Clear Sky Science · fr
Un ensemble de données IMU complet pour évaluer les dispositions de capteurs dans la reconnaissance d’activité humaine et d’intensité
Pourquoi votre tracker de fitness tient à l’endroit où il se situe
Les montres d’activité et les podomètres promettent de suivre tout, de votre promenade quotidienne à votre séance de sport. Mais sous ces bracelets épurés se cache une question de conception étonnamment délicate : où placer les capteurs sur le corps pour qu’ils captent suffisamment nos mouvements sans nous transformer en robots câblés ? Cette étude présente un nouvel ensemble de données riche qui aide les chercheurs à répondre précisément à cette question, montrant comment différentes configurations portables peuvent lire ce que nous faisons et à quelle intensité nous le faisons.
Beaucoup de trackers, une grande zone d’ombre
La reconnaissance d’activité humaine est la technologie qui permet aux appareils d’inférer si vous êtes assis, en train de marcher, de courir ou de faire du vélo à partir de données de mouvement. Les caméras peuvent aussi le faire, mais les capteurs portés sur le corps conviennent mieux à une utilisation prolongée, respectueuse de la vie privée, à la maison, en clinique et au quotidien. Cependant, la plupart des ensembles de données existants pour cette recherche ne placent que quelques capteurs sur des parties sélectionnées du corps — comme un téléphone dans la poche ou un seul bracelet au poignet. Cette vue limitée rend difficile l’étude d’un compromis important : combien de capteurs, et où, sont réellement nécessaires pour reconnaître avec précision les activités et leur intensité tout en restant confortables et pratiques à porter ?
Construire une carte du mouvement du corps entier
Pour combler cette lacune, les chercheurs ont collecté des données de mouvement auprès de 30 jeunes adultes en bonne santé pendant qu’ils effectuaient 12 activités courantes, notamment s’allonger, s’asseoir, se tenir debout, plusieurs vitesses de marche, monter des escaliers, faire du vélo, courir, sauter et ramer. Chaque personne portait 17 petites unités de mouvement réparties de la tête aux pieds : sur la tête, le haut du dos, le bas du dos, les épaules, les bras, les poignets, les cuisses, les tibias et les pieds. Ces unités ont enregistré comment chaque segment du corps bougeait en trois dimensions, 60 fois par seconde, dans un système de coordonnées global cohérent. L’équipe a aussi relevé des mesures corporelles de base, comme la taille et la longueur des membres, et a soigneusement étiqueté à la fois le type d’activité et son niveau d’effort, de sédentaire à vigoureux, selon des tables standard de dépense énergétique.
Du mouvement brut à des motifs reconnaissables
Une fois les données collectées, les signaux ont été découpés en courtes fenêtres temporelles chevauchantes allant d’une demi-seconde à 10 secondes. Pour les modèles d’apprentissage automatique traditionnels, l’équipe a distillé chaque fenêtre en ensembles de caractéristiques conçues à la main qui décrivent le comportement des signaux dans le temps et en fréquence, comme leurs moyennes, leur variabilité et leurs rythmes dominants. Ils ont ensuite entraîné quatre modèles largement utilisés — deux approches classiques et deux réseaux profonds — sur deux tâches : distinguer les 12 activités et les regrouper en quatre niveaux d’effort. Tous les entraînements et tests ont été réalisés de façon « sujet-indépendant » : les données de chaque personne n’apparaissaient que dans un rôle, garantissant que les modèles apprenaient vraiment des motifs généraux plutôt que de mémoriser le style de mouvement d’un individu.
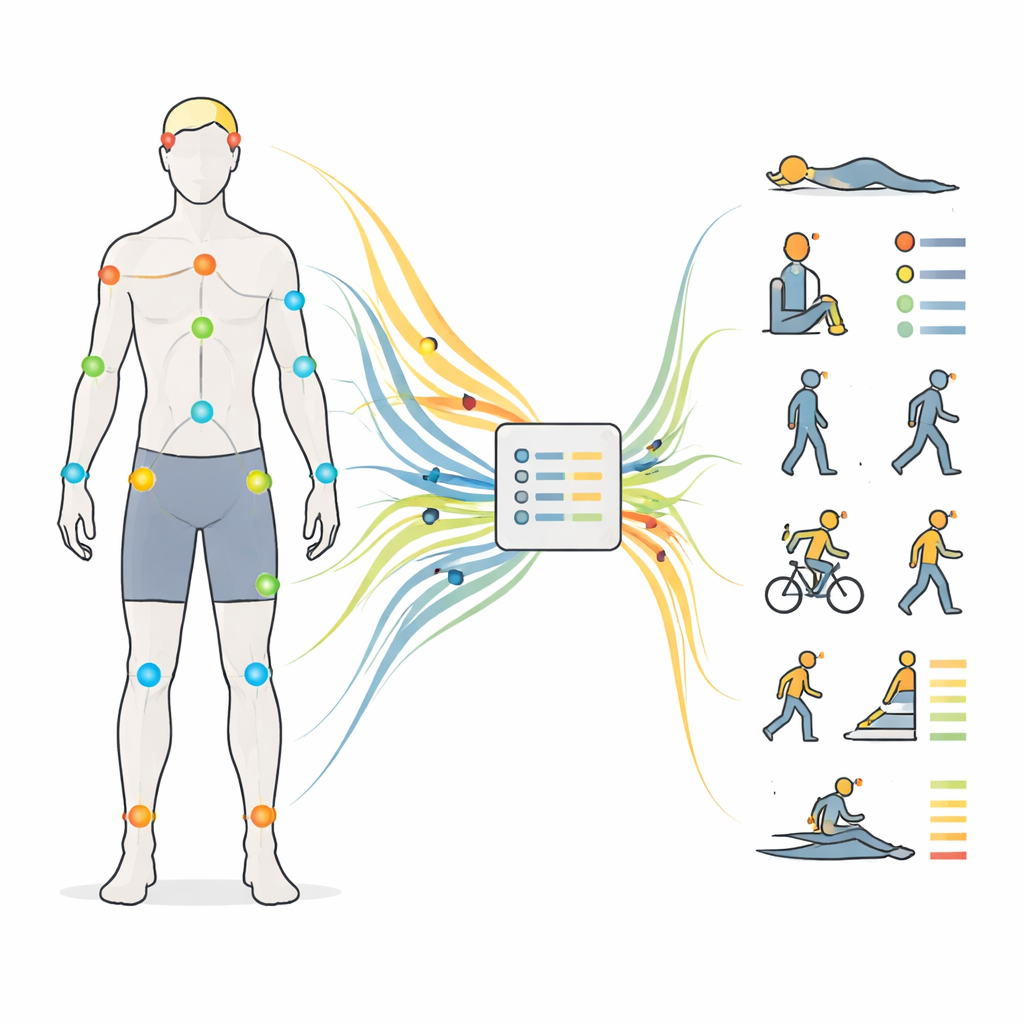
Ce qui compte vraiment : le temps et le placement
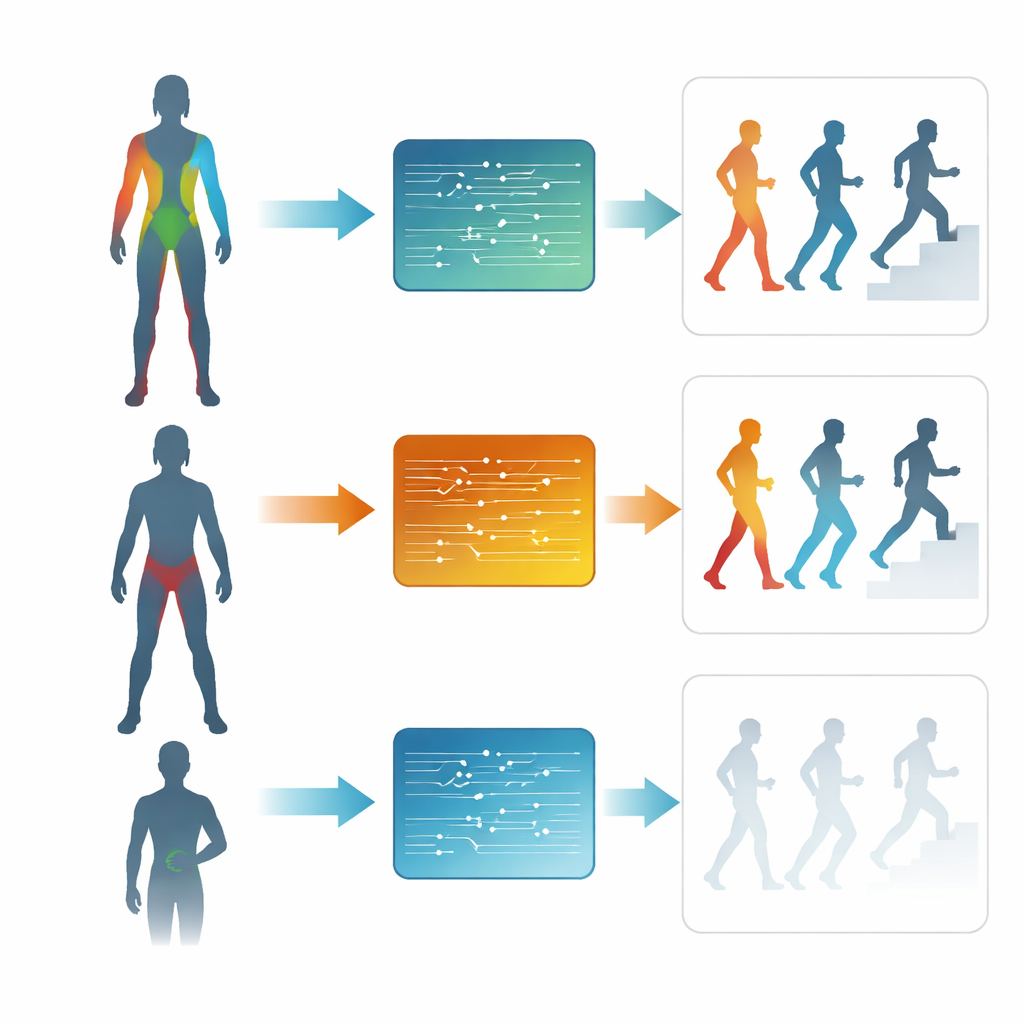
Les résultats montrent que, avec des caractéristiques correctement choisies, les modèles classiques peuvent reconnaître les activités avec environ 96–97 % de précision et les niveaux d’effort encore plus fiablement. Les modèles de deep learning entraînés directement sur les signaux bruts obtiennent des performances presque équivalentes, en particulier sur des fenêtres temporelles courtes. Toutes approches confondues, des fenêtres d’environ 2–5 secondes trouvent le meilleur compromis entre réactivité et classification fiable : assez longues pour capturer le rythme de la marche ou de l’aviron, mais suffisamment courtes pour être utiles en retour d’information en temps réel. En examinant le placement des capteurs, les résultats sont frappants. Une configuration axée sur le bas du corps — hanches, cuisses, tibias et pieds — égalise souvent ou dépasse même la performance d’une couverture du corps entier, en particulier pour estimer l’intensité. Une configuration minimale à trois capteurs sur le bas du dos, la cuisse et le tibia atteint toujours plus de 90 % de précision, tandis que les configurations à capteur unique, notamment au poignet, sont sensiblement moins performantes.
Concevoir des wearables plus intelligents et plus légers
Ce nouvel ensemble de données suggère que davantage de capteurs n’est pas toujours synonyme de meilleurs résultats : pour les mouvements quotidiens dominés par les jambes, un groupe compact et bien choisi de capteurs peut rivaliser avec des systèmes beaucoup plus complexes. Cette idée peut guider la conception de futurs appareils portables plus légers, moins chers et plus faciles à utiliser, tout en restant capables de suivre de façon fiable à la fois ce que font les personnes et l’intensité de leurs efforts. En rendant l’ensemble de données complet et le code publics, les auteurs fournissent un banc d’essai pour affiner les dispositions de capteurs, explorer de nouveaux algorithmes et, finalement, étendre ces outils aux personnes âgées, aux patients et à des contextes réels plus variés.
Citation: Feng, M., Zhang, Q. & Fang, H. A comprehensive IMU dataset for evaluating sensor layouts in human activity and intensity recognition. Sci Data 13, 317 (2026). https://doi.org/10.1038/s41597-026-06710-9
Mots-clés: capteurs portables, reconnaissance d’activité humaine, unités de mesure inertielle, placement des capteurs, intensité de l’activité physique