Clear Sky Science · fr
Cuentos : un corpus de lecture par suivi oculaire à grande échelle sur des textes narratifs en espagnol
Pourquoi observer les yeux peut révéler notre façon de lire
Chaque fois que vous lisez une histoire, vos yeux sautillent, marquent des pauses et font des sauts dont vous ne vous apercevez guère — mais ces micro-mouvements tracent silencieusement le fonctionnement de votre esprit. La majeure partie de ce que nous savons provient d’études en anglais. Cet article présente « Cuentos », la plus grande collection publique de données de mouvements oculaires obtenues lors de la lecture d’histoires complètes en espagnol. Il transforme la danse invisible des yeux en une ressource riche pour comprendre comment les hispanophones lisent et pour concevoir des technologies linguistiques plus intelligentes.
Des histoires, pas des phrases isolées
Plutôt que d’employer de courtes phrases artificielles, les chercheurs ont demandé à 113 locuteurs natifs d’espagnol de lire des histoires complètes et autonomes rédigées en espagnol d’Amérique latine. La collection comprend 30 récits différents — certains longs, d’autres courts — couvrant des genres tels que le réalisme, l’horreur, l’essai et la vulgarisation scientifique. En moyenne, les longues histoires comptent environ 3 300 mots et les courtes environ 800, couvrant au total près de 40 000 mots et 8 500 termes distincts. Ce choix capture la manière dont les gens lisent naturellement des textes narratifs, du début à la fin, plutôt que la façon dont ils traitent des lignes isolées en laboratoire.
Suivre chaque pause du regard
Les participant·e·s étaient installé·e·s dans une salle obscurcie et lisaient les histoires sur un écran d’ordinateur pendant qu’un traceur oculaire haute vitesse enregistrait leur regard mille fois par seconde. L’appareil a saisi deux comportements clés : de courts arrêts appelés fixations, lorsque les yeux recueillent de l’information sur la page, et de rapides sauts appelés saccades, lorsque les yeux passent à un nouvel endroit. Les textes étaient répartis sur plusieurs écrans, et les lecteurs pouvaient naviguer librement en arrière et en avant avec les flèches, comme on feuillette des pages. Après chaque histoire, ils répondaient à des questions de compréhension pour vérifier leur attention, et pour les histoires courtes ils effectuaient également une brève tâche d’association de mots pour réinitialiser leur concentration avant le récit suivant.
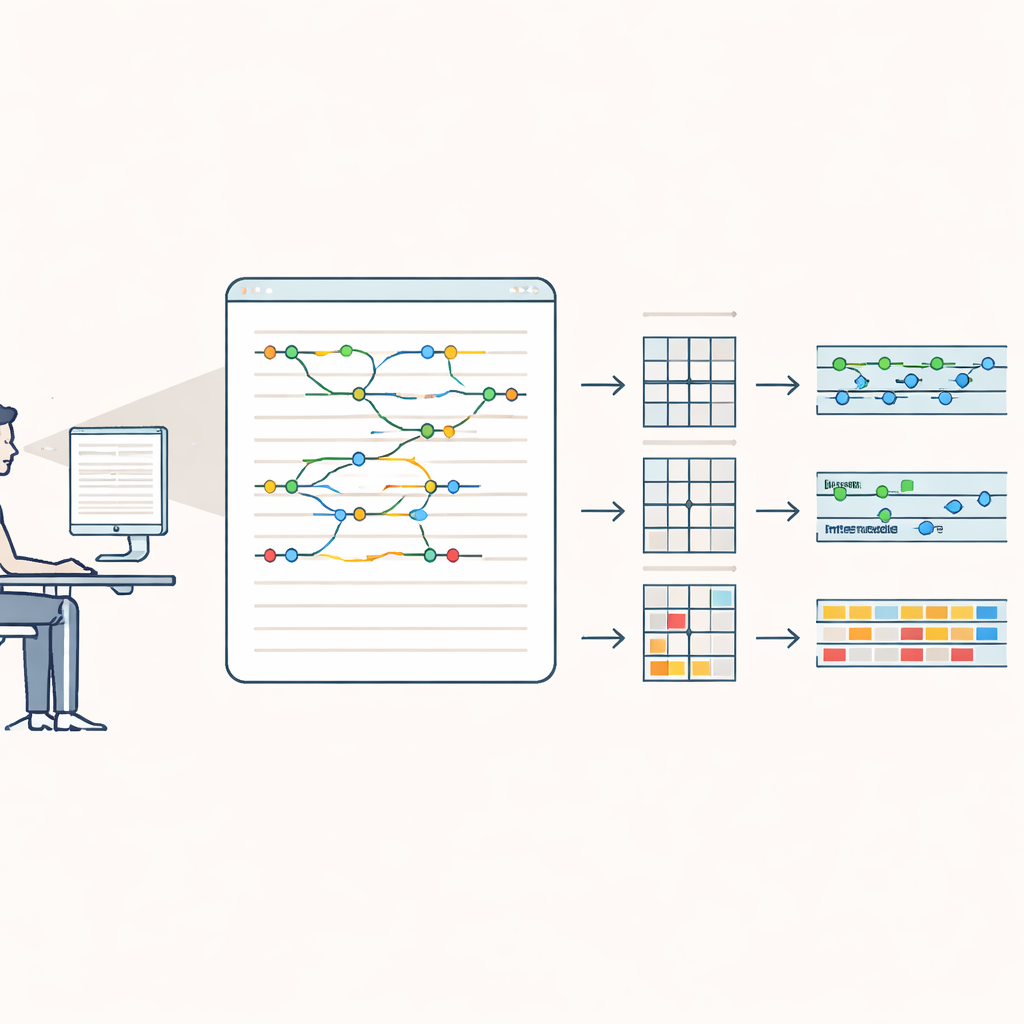
Transformer des trajectoires de regard brutes en données structurées
La collecte des points de mouvement oculaire bruts n’est que le début. L’équipe a développé un logiciel sur mesure pour nettoyer et organiser ces informations avec grand soin. Ils ont éliminé les données peu fiables, comme des fixations extrêmement courtes ou très longues et des essais où le traceur avait une mauvaise calibration. Pour chaque écran, des réviseurs humains ont ajusté des repères afin que les grappes de fixations s’alignent précisément sur la ligne de texte appropriée. Puis, en utilisant la position des espaces entre les mots, ils ont attribué les fixations individuelles à des mots spécifiques. Les cas particuliers — comme le grand saut de l’œil de la fin d’une ligne au début de la suivante, ou les retours accidentels vers des écrans précédents — ont été détectés et filtrés. Le résultat est une cartographie méticuleusement organisée reliant chaque mot des histoires à la durée, à la fréquence et au motif de son exploration visuelle.
Ce que révèlent les mouvements oculaires
À partir de ces traces nettoyées, les auteurs ont calculé un ensemble riche de mesures pour chaque mot. Certaines reflètent un traitement précoce et automatique, comme la durée de la première fixation ou le temps pendant lequel un mot est regardé avant que les yeux ne poursuivent. D’autres captent un traitement plus tardif et plus délibéré, comme le temps passé à revenir relire des mots antérieurs. Grâce à des modèles statistiques modernes, ils ont confirmé des schémas bien connus d’autres langues, désormais fermement établis en espagnol : les mots plus courts et plus fréquents sont lus plus rapidement, et les lecteurs ont tendance à sauter complètement les mots très courts et familiers. La position d’un mot dans la phrase ou sur l’écran influence aussi subtilement la durée de la fixation. Ces vérifications montrent que le nouveau jeu de données se comporte de manière cohérente et interprétable et peut servir de référence fiable.
Un nouvel outil pour la recherche sur la lecture et les logiciels intelligents
Toutes les données et le code sont librement accessibles dans des formats standardisés, ce qui facilite leur exploration par d’autres chercheur·e·s. Les linguistes peuvent utiliser Cuentos pour étudier des traits propres à l’espagnol, tels que les terminaisons de mots, l’ordre des mots ou le style. Les psychologues peuvent examiner comment les stratégies de lecture varient d’un individu à l’autre ou comment le genre influe sur l’effort cognitif. Les développeur·se·s en intelligence artificielle et en traitement du langage naturel peuvent intégrer ces informations dans des modèles qui imitent mieux la lecture humaine, améliorant des tâches comme la simplification de textes ou la prédiction des mots difficiles à comprendre. En termes simples, Cuentos transforme les mouvements subtils des yeux des lecteurs hispanophones en un outil partagé puissant, à la fois pour comprendre l’esprit et pour construire des technologies linguistiques plus proches de l’humain.
Citation: Travi, F., Bianchi, B., Slezak, D.F. et al. Cuentos: A Large-Scale Eye-Tracking Reading Corpus on Spanish Narrative Texts. Sci Data 13, 434 (2026). https://doi.org/10.1038/s41597-026-06798-z
Mots-clés: suivi oculaire, lecture, langue espagnole, traitement du langage naturel, sciences cognitives