Clear Sky Science · fr
StatLLM : Un jeu de données pour évaluer les performances des grands modèles de langage en analyse statistique
Pourquoi cela importe pour les utilisateurs de données au quotidien
À mesure que des outils d’intelligence artificielle comme les assistants conversationnels entrent dans le quotidien professionnel, de plus en plus de personnes leur demandent de traiter des nombres, d’exécuter des expériences et d’analyser des données. Mais quand une IA écrit le code d’une étude statistique — par exemple pour vérifier si un nouveau traitement médical fonctionne ou pour explorer des données sur les performances scolaires — comment savoir si le travail a été fait correctement ? Cet article présente StatLLM, un jeu de données public conçu pour tester la capacité des grands modèles de langage à traiter des tâches d’analyse statistique réelles, offrant aux chercheurs et aux praticiens une meilleure visibilité sur les cas où l’on peut faire confiance au code produit par l’IA — et ceux où il convient d’être prudent.
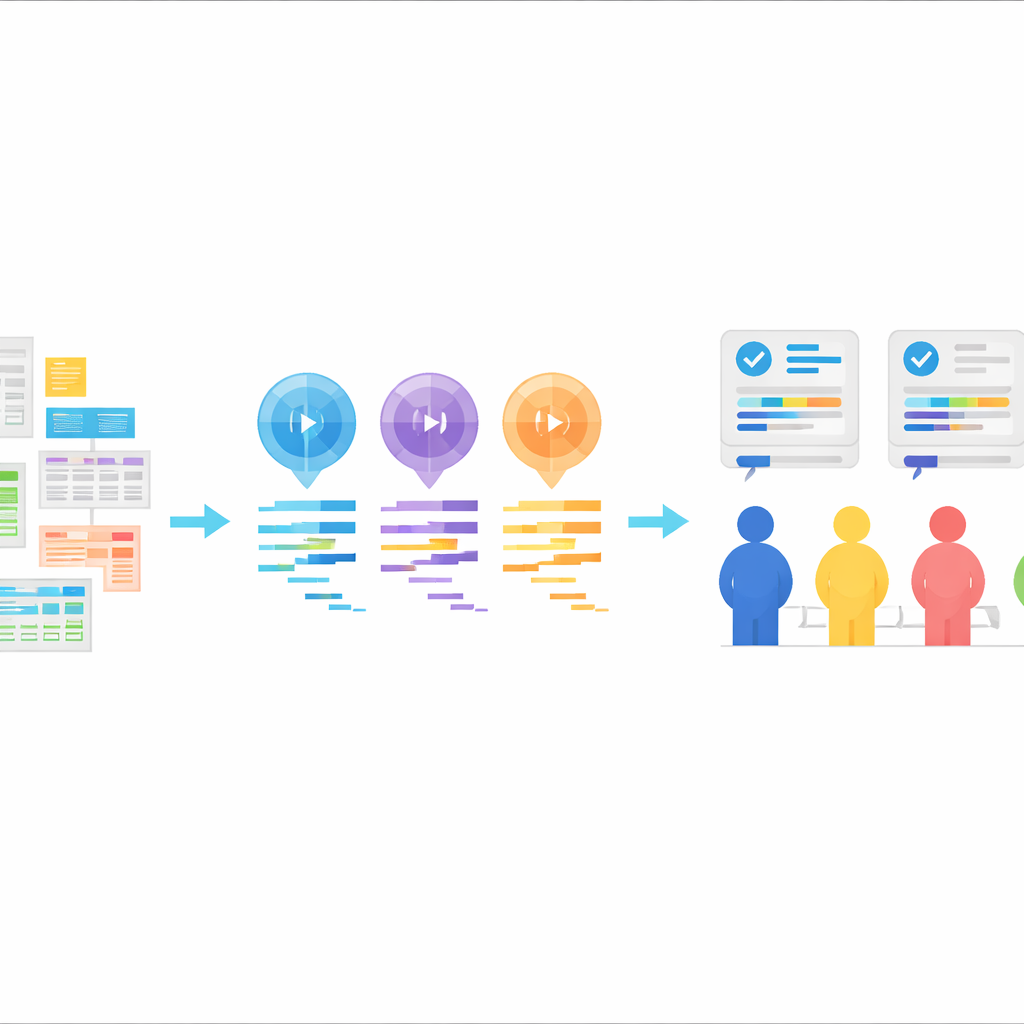
Un nouveau banc d’essai pour le code statistique généré par l’IA
Le cœur de StatLLM est une collection soigneusement constituée de 207 tâches d’analyse statistique issues de 65 jeux de données réels provenant de domaines tels que l’éducation, la médecine, le commerce, la finance, l’ingénierie et le sport. Chaque tâche est accompagnée d’une description en langage courant, d’une explication détaillée du jeu de données et de ses variables, et d’un court extrait de code SAS rédigé et vérifié par des experts humains. Les tâches couvrent ce qu’un bon étudiant de licence ou de master en statistiques pourrait apprendre : des résumés et graphiques simples aux régressions, analyses de survie et méthodes plus avancées. Cela fournit un test réaliste, à la fois académique et industriel, pour savoir si les outils d’IA comprennent des questions pratiques et les traduisent en étapes d’analyse fiables.
Laisser l’IA écrire le code, puis évaluer son travail
À partir de ces tâches, les auteurs ont demandé à trois grands modèles de langage — GPT-3.5, GPT-4 et Llama‑3.1 70B — de générer du code SAS. Chaque modèle a reçu les mêmes éléments : une description de la tâche, une description du jeu de données, le fichier de données lui‑même et une instruction explicite de produire du code SAS. Les modèles ont été utilisés en « zero-shot », c’est‑à‑dire sans recevoir d’exemples de code SAS correct au préalable. Leurs réponses ont été nettoyées pour ne conserver que le code, sans explications. Ce protocole imite un schéma courant en pratique : un utilisateur décrit ce qu’il veut, l’IA renvoie du code, et ce code est ensuite exécuté dans un logiciel statistique.
Des experts humains comme référence
Pour évaluer la qualité réelle du code généré par l’IA, l’équipe a organisé une revue humaine rigoureuse. Neuf utilisateurs expérimentés de SAS se sont réunis en trois groupes, chacun se concentrant sur un volet de la performance : la correction logique et la lisibilité du code lui‑même, sa capacité à s’exécuter sans erreurs, et si les résultats obtenus répondaient clairement et précisément à la question initiale. Pour chaque tâche, les programmes SAS provenant des trois modèles ont été mélangés de sorte que les évaluateurs ne sachent pas quel modèle a produit quel code. Des notes ont été attribuées sur une échelle de cinq points et combinées en un score global, offrant une vue nuancée des forces et faiblesses à travers des centaines de paires modèle–tâche. Ces évaluations d’experts accompagnent désormais l’ensemble des codes et des tâches du jeu de données StatLLM.
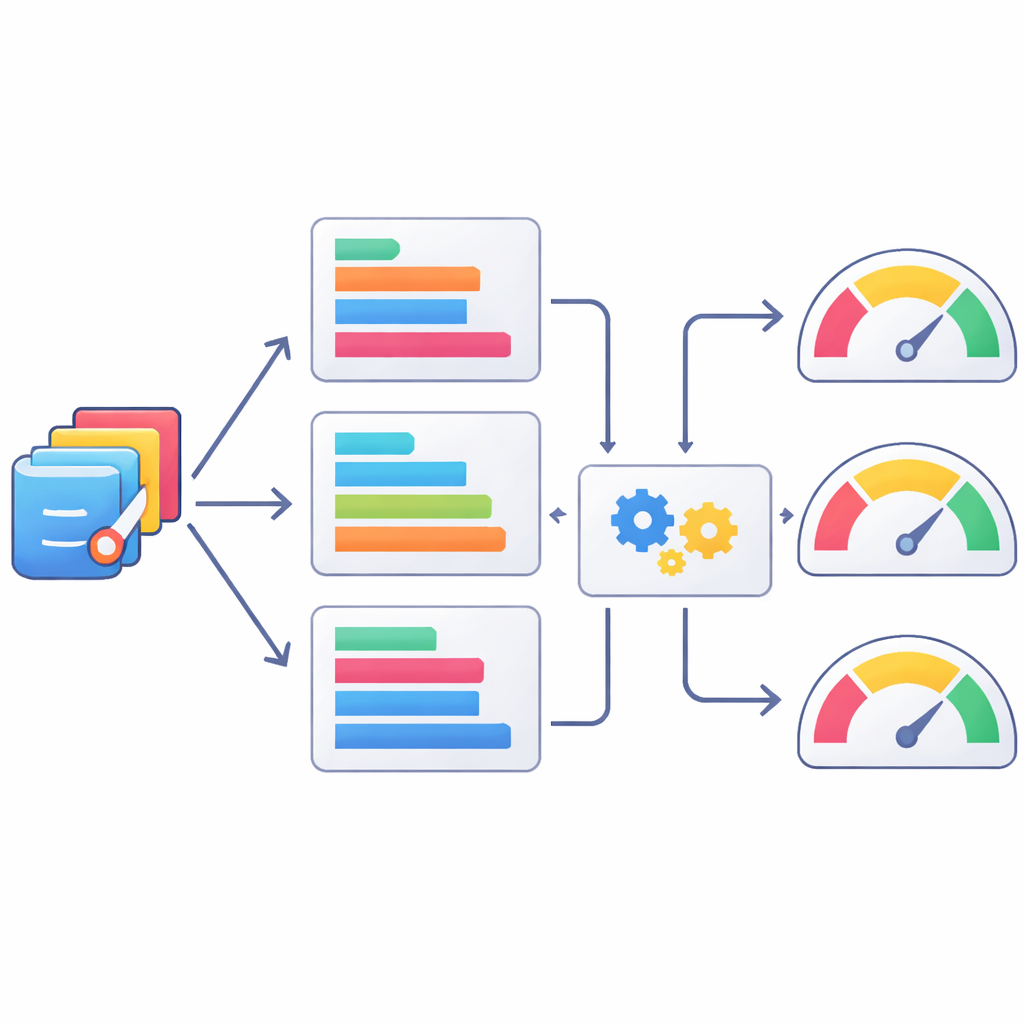
Apprendre aux machines à juger le code comme les humains
Comme la revue humaine est lente et coûteuse, les auteurs ont aussi étudié dans quelle mesure des métriques textuelles automatiques peuvent servir d’estimateurs approximatifs de la qualité du code statistique. Ils ont comparé les programmes SAS générés par l’IA aux versions vérifiées par des humains en utilisant un ensemble de scores bien connus en traitement automatique du langage, puis ont vérifié la corrélation de ces scores avec les évaluations humaines. Certaines métriques, comme des variantes du score ROUGE qui mesurent les recouvrements de courtes séquences de tokens, se sont mieux alignées avec les jugements humains que d’autres, mais toutes n’étaient que modérément corrélées. L’équipe est allée plus loin en entraînant des modèles d’apprentissage automatique pour prédire les notes humaines à partir de combinaisons de ces métriques. Des méthodes comme XGBoost ont amélioré l’accord avec les évaluations humaines, sans toutefois parvenir à reproduire parfaitement le jugement d’un expert, soulignant que les scores automatiques restent, au mieux, des proxys partiels.
Vers des outils statistiques pilotés par l’IA
Au‑delà du benchmarking, les auteurs montrent comment StatLLM peut soutenir de nouveaux outils et axes de recherche. Parce que chaque tâche est décrite en termes généraux, les mêmes problèmes peuvent servir à tester la génération de code dans d’autres langages comme R ou Python, ou même à combiner du code issu de plusieurs langages. L’article met en évidence des approches ensemblistes susceptibles de mixer différentes solutions générées par l’IA pour gagner en fiabilité, et présente un prototype d’application R Shiny où les utilisateurs téléversent un jeu de données et une description de tâche, et un système d’IA produit et exécute automatiquement du code R. StatLLM fournit aussi une plateforme pour concevoir et tester des logiciels statistiques de nouvelle génération capables de comprendre des instructions en langage naturel tout en étant soumis à des critères clairs et mesurables.
Ce que cela signifie pour l’usage de l’IA en analyse de données
Pour les non‑spécialistes, la conclusion principale est que l’IA sait déjà écrire de courts morceaux de code statistique — mais la fiabilité est loin d’être garantie, surtout pour des tâches qui dépassent des exemples simples. StatLLM offre un moyen transparent et réutilisable d’évaluer les performances des différents modèles, d’améliorer les contrôles automatiques de leur travail et de concevoir des outils d’analyse de données plus sûrs et robustes. À mesure que des modèles de langage plus récents apparaîtront, ils pourront être intégrés à ce benchmark vivant, permettant de maintenir la communauté informée sur ce que l’IA sait et ne sait pas encore faire dans le cadre d’un travail statistique sérieux.
Citation: Song, X., Lee, L., Xie, K. et al. StatLLM: A Dataset for Evaluating the Performance of Large Language Models in Statistical Analysis. Sci Data 13, 369 (2026). https://doi.org/10.1038/s41597-026-06731-4
Mots-clés: grands modèles de langage, analyse statistique, évaluation de code, jeu de données de référence, programmation SAS