Clear Sky Science · fr
BRISC : jeu de données annotées pour la segmentation et la classification des tumeurs cérébrales
Pourquoi les données d’imagerie cérébrale comptent pour tous
Les tumeurs cérébrales font partie des diagnostics les plus redoutés, et les cliniciens s’appuient de plus en plus sur des logiciels pour repérer et délimiter ces masses dans les images IRM. Mais, comme des étudiants qui apprendraient sur un manuel auquel il manque des pages, beaucoup de systèmes d’intelligence artificielle (IA) sont freinés par des données incomplètes ou incohérentes. Cet article présente BRISC, une nouvelle collection soigneusement assemblée d’images IRM cérébrales conçue pour fournir à l’IA médicale des exemples de haute qualité afin d’améliorer la détection et la cartographie des tumeurs cérébrales — un travail qui pourrait, à terme, soutenir des diagnostics plus rapides et plus fiables. 
Une nouvelle bibliothèque d’images cérébrales
Le jeu de données BRISC regroupe 6 000 images IRM cérébrales centrées sur un type d’acquisition précis — les images pondérées T1 avec produit de contraste — qui font particulièrement ressortir les bords des tumeurs. Chaque image appartient à l’un des quatre groupes suivants : trois types de tumeurs courantes (gliome, méningiome et tumeur hypophysaire) ainsi qu’un groupe non tumoral incluant des cerveaux sains et d’autres conditions non cancéreuses. Les images proviennent de plusieurs collections publiques antérieures, mais BRISC ajoute ce qui manquait à ces ensembles : des contours précis des régions tumorales et des étiquettes cohérentes, créés et vérifiés par des experts médicaux.
Équilibrer vues et types de tumeurs
Un problème majeur de nombreuses collections existantes est le déséquilibre : certains types de tumeurs ou angles d’acquisition dominent, poussant les modèles d’IA à bien fonctionner uniquement sur les motifs les plus fréquents. BRISC s’attaque à cela en offrant une répartition plus homogène des diagnostics et des directions de vue. Les images sont fournies selon trois plans IRM standard — axial (vue de dessus), coronal (avant‑arrière) et sagittal (latéral) — avec des effectifs similaires pour chacun. Les quatre catégories diagnostiques sont également maintenues relativement équilibrées dans les partitions d’entraînement et de test. Cette conception soigneuse aide les algorithmes futurs à apprendre à reconnaître les tumeurs depuis plusieurs angles et dans une gamme plus large de situations, reflétant mieux ce que voient réellement les praticiens en clinique.
Nettoyage soigné et délimitations d’experts
Transformer des scans bruts en une ressource de recherche fiable a nécessité un nettoyage substantiel. L’équipe a commencé avec plus de 7 000 images issues d’une collection populaire en ligne sur les tumeurs cérébrales et a éliminé les scans de mauvaise qualité ou corrompus, les quasi‑doublons et les séquences trop courtes pour une interprétation fiable. Seules les acquisitions T1 avec contraste ont été conservées pour garantir la cohérence. Des médecins et un radiologue ont ensuite revu les images, corrigeant les étiquettes erronées et supprimant les cas douteux. À l’aide d’un outil de labellisation spécialisé, ils ont dessiné des masques détaillés autour des régions tumorales, affinant leur travail de manière itérative jusqu’à obtenir un fort accord ; sur un sous‑ensemble test, la concordance entre contours initiaux et contours validés par les experts était très élevée. 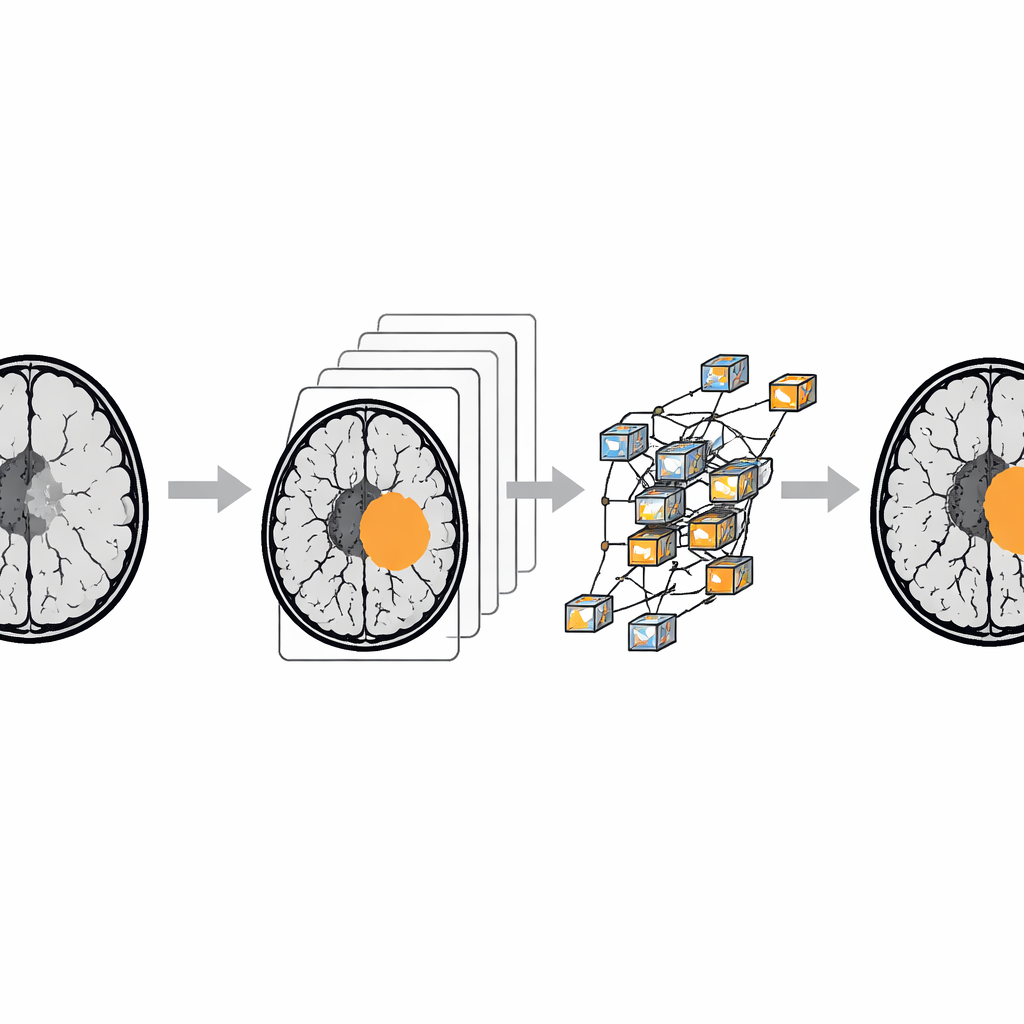
Ce que ces données permettent pour les modèles d’IA
Pour démontrer l’usage de BRISC, les auteurs ont entraîné plusieurs modèles d’IA populaires sur deux tâches. La première tâche demande au modèle de classer chaque image dans l’une des quatre catégories diagnostiques. Les systèmes modernes de reconnaissance d’images, notamment la famille EfficientNet, ont atteint une très grande précision — étiquetant correctement la grande majorité des scans et réussissant particulièrement bien à distinguer les images sans tumeur. La seconde tâche demande aux modèles de colorer la zone tumorale, pixel par pixel, sur la coupe IRM. Ici, des réseaux de segmentation plus avancés, y compris des architectures basées sur des transformers qui excellent à modéliser le contexte, ont fourni les meilleurs scores, délimitant avec précision les tumeurs pour les trois principaux types tumoraux.
Comment ce travail fait progresser le domaine
Concrètement, BRISC est un « terrain d’entraînement » public et bien organisé pour des ordinateurs apprenant à lire des IRM cérébrales. Il offre des milliers de scans soigneusement nettoyés, une variété réaliste de types de tumeurs et d’angles d’acquisition, et des contours tumoraux dessinés par des experts qui indiquent précisément où la maladie est présente. Bien que le jeu de données soit destiné à la recherche — et non comme un outil diagnostique autonome pour les patients — il fournit une base solide pour construire et comparer de nouveaux systèmes d’IA. À mesure que les chercheurs affinent leurs modèles en utilisant BRISC et des ressources similaires, les médecins pourraient un jour disposer d’assistants numériques plus fiables, les aidant à détecter les tumeurs cérébrales plus tôt et à planifier les traitements avec une confiance accrue.
Citation: Fateh, A., Rezvani, Y., Moayedi, S. et al. BRISC: Annotated Dataset for Brain Tumor Segmentation and Classification. Sci Data 13, 361 (2026). https://doi.org/10.1038/s41597-026-06753-y
Mots-clés: IRM tumeur cérébrale, imagerie médicale IA, segmentation de tumeur, curation de jeu de données, apprentissage profond en radiologie