Clear Sky Science · fr
Un jeu de données chinois pour la reconnaissance d’entités nommées appliquée au patrimoine culturel immatériel
Pourquoi la protection des traditions vivantes exige une lecture intelligente
Partout dans le monde, des traditions vivantes comme la musique populaire, l’artisanat et les fêtes locales risquent de disparaître de la vie quotidienne. En Chine, d’importantes quantités de textes décrivent déjà ces pratiques, mais la plupart se trouvent dans de longues pages web difficiles à parcourir ou à analyser pour les personnes — ou les ordinateurs. Cette étude présente un jeu de données soigneusement construit en chinois et un modèle d’intelligence artificielle avancé capable de repérer automatiquement des informations clés dans ces textes, comme les noms d’artisanats, des maîtres artisans, des matériaux et des lieux. Ensemble, ils offrent de nouveaux outils pour aider à préserver et étudier le patrimoine culturel immatériel à l’échelle numérique.
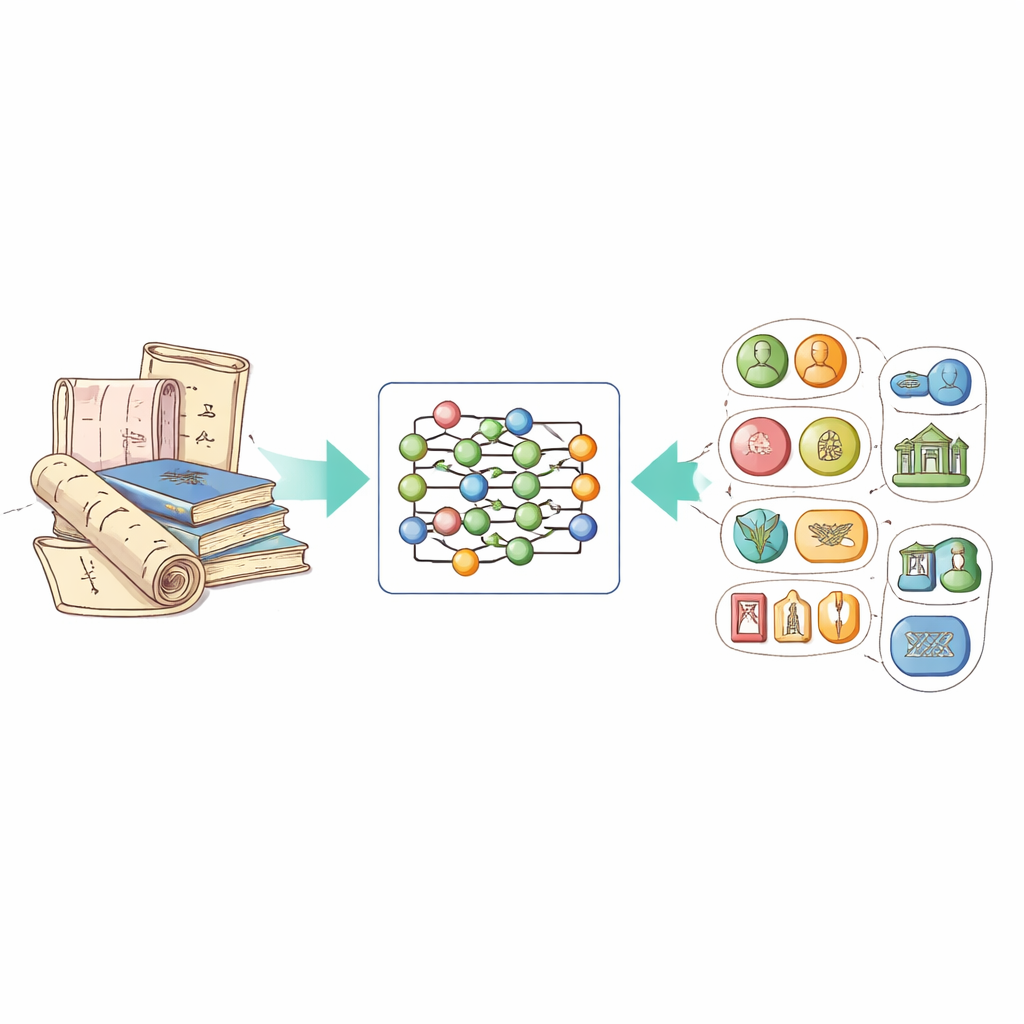
Transformer des textes désordonnés en connaissances structurées
L’idée centrale de ce travail repose sur une technique appelée reconnaissance d’entités nommées, qui apprend aux ordinateurs à mettre en évidence des éléments importants dans un texte : personnes, lieux, périodes, organisations, etc. Pour le patrimoine culturel immatériel, cela implique aussi de reconnaître des types d’entités spécifiques, comme les noms de projets patrimoniaux, des techniques artisanales particulières et les matériaux utilisés. Le problème, jusqu’à présent, est l’absence d’un jeu de données public adapté à ce domaine en chinois : les systèmes généralistes peinent face aux descriptions vivantes, au langage poétique et aux expressions régionales présentes dans les documents patrimoniaux.
Constituer une collection ciblée de textes patrimoniaux
Pour combler ce vide, les auteurs ont rassemblé un nouveau jeu de données, appelé ICH-NER, à partir du réseau officiel chinois du patrimoine culturel immatériel. Ils se sont concentrés sur des fiches liées à l’artisanat — textiles traditionnels, céramique, métallurgie, sculpture, etc. — car ces descriptions regorgent de détails sur les procédés et les matériaux. Après avoir supprimé les avis et les doublons, ils ont défini huit catégories clés d’entités : noms d’éléments du patrimoine, lieux, personnes, organisations, périodes, groupes ethniques, matériaux et savoir-faire. Chaque caractère chinois dans les textes a été étiqueté par un code simple indiquant s’il appartient à une entité et, si oui, de quel type. Au total, le jeu de données comprend 7 779 échantillons et plus de 21 000 entités labellisées, faisant de lui une référence solide pour les recherches futures.
Règles strictes pour un étiquetage cohérent
Faute de système de classification standard pour ce type de textes patrimoniaux, les chercheurs ont d’abord élaboré des directives détaillées fondées sur les listes nationales du patrimoine et les descriptions officielles. Ils ont mené une phase pilote pour traiter les cas délicats, par exemple les lieux faisant partie de noms de projets, ou les syntagmes imbriqués où une entité se trouve à l’intérieur d’une autre. Un annotateur formé a ensuite labellisé l’ensemble du jeu de données en utilisant un logiciel open source, revenant à plusieurs reprises sur les annotations antérieures pour corriger les incohérences. Les données finales ont été divisées en ensembles d’entraînement et de développement, en veillant à conserver des proportions similaires de chaque type d’entité et un bon mélange de termes régionaux et de styles d’écriture dans les deux parties.
Concevoir un modèle d’IA adapté au langage patrimonial
En parallèle du jeu de données, l’étude propose un modèle de reconnaissance spécialisé qui assemble plusieurs composants d’IA modernes. D’abord, un encodeur de langue performant (RoBERTa) convertit les caractères chinois en représentations numériques contextuelles reflétant l’usage des mots dans leur environnement. Ensuite, un module Kolmogorov–Arnold Network (KAN) apprend des motifs subtils et non linéaires — par exemple comment certains matériaux se combinent fréquemment avec des techniques ou des régions particulières. Une couche d’attention multi‑tête examine alors les relations à travers la phrase sous plusieurs angles, et enfin une couche de décodage choisit la séquence d’étiquettes d’entités la plus probable. Cette architecture est conçue pour gérer des phrases longues et complexes, pleines de métaphores et de références culturelles enchevêtrées.
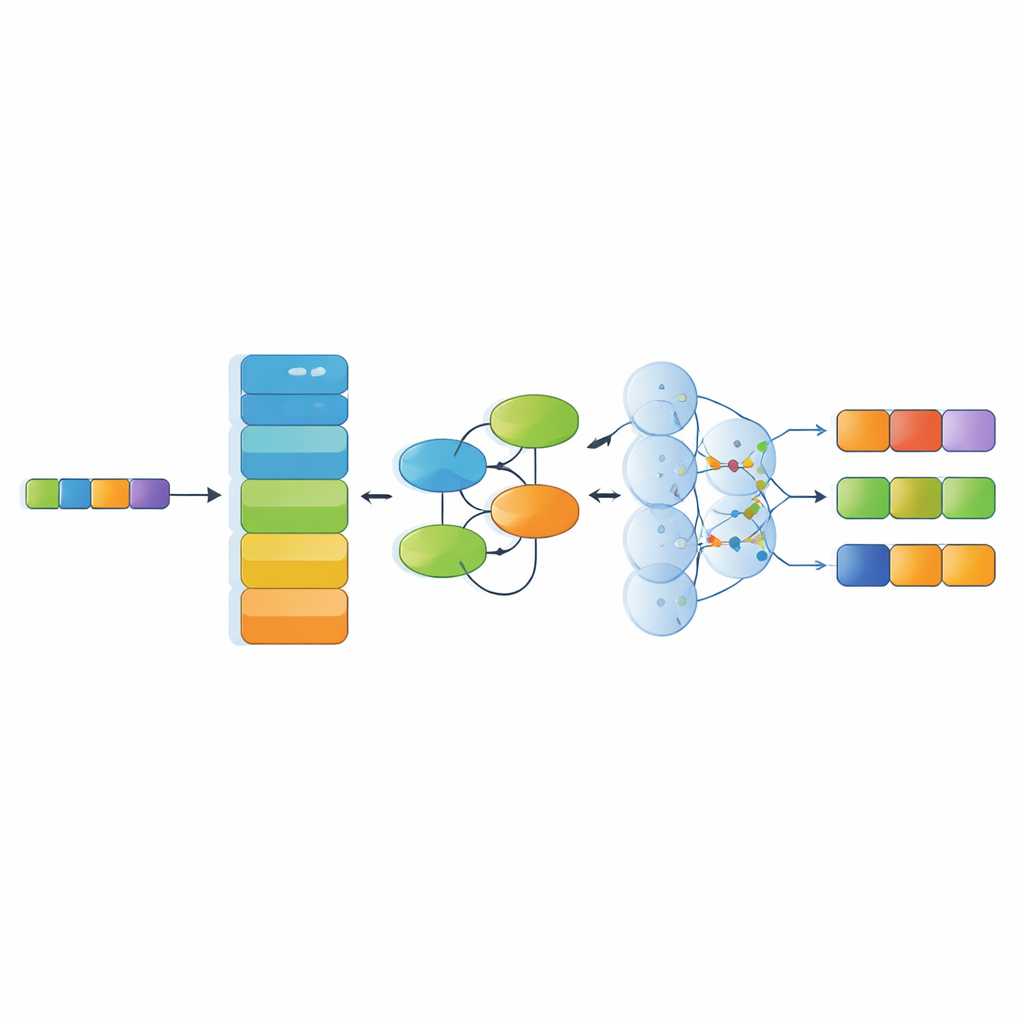
Quelle compréhension le système a des textes patrimoniaux
Les auteurs ont comparé leur modèle à plusieurs baselines solides couramment utilisées en recherche linguistique, y compris des systèmes basés sur des réseaux récurrents, des structures en treillis pour le texte chinois, et une méthode récente qui traite les entités comme des segments raffinés étape par étape. Sur le jeu de données ICH-NER, les méthodes reposant sur des modèles de langue pré‑entraînés modernes ont nettement surpassé les approches plus anciennes. Leur système combiné RoBERTa–KAN–attention–décodage a obtenu le meilleur compromis global entre précision et rappel, en particulier pour des catégories difficiles comme les matériaux, les organisations et les techniques artisanales, où les données sont relativement rares et les descriptions souvent complexes ou ambiguës.
Ce que cela signifie pour la culture vivante à l’ère numérique
Concrètement, le nouveau jeu de données et le modèle facilitent l’extraction par les ordinateurs du qui, quoi, où et quand dans les descriptions détaillées des métiers traditionnels. Ces informations structurées peuvent alimenter des graphes de connaissances, des cartes interactives ou des outils de recherche qui aident chercheurs, conservateurs et grand public à explorer la diffusion des techniques, l’influence de certaines familles ou régions sur un métier, et l’évolution des pratiques dans le temps. Bien que le travail soit technique, son impact est humain : il propose une manière de transformer des descriptions éparses et figées dans le texte en connaissances organisées qui soutiennent mieux la préservation et la compréhension du patrimoine culturel immatériel.
Citation: Long, S., Li, W. A Chinese Named Entity Recognition Dataset for Intangible Cultural Heritage. Sci Data 13, 335 (2026). https://doi.org/10.1038/s41597-026-06700-x
Mots-clés: patrimoine culturel immatériel, reconnaissance d’entités nommées, traitement du chinois, jeux de données culturels, préservation numérique