Clear Sky Science · fr
Un ensemble d’images histopathologiques à haute résolution pour le diagnostic et le pronostic du carcinome épidermoïde oral
Pourquoi cette recherche compte
Le cancer de la bouche peut rester caché à la vue, débutant par une petite plaie dans la cavité buccale avant d’évoluer en une maladie potentiellement mortelle. Les médecins s’appuient sur des images microscopiques de tissus pour évaluer la gravité d’une tumeur et la probabilité qu’elle récidive ou se propage, mais l’analyse de ces lames est un travail lent et exigeant. Cette étude présente une nouvelle collection d’images riche conçue pour aider les systèmes d’intelligence artificielle (IA) à lire ces lames aux côtés des pathologistes, avec l’objectif à long terme de fournir aux patients des réponses plus rapides et plus précises sur leur maladie et leurs options thérapeutiques.
Regarder de plus près un cancer buccal fréquent
Le travail se concentre sur le carcinome épidermoïde oral, l’un des cancers de la bouche les plus fréquents et agressifs. Il survient souvent chez des personnes ayant des antécédents de tabac ou d’alcool et peut se propager aux tissus voisins et aux ganglions lymphatiques du cou. Aujourd’hui, la référence pour le diagnostic reste l’examen visuel du pathologiste sur des coupes colorées au microscope. À partir de ces lames, les experts jugent l’anormalité des cellules, la profondeur d’invasion de la tumeur, son envahissement des nerfs ou des vaisseaux sanguins, et de nombreuses autres caractéristiques influençant la survie. Les auteurs soutiennent que ces motifs microscopiques renferment bien plus d’informations que ce qu’un humain peut suivre facilement, ce qui en fait une cible idéale pour l’IA moderne.
Construire une image plus riche à partir des tissus
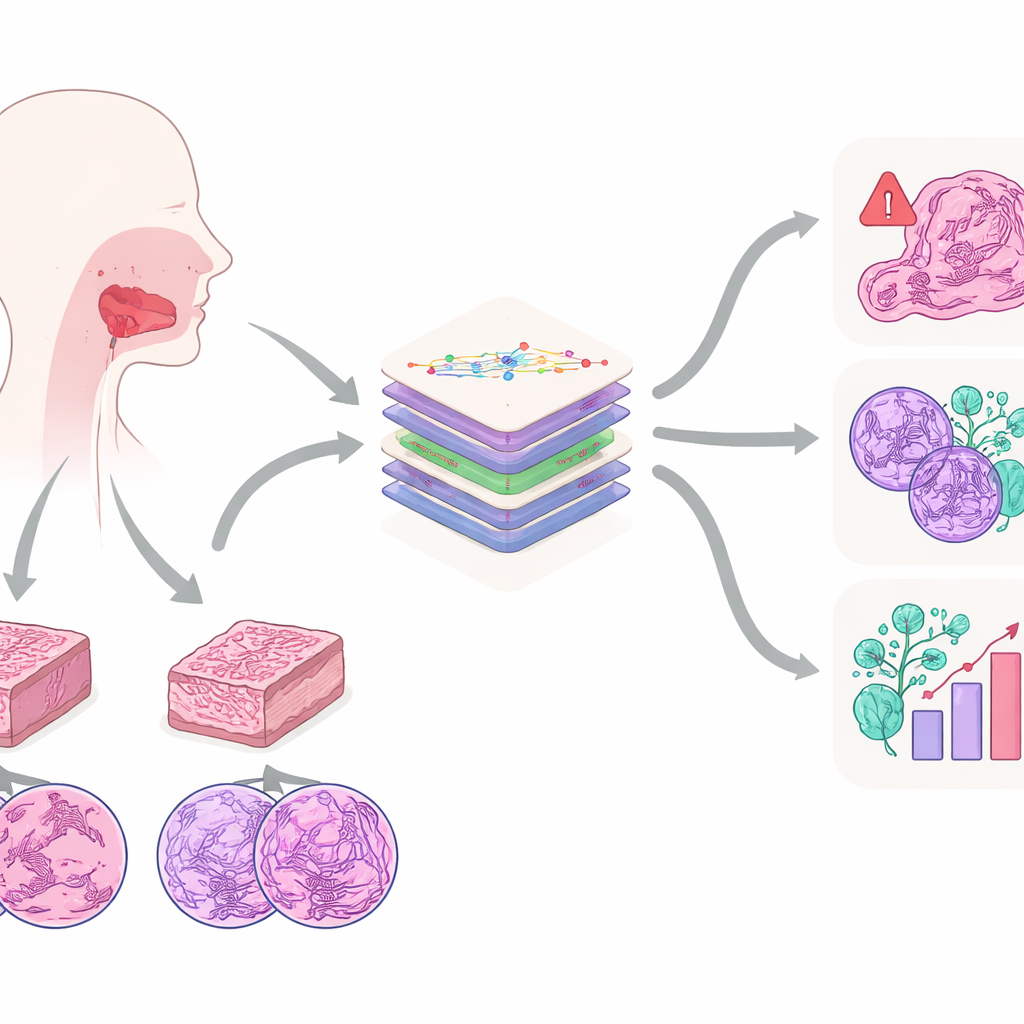
Pour exploiter cette information, l’équipe a créé le jeu de données Multi‑OSCC : des images microscopiques de 1 325 patients traités pour cancer buccal dans un même hôpital entre 2015 et 2022. Pour chaque patient, les pathologistes ont préparé deux blocs de tissu — un issu du centre de la tumeur et un de son bord invasif — puis ont capturé des images à haute résolution à trois niveaux d’agrandissement, comparable à la vue d’une ville depuis un avion, un toit et un coin de rue. Cela a produit six images soigneusement choisies par patient, chacune contenant des structures clés telles que des amas de cellules tumorales, des enroulements de kératine et des noyaux cellulaires fortement atypiques. En parallèle des images, les chercheurs ont rassemblé des dossiers médicaux détaillés et un suivi à long terme pour savoir quelles tumeurs ont récidivé ou se sont propagées.
Six questions qui intéressent vraiment les médecins
Ce qui distingue Multi‑OSCC, c’est qu’il reflète des questions cliniques réelles au lieu de se concentrer sur une seule étiquette. Chaque patient du jeu de données est annoté selon six résultats importants. L’un d’eux est de savoir si la tumeur a récidivé dans les deux années suivant la chirurgie, une fenêtre critique où surviennent la plupart des rechutes. Un autre est de savoir si des cellules cancéreuses avaient déjà atteint les ganglions du cou, ce qui oriente la décision d’une chirurgie cervicale plus étendue. Quatre étiquettes supplémentaires renseignent sur le degré de différenciation des cellules tumorales, la profondeur d’invasion, et si la tumeur est entrée dans les vaisseaux sanguins ou s’est propagée le long des nerfs — des indices subtils mais puissants de la dangerosité du cancer. Cette conception permet aux modèles d’IA d’apprendre non seulement « cancer versus normal », mais un tableau plus complet du risque et de la sévérité.
Apprendre à l’IA à lire des lames complexes
Les chercheurs ont ensuite évalué comment différentes stratégies d’IA traitent ce jeu de données exigeant. Ils ont comparé plusieurs architectures modernes de reconnaissance d’images, incluant à la fois des réseaux convolutionnels classiques et des modèles plus récents basés sur des transformers, et ont constaté que les transformers pré‑entraînés spécifiquement sur des images de pathologie offraient les meilleures performances globales. Ils ont testé des façons de combiner les informations provenant des six images par patient et découvert qu’une stratégie simple — extraire des caractéristiques de chaque image puis les concaténer — surpassait des schémas de fusion plus élaborés. Ils ont aussi examiné l’effet de la standardisation des couleurs des colorations : conserver la couleur d’origine s’est avéré crucial pour prédire la récidive, tandis qu’une normalisation douce des couleurs aidait pour les autres tâches diagnostiques.
Limites, surprises et perspectives
Une surprise a été que l’entraînement d’un seul modèle d’IA pour traiter simultanément les six questions ne dépassait pas encore les modèles entraînés séparément pour chaque tâche. Autre constat : les images microscopiques détaillées, bien que riches en informations cellulaires, manquent encore de la vue architecturale large fournie par des lames entières. Néanmoins, les modèles entraînés sur les images Multi‑OSCC ont clairement surpassé ceux n’utilisant que des données cliniques comme l’âge, les habitudes et les antécédents médicaux, en particulier pour prédire la récidive tumorale. Les auteurs présentent Multi‑OSCC comme un point de départ : un jeu de données public et bien documenté que d’autres pourront utiliser pour développer et comparer des méthodes. Pour les patients, la promesse à long terme est que les outils futurs construits sur cette ressource pourraient aider les médecins à mieux identifier quelles tumeurs orales risquent de récidiver ou de se propager, permettant des traitements plus personnalisés et, en fin de compte, de meilleures chances de survie.
Citation: Guan, J., Guo, J., Chen, Q. et al. A High Magnifications Histopathology Image Dataset for Oral Squamous Cell Carcinoma Diagnosis and Prognosis. Sci Data 13, 371 (2026). https://doi.org/10.1038/s41597-026-06736-z
Mots-clés: cancer buccal, images histopathologiques, intelligence artificielle, apprentissage profond, jeux de données d’imagerie médicale