Clear Sky Science · fr
Un jeu de données à grande échelle de cellules sanguines périphériques pour l’analyse hématologique automatisée
Pourquoi les images de cellules sanguines comptent
Chaque prise de sang de routine dissimule un monde microscopique de cellules qui peut révéler des infections, une anémie, voire des cancers du sang bien avant que les symptômes n’apparaissent. Les médecins examinent traditionnellement ces cellules à l’œil au microscope, un travail minutieux mais chronophage. Cette étude présente une très grande collection d’images de cellules sanguines soigneusement annotées, destinée à apprendre aux ordinateurs à reconnaître ces cellules automatiquement. L’objectif est d’accélérer les analyses sanguines futures, d’assurer une plus grande homogénéité et de rendre ces examens plus accessibles en donnant à l’intelligence artificielle l’expérience visuelle nécessaire pour aider les cliniciens à lire les frottis sanguins avec précision.
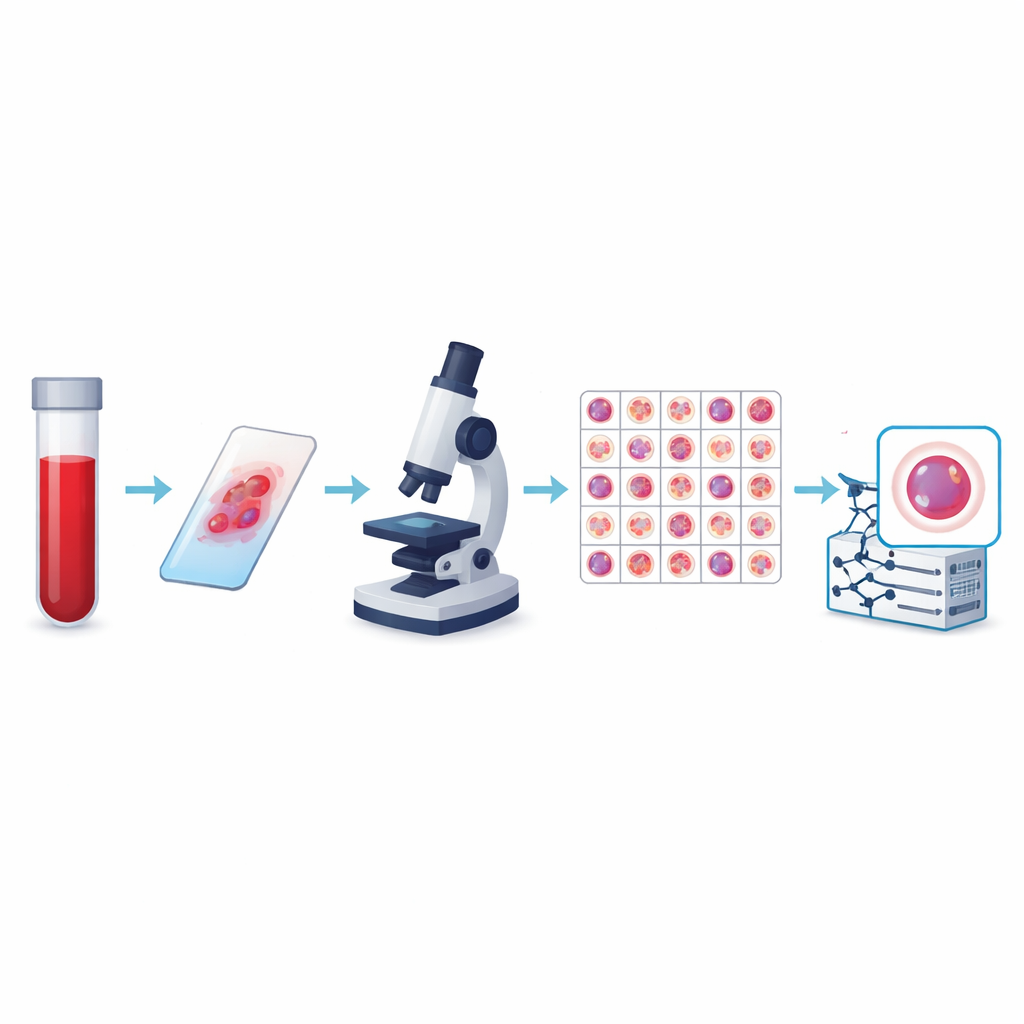
Des simples comptages à l’imagerie intelligente
Les globules blancs sont des défenseurs clés de notre système immunitaire et leur composition et apparence fournissent des indices cruciaux sur notre état de santé. Une augmentation de certains types cellulaires peut signaler une infection ou une allergie, tandis que l’apparition soudaine de cellules immatures « blastiques » peut alerter sur une leucémie. Les laboratoires utilisent déjà des machines automatisées pour compter les cellules, mais les variations subtiles de forme exigent souvent encore l’œil d’un expert. Les évaluations humaines peuvent diverger, et examiner les lames une par une prend du temps. À mesure que la médecine s’appuie davantage sur l’imagerie numérique et l’intelligence artificielle, le besoin de grandes collections d’images fiables augmente pour entraîner des ordinateurs à repérer ces motifs cellulaires caractéristiques avec la même fiabilité qu’un hématologue expérimenté.
Construire une immense bibliothèque de cellules sanguines
Les auteurs ont créé ce qui est actuellement la plus grande collection publique d’images de cellules sanguines périphériques, appelée jeu de données KU-Optofil PBC. Il contient 31 489 images haute résolution de cellules individuelles réparties en 13 classes, incluant des défenseurs courants comme les lymphocytes et les neutrophiles segmentés, ainsi que des types plus rares mais médicalement critiques tels que les blasts, les myélocytes et les lymphocytes réactionnels. Toutes les images proviennent de frottis colorés préparés selon des conditions standardisées dans un même hôpital et acquis avec le même système d’imagerie. Cette cohérence permet aux algorithmes d’apprendre à partir d’une représentation stable et bien contrôlée de chaque type cellulaire plutôt que d’un assemblage d’images hétérogènes incompatibles.
Des yeux d’experts et une curation rigoureuse
Pour rendre le jeu de données fiable, chaque image a été annotée indépendamment par deux techniciens de laboratoire expérimentés, un troisième expert intervenant pour résoudre les désaccords. Des vérifications statistiques ont montré un très fort niveau d’accord entre les évaluateurs pour chaque type cellulaire majeur, y compris un accord parfait pour certains. L’équipe a également appliqué des règles strictes pour décider quelles images conserver, écartant les cellules floues, se chevauchant ou mal colorées. Les images finales ont toutes la même taille et le même format couleur, et elles sont organisées en dossiers d’entraînement, de validation et de test afin que d’autres chercheurs puissent comparer équitablement les algorithmes. Des fichiers supplémentaires relient chaque image à un patient anonymisé, permettant d’étudier si un modèle se généralise véritablement d’une personne à une autre.
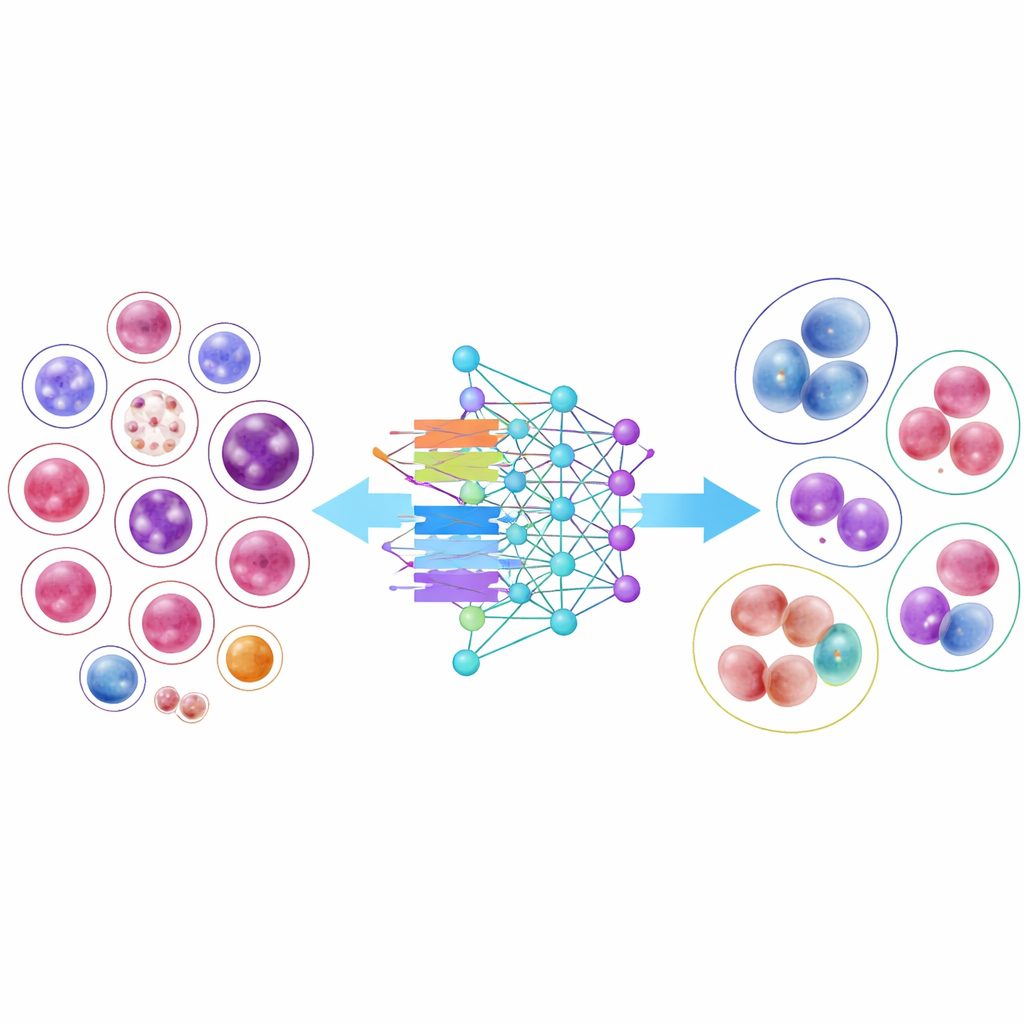
Mettre les modèles d’IA à l’épreuve
Pour montrer l’utilité de cette bibliothèque, les chercheurs ont entraîné 14 modèles modernes de reconnaissance d’images, des réseaux convolutifs classiques aux architectures plus récentes basées sur des transformeurs. Plusieurs modèles compacts et efficaces ont obtenu des performances surprenantes, et une architecture en particulier, DenseNet-121, a correctement classé les cellules plus de 95 % du temps en moyenne. Toutefois, les résultats ont également mis en lumière une difficulté concrète : les types cellulaires courants, disposant de milliers d’exemples, étaient presque parfaitement reconnus, tandis que les cellules très rares, présentes seulement à quelques dizaines d’exemplaires, restaient beaucoup plus difficiles à classer. Même lorsque les chercheurs ont ajusté l’entraînement pour « accorder plus d’attention » à ces classes rares, la précision globale a chuté et les gains pour les types rares sont restés modestes, soulignant le défi d’apprendre à partir d’exemples limités.
Qu’est-ce que cela implique pour les analyses sanguines à venir
Pour les non-spécialistes, le message clé est que ce travail fournit l’expérience visuelle brute dont les systèmes informatiques ont besoin pour devenir des partenaires fiables dans la lecture des frottis sanguins. En assemblant une vaste bibliothèque d’images de cellules sanguines, diverse et soigneusement vérifiée, et en montrant que de nombreux modèles d’IA peuvent en tirer des enseignements, les auteurs posent les bases d’outils susceptibles d’accélérer le diagnostic, de réduire les erreurs humaines et d’apporter un niveau d’analyse expert à des cliniques disposant de moins de spécialistes. Dans le même temps, les résultats mitigés sur les types rares rappellent que même les grands jeux de données ont des angles morts, et que l’amélioration des soins pour les patients atteints de maladies rares ou à un stade précoce exigera l’extension et le raffinement continus de ces collections d’images.
Citation: Yarıkan, A.E., Örer, C., Akyıldız, V. et al. A Large-Scale Peripheral Blood Cell Dataset for Automated Hematological Analysis. Sci Data 13, 417 (2026). https://doi.org/10.1038/s41597-026-06761-y
Mots-clés: imagerie des cellules sanguines, IA médicale, hématologie, apprentissage profond, jeux de données médicaux