Clear Sky Science · fr
Un jeu de données de citations scientifiques dans les Office Actions de l'Office américain des brevets
Pourquoi les citations de brevets comptent pour l'innovation quotidienne
Lorsque vous entendez parler d'un nouveau gadget, d'un médicament ou d'une technologie d'énergie propre, il y a généralement une piste d'idées derrière. Une grande partie de cette piste est consignée dans les brevets et les documents qu'ils citent. Cet article présente un nouveau jeu de données volumineux qui révèle, avec un niveau de détail inhabituel, sur quelles recherches scientifiques les examinateurs de brevets s'appuient lorsqu'ils décident si une invention mérite une protection. En ouvrant cette fenêtre cachée sur le processus d'examen, les auteurs offrent aux chercheurs, aux décideurs et même aux citoyens curieux un nouveau moyen d'étudier comment le savoir scientifique alimente l'innovation dans le monde réel.
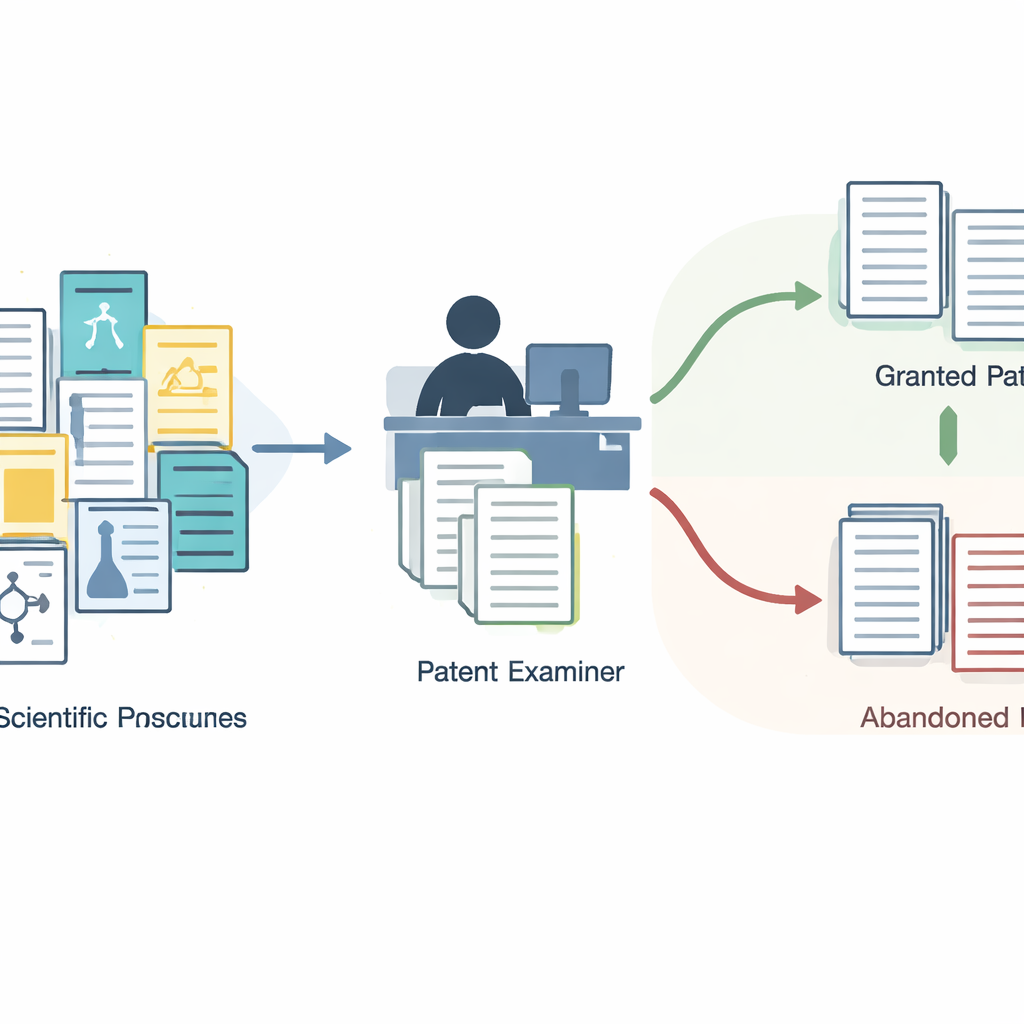
Une couche cachée du processus de brevet
La plupart des études sur les brevets se limitent aux citations imprimées sur la première page des brevets délivrés. Ces listes semblent simples, mais elles sont le résultat final d'un va‑et‑vient complexe entre les demandeurs et les examinateurs gouvernementaux. En cours de route, les examinateurs envoient des lettres formelles appelées Office Actions, où ils expliquent pourquoi un brevet doit être accepté ou rejeté et y référencent des travaux antérieurs qu'ils jugent importants. Beaucoup de ces éléments cités, en particulier les articles scientifiques, n'apparaissent jamais sur le brevet final. Jusqu'à présent, ils étaient difficiles à consulter en masse, ce qui a amené la recherche à négliger en grande partie cet enregistrement riche de la manière dont les décisions sont réellement prises.
Construire une nouvelle carte à partir des Office Actions
Les auteurs exploitent un trésor de données d'Office Actions publié par l'Office américain des brevets et des marques et hébergé sur Google Cloud. À partir de millions de références, ils isolent environ 850 000 éléments qui ne renvoient pas à d'autres brevets, mais plutôt à des sources externes telles que des articles de revues, des livres, des sites web et des manuels produits. Ils conçoivent un schéma comportant 14 catégories courantes — allant des livres et actes de conférence aux pages web et documentations produit — puis entraînent un modèle d'apprentissage automatique pour classer chaque citation dans l'un de ces types. Ce modèle, affiné à l'aide d'exemples étiquetés avec l'aide d'un système de langage avancé, classe près de 847 000 chaînes de citation uniques.
Des références désordonnées à des dossiers de recherche propres
Identifier quelles citations sont scientifiques n'est que la première étape. Les références du monde réel sont en désordre : les titres peuvent être incomplets, les années mal saisies et les numéros de page mélangés. Pour transformer cet enchevêtrement en données exploitables, l'équipe alimente les chaînes brutes dans un outil spécialisé qui les analyse en éléments tels que auteur, année, revue et plage de pages, tout en appliquant des règles de nettoyage strictes. Ils associent ensuite ces enregistrements nettoyés à OpenAlex, une grande base de données ouverte de publications de recherche, en utilisant deux stratégies. Lorsqu'un titre est disponible, ils recherchent par titre et ne conservent que les correspondances de haute confiance ; lorsqu'il ne l'est pas, ils s'appuient sur des combinaisons de noms d'auteurs, de revue, d'année et de pages. Si OpenAlex ne trouve pas de correspondance, ils se tournent vers Crossref, une autre source majeure d'identifiants de publications, puis reviennent vers OpenAlex à l'aide de tout identifiant d'objet numérique découvert.
Quelle est la fiabilité du nouveau jeu de données ?
Parce que cette ressource est destinée à étayer de futures études, les auteurs consacrent des efforts substantiels à tester son exactitude. Leur classificateur attribue correctement les références au bon type dans environ 92 % des cas au global, et il fonctionne particulièrement bien sur les classes les plus courantes comme les articles de revues et les brevets. Pour l'étape d'appariement, des vérifications manuelles montrent que les recherches basées sur le titre deviennent plus précises à mesure que le score de correspondance augmente, atteignant les années 90 en pourcentage dans le groupe le meilleur, tandis que les recherches basées sur des métadonnées détaillées sont correctes à 99 % dans un échantillon. Des contre‑vérifications des enregistrements récupérés via Crossref montrent également un accord quasi parfait. Les auteurs sont transparents sur les points faibles — comme les catégories rares telles que les thèses ou les rapports techniques — et encouragent les utilisateurs à affiner ces aspects si nécessaire.
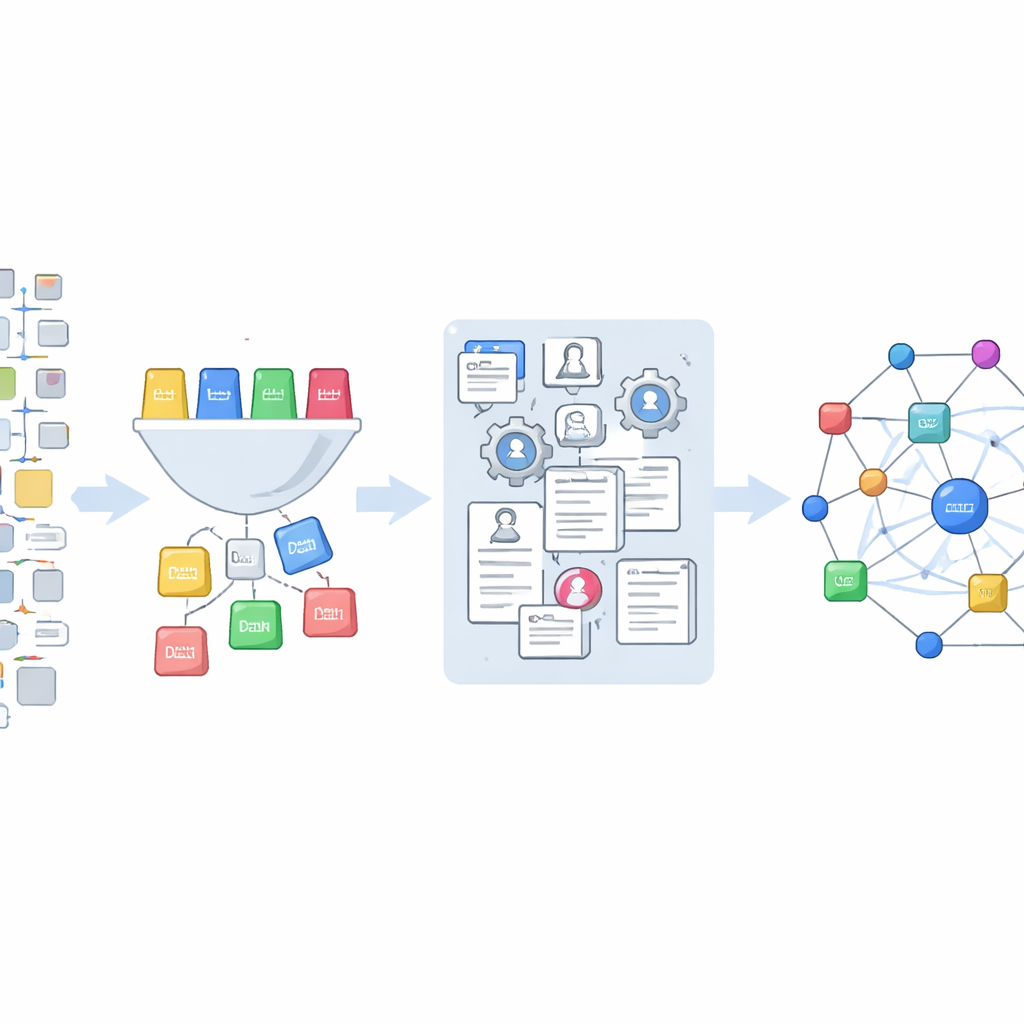
De nouvelles façons d'étudier comment la science stimule la technologie
Le jeu de données final relie environ 265 000 références scientifiques extraites des Office Actions aux demandes de brevet américaines individuelles et aux enregistrements de publication riches d'OpenAlex. Cela permet aux chercheurs de poser de nouveaux types de questions : dans quelle mesure différents groupes d'examinateurs ou domaines technologiques s'appuient‑ils sur des articles scientifiques ? Quelles études sont jugées importantes pendant l'examen mais disparaissent du brevet final ? Les brevets abandonnés s'appuient‑ils sur un pan différent du patrimoine scientifique par rapport aux brevets aboutis ? Parce que tout le code et les données sont publiés ouvertement, d'autres peuvent adapter les outils, étendre la couverture et affiner les classifications. En termes simples, ce travail transforme un ensemble obscur et dispersé de documents juridiques en une carte claire et réutilisable montrant comment la science et la technologie se rencontrent au sein du système des brevets.
Citation: Higham, K., Kotula, H., Scharfmann, E. et al. A dataset of scientific citations in U.S. patent Office Actions. Sci Data 13, 325 (2026). https://doi.org/10.1038/s41597-026-06720-7
Mots-clés: citations de brevets, office actions, littérature scientifique, données d'innovation, OpenAlex