Clear Sky Science · fr
Séquençage du génome, assemblage de novo et annotation du bambou d’intérêt commercial, Bambusa tulda Roxb
Une herbe à croissance rapide au potentiel considérable
Le bambou peut sembler une simple plante de jardin, mais c’est en réalité une ressource naturelle puissante pour la construction, le papier et même de futurs biocarburants. Une espèce largement utilisée, Bambusa tulda ou bambou du Bengale, pousse rapidement, accumule d’importantes quantités de matière ligneuse et ne fleurit que rarement. Jusqu’à présent, les scientifiques ne disposaient pas d’un « manuel d’instructions » complet pour cette espèce. Cet article décrit comment des chercheurs ont décodé et organisé la séquence complète de l’ADN de B. tulda, créant une ressource de base qui aidera à améliorer le bambou pour l’industrie, la conservation et les technologies favorables au climat.
Pourquoi décoder l’ADN d’un bambou ?
Bambusa tulda est commune sur le sous-continent indien et dans certaines régions d’Asie du Sud-Est, où ses chaumes robustes (tiges) sont utilisées dans la construction rurale, le mobilier et l’artisanat. Elle suscite également de l’intérêt comme source de pâte à papier et d’énergie renouvelable. Pourtant, B. tulda présente des comportements intrigants : elle peut croître très vite, accumuler beaucoup de matière ligneuse résistante, puis attendre environ 50 ans avant de fleurir, parfois avec tous les individus d’une zone qui fleurissent simultanément. Sans séquence génomique complète, les scientifiques ne pouvaient que supposer quels gènes contrôlaient ces traits. En lisant et en assemblant son ADN, les auteurs ont voulu construire une carte de référence que les chercheurs futurs pourront utiliser pour étudier la croissance, la floraison, la résistance aux maladies, et plus encore.
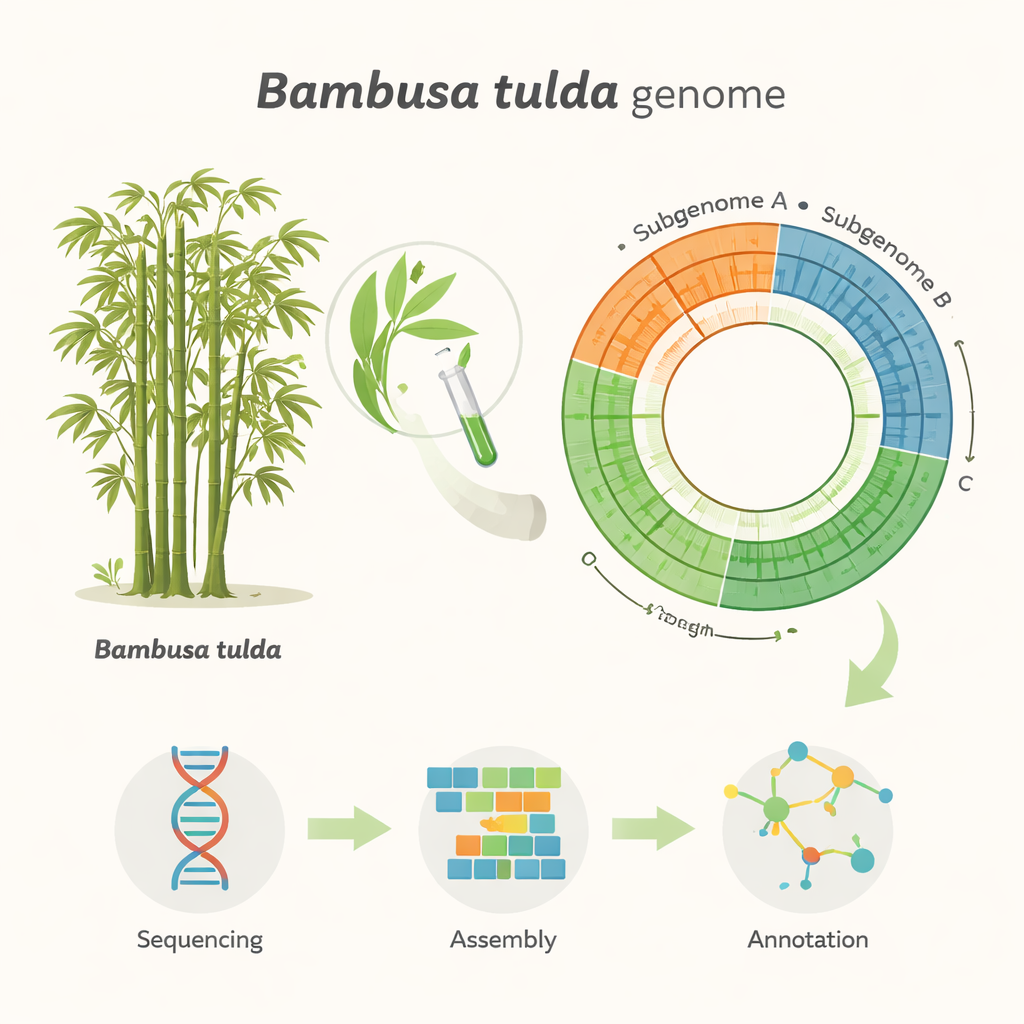
Mesurer et lire un génome géant
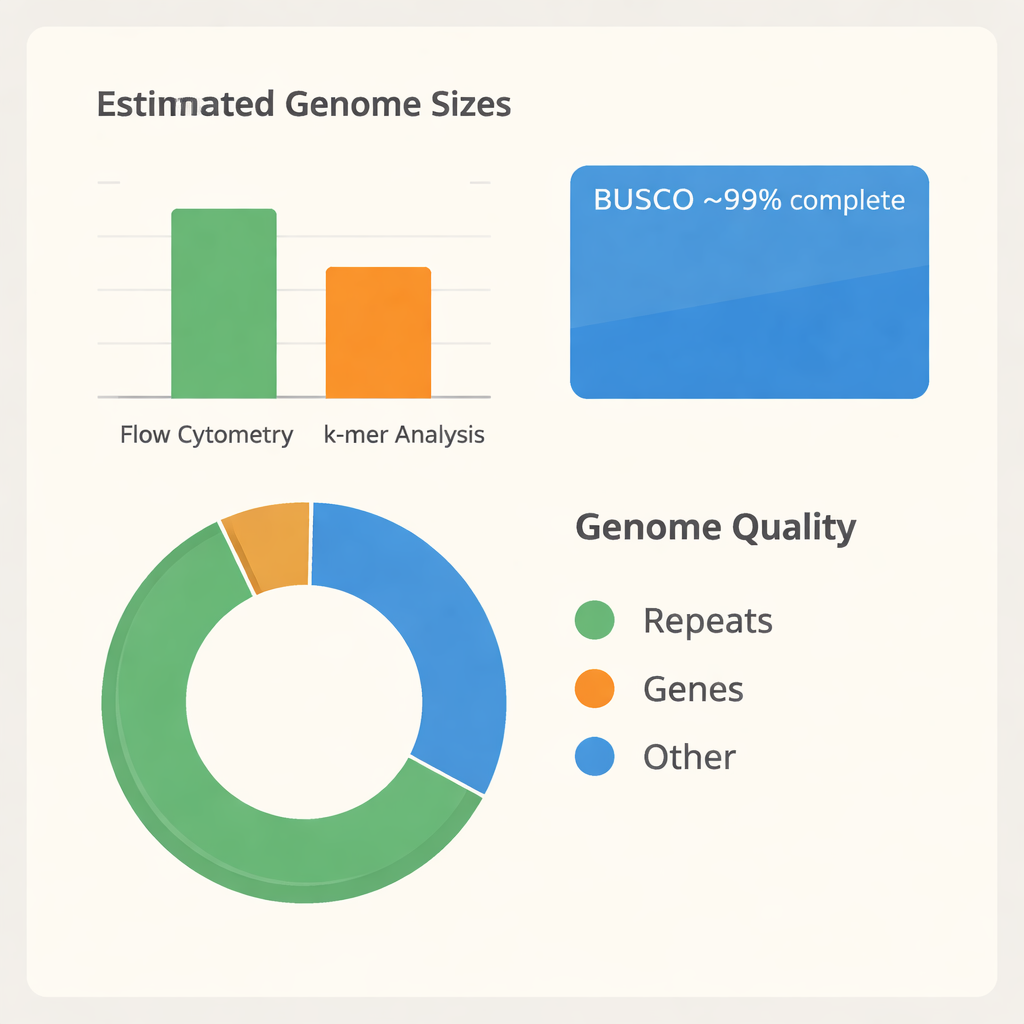
L’équipe a d’abord dû comprendre quelle est la taille du génome de B. tulda. À l’aide d’une technique appelée cytométrie en flux, ils ont comparé la teneur en ADN des cellules foliaires de B. tulda à celle de la tomate et du maïs, deux plantes dont la taille du génome est déjà connue. Cela a suggéré une taille du génome diploïde d’environ 3 milliards de « lettres » d’ADN. Ils ont ensuite utilisé une seconde approche indépendante basée sur le recoupement des courts fragments d’ADN (analyse des k-mers), qui a estimé une taille légèrement inférieure d’environ 2,34 milliards de lettres et révélé qu’une grande partie du génome est répétitive et probablement dupliquée. Avec ces mesures en main, ils ont extrait de l’ADN très long et de haute qualité à partir de jeunes feuilles et l’ont séquencé avec la technologie PacBio HiFi avancée, générant plus de 116 milliards de bases de données brutes — suffisamment pour lire le génome des dizaines de fois.
Assembler le plan du bambou
Transformer des millions de lectures d’ADN en un génome ordonné revient à assembler un immense puzzle sans l’image sur la boîte. Les chercheurs ont utilisé des logiciels spécialisés pour construire à la fois une assemblée primaire combinée et deux haplotypes séparés, reflétant les deux copies parentales du génome. Après avoir retiré les pièces dupliquées et celles dérivées des organites, ils sont parvenus à une assemblée « haploïde » simplifiée de 43 grands segments, couvrant environ 1,37 milliard de bases. Ces segments se répartissent en trois sous-génomes, étiquetés A, B et C, en accord avec l’origine complexe et polyploïde de B. tulda. Un test de qualité largement utilisé, appelé BUSCO, a montré qu’environ 99 % des gènes végétaux attendus sont présents et intacts, indiquant que l’assemblage est à la fois complet et fiable pour les études ultérieures.
Gènes, répétitions et indices évolutifs
Une fois le génome assemblé, l’étape suivante a été d’identifier ses parties fonctionnelles. En combinant trois sources de preuves — prédictions à partir de la séquence d’ADN elle‑même, similarité avec des gènes d’autres bambous et données d’ARN issus de gènes activement exprimés — l’équipe a annoté 56 890 gènes codant des protéines, qui occupent environ un cinquième du génome. Ils ont également recensé un grand nombre d’ARN non codants, y compris plus d’un millier de gènes d’ARN de transfert et d’ARN ribosomique soutenant la production protéique. De façon remarquable, environ les deux tiers du génome sont constitués d’éléments répétitifs, en particulier des segments d’ADN mobiles qui se copient et se déplacent. Ces répétitions expliquent en partie pourquoi les estimations de taille antérieures différaient et témoignent d’une histoire évolutive dynamique. La comparaison des familles de protéines entre douze autres espèces de bambou, ainsi qu’avec le maïs et la banane comme proches apparentés, classe clairement B. tulda parmi les bambous ligneux paléotropicaux à origine hexaploïde, confirmant que son génome est constitué de multiples copies ancestrales.
Une nouvelle base pour la recherche future sur le bambou
Pour les non-spécialistes, le résultat clé est que B. tulda dispose désormais d’un génome de référence de haute qualité — un plan indexé et consultable de son ADN. Cette ressource permettra aux scientifiques d’identifier précisément les gènes qui contrôlent la croissance rapide, la lignification et la floraison retardée, et de les comparer avec ceux d’autres graminées. Elle soutiendra aussi les efforts de sélection ou d’ingénierie de variétés de bambou mieux adaptées à la construction, à la production de papier ou à l’énergie, tout en préservant les populations naturelles. En bref, en cartographiant le paysage génétique de ce bambou d’importance commerciale, l’étude jette les bases d’une utilisation plus intelligente d’une des plantes les plus polyvalentes au monde.
Citation: Kundu, S., Rupp, O., Dey, S. et al. Genome sequencing, de novo assembly and annotation of the commercially important bamboo, Bambusa tulda Roxb. Sci Data 13, 175 (2026). https://doi.org/10.1038/s41597-026-06679-5
Mots-clés: génome de bambou, Bambusa tulda, génétique végétale, graminées ligneuses, biomatériaux renouvelables