellement 299 cas limites. Leurs jugements étaient fortement concordants, et un modèle statistique a montré que lorsque les listes d’auteurs correspondaient bien, un lien supposé avait de fortes chances d’être authentique.
Ce que les chiffres révèlent sur la production scientifique
Le jeu de données final montre comment les pratiques de prépublication et de publication ont évolué avant et pendant la pandémie. Dans l’ensemble, il contient plus de 90 000 préprints clairement publiés, plus de 35 000 qui semblent être restés uniquement sur le serveur, et environ 19 000 cas de Zone grise où le lien vers un article de revue a nécessité un travail de détective. Si l’on ne compte que le groupe « Publiés » officiellement lié, on observe apparemment une part beaucoup plus faible de préprints devenant des articles de revue au fil du temps. Mais lorsque l’on inclut les correspondances probables de la Zone grise — celles présentant une forte similarité d’auteurs — la baisse des taux de publication est beaucoup moins marquée. Cela suggère que les liens manquants dans l’infrastructure sous-jacente peuvent induire en erreur sur la manière dont le paysage scientifique évolue.
Pourquoi cette ressource est utile au-delà des spécialistes
Pour les non‑spécialistes, le message principal est que les résultats scientifiques précoces ne disparaissent pas simplement dans une boîte noire. Avec le jeu de données PreprintToPaper, il devient possible de voir quels résultats rapides survivent finalement à l’évaluation par les pairs, combien de temps ce parcours prend, et quels types d’études ne quittent jamais le stade de préprint. Les décideurs peuvent utiliser ces informations pour juger de l’efficacité des pratiques de science ouverte ; les journalistes peuvent mieux évaluer la solidité d’un résultat donné ; et les chercheurs peuvent développer des outils qui trient et résument le flux écrasant d’articles. En bref, ce jeu de données transforme un flot chaotique de recherches précoces en un enregistrement plus traçable et responsable de la façon dont les idées passent de la première mise en ligne à la publication finalisée.
Citation: Badalova, F., Sienkiewicz, J. & Mayr, P. PreprintToPaper dataset: connecting bioRxiv preprints with journal publications. Sci Data 13, 301 (2026). https://doi.org/10.1038/s41597-026-06867-3
Mots-clés: préprints, publication scientifique, science ouverte, recherche COVID-19, bibliométrie