Clear Sky Science · fr
Jeu de données histologiques à grande échelle avec métadonnées pour le microenvironnement du cancer colorectal
Pourquoi il est important de cartographier le voisinage caché du cancer
Lorsque les médecins observent une tumeur du côlon au microscope, ils ne voient pas seulement des cellules cancéreuses ; ils voient un quartier animé composé de tissu adipeux, de cellules immunitaires, de tissu conjonctif et d’autres éléments. Ce mélange de types cellulaires, appelé microenvironnement tumoral, influence fortement la réponse d’un patient au traitement et sa durée de vie. Pourtant, les ordinateurs susceptibles d’aider les médecins à interpréter ces scènes complexes ont été limités par un problème simple : ils n’avaient pas suffisamment d’images bien annotées pour apprendre. Cette étude présente l’une des collections d’images de tissus colorectaux les plus vastes et les mieux annotées jamais assemblées, conçue spécifiquement pour entraîner et évaluer les systèmes d’intelligence artificielle modernes.
Construire une vaste bibliothèque d’images de tumeurs du côlon
Les chercheurs ont créé une ressource qu’ils appellent HMU-CRC-Hist550K, issue d’échantillons tissulaires de 500 patients pris en charge pour un cancer colorectal dans un grand hôpital oncologique en Chine. La tumeur de chaque patient a été conservée, colorée selon les pratiques standard des laboratoires de pathologie, puis numérisée en une lame numérique haute résolution. À partir de ces lames, l’équipe a découpé automatiquement de petits carreaux d’image carrés, chacun d’une taille comparable à ce qu’un pathologiste peut voir au microscope en une seule fois. Au total, ils ont produit environ 550 000 de ces carreaux, offrant aux modèles d’intelligence artificielle un jeu d’exemples vaste et varié pour apprendre à reconnaître les différents tissus.
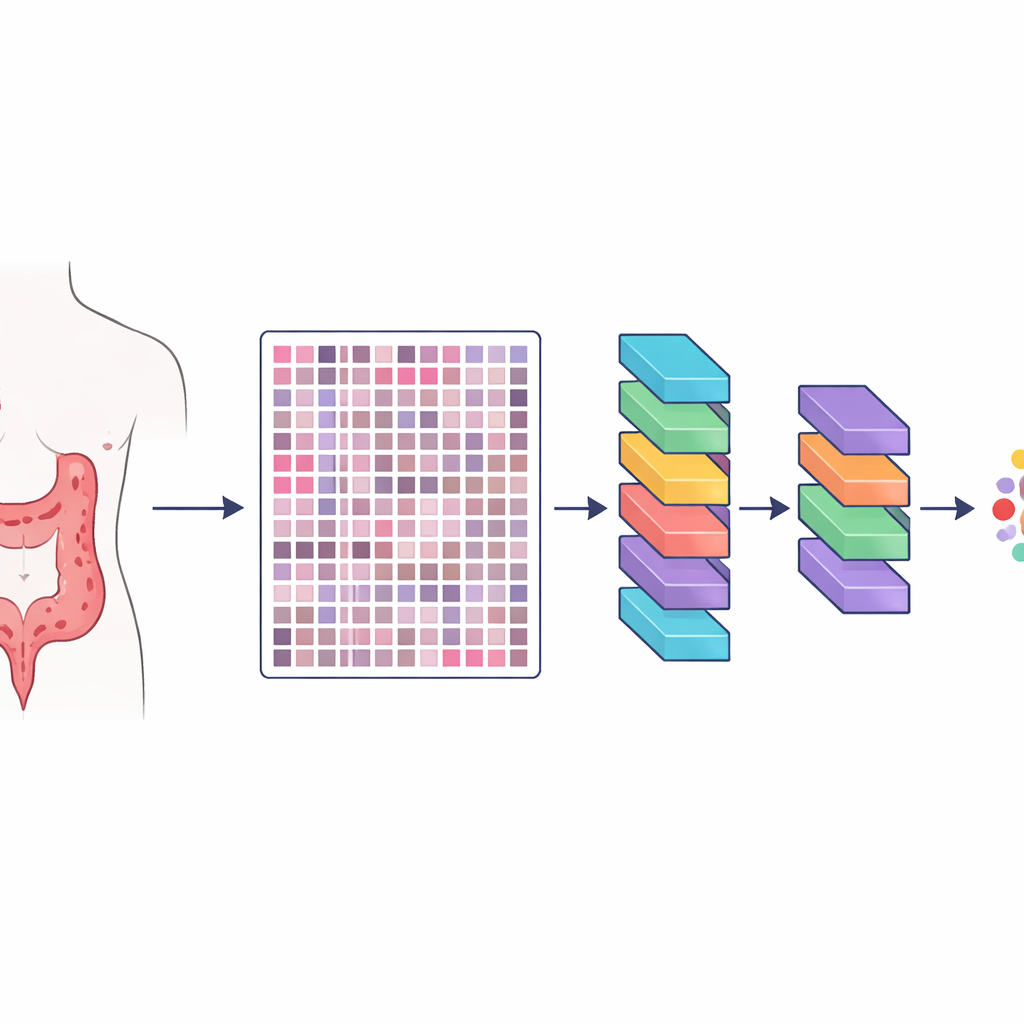
Annotations humaines soignées du paysage tumoral
Créer une grande bibliothèque d’images ne suffit pas ; les images doivent aussi être annotées avec précision. Trois pathologistes expérimentés ont travaillé ensemble via un processus en trois étapes pour délimiter huit composants clés de l’environnement tumoral : tissu adipeux, débris cellulaires, cellules immunitaires appelées lymphocytes, mucus, muscle lisse, muqueuse colique normale, tissu conjonctif de soutien autour de la tumeur, et les cellules cancéreuses elles‑mêmes. Deux pathologistes ont d’abord dessiné des régions sur les grandes lames de manière indépendante, puis ont vérifié le travail de l’autre. Un spécialiste senior a effectué une révision finale, résolvant les désaccords et excluant les zones peu claires. Cette vérification croisée a réduit considérablement les biais personnels et produit des annotations très cohérentes à un niveau de détail fin, de sorte que chaque carreau est associé à un type tissulaire précis au sein du voisinage tumoral.
Relier les vues microscopiques aux histoires des patients
Ce qui rend ce jeu de données particulièrement puissant, c’est que les images sont associées à des informations cliniques riches pour chaque patient. Pour chaque cas, l’équipe a collecté des détails de base tels que l’âge et le sexe, ainsi que le stade de la tumeur, sa localisation le long du côlon et du rectum, le degré d’anomalie des cellules cancéreuses, l’invasion des nerfs ou des ganglions lymphatiques et la durée de survie après traitement. Ils ont également enregistré les résultats des tests de laboratoire courants reflétant le profil génétique et protéique de la tumeur. Toutes les informations personnelles identifiantes ont été supprimées afin que les patients ne puissent pas être reconnus. En combinant les motifs tissulaires avec ces caractéristiques cliniques, les chercheurs peuvent explorer comment des configurations spécifiques du microenvironnement se rapportent à des résultats concrets, par exemple quels patients s’en sortent mieux ou moins bien.
Mettre l’IA à l’épreuve sur le nouveau jeu de données
Pour montrer l’utilité réelle du jeu de données, les scientifiques ont entraîné trois modèles d’apprentissage profond différents — des systèmes modernes de reconnaissance de motifs performants sur les tâches d’imagerie — pour identifier les huit types tissulaires dans les carreaux. Ils ont appliqué des règles strictes pour répartir les patients entre les ensembles d’entraînement et de test afin que les modèles soient évalués sur des patients qu’ils n’avaient jamais vus auparavant. Les modèles, comprenant à la fois des réseaux classiques pour images et un modèle plus récent de type « vision transformer », ont tous atteint une très grande précision, avec des scores de performance proches de la perfection sur plusieurs jeux de test. L’équipe a aussi comparé les résultats à d’autres méthodes avancées de segmentation d’image et a observé des performances tout aussi élevées. Des outils visuels ont été utilisés pour mettre en évidence les parties du tissu sur lesquelles les modèles se sont appuyés, confirmant qu’ils se concentraient sur des zones médicalement pertinentes plutôt que sur des motifs aléatoires.
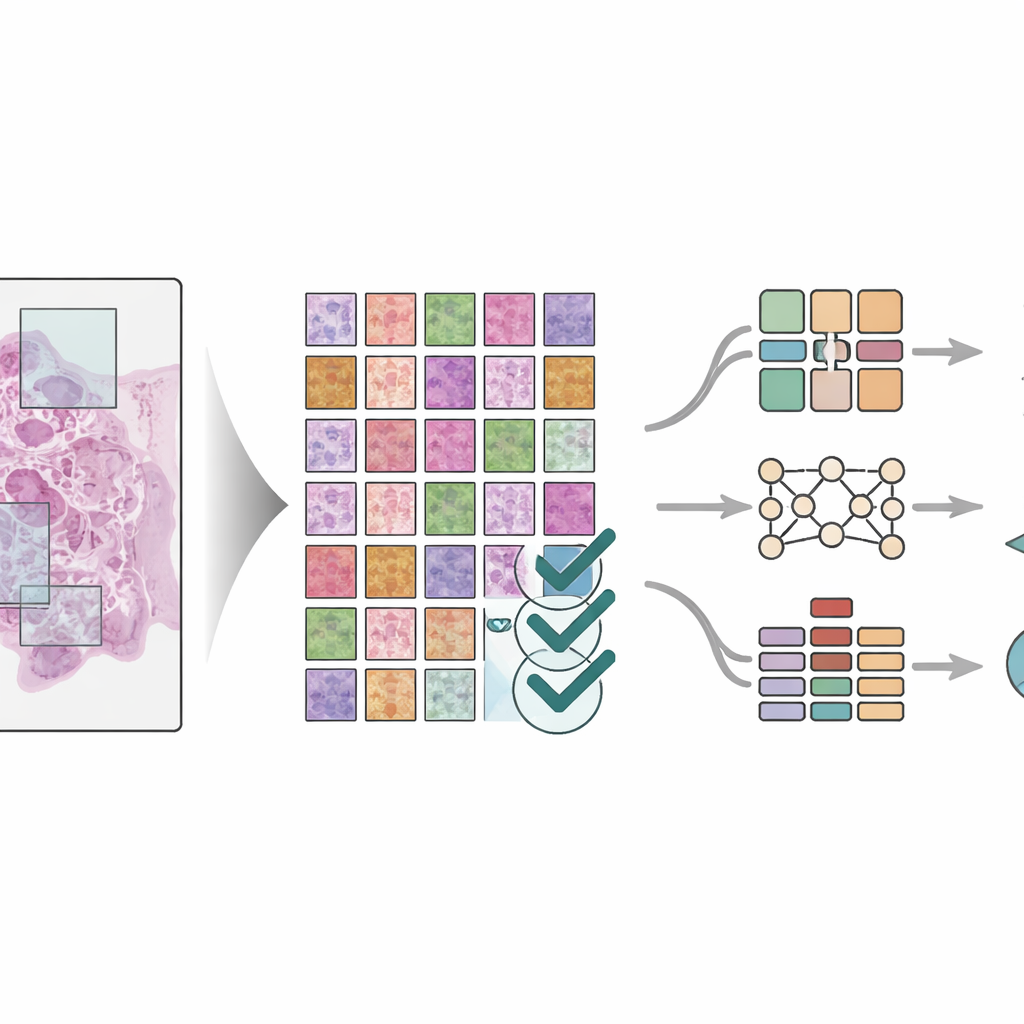
Ce que cela signifie pour les soins du cancer à venir
Pour les non‑spécialistes, le message principal est que ce travail n’introduit pas un nouveau traitement, mais plutôt une base solide pour des diagnostics et des pronostics plus intelligents. En partageant une grande bibliothèque d’images bien organisée et accessible, liée à des dossiers patients détaillés, les auteurs permettent aux chercheurs du monde entier de développer et de comparer des outils d’intelligence artificielle sur une base commune et fiable. De tels outils pourraient, à terme, aider les pathologistes à cartographier plus rapidement et plus uniformément le voisinage tumoral, à prédire quels patients présentent un risque plus élevé et à suggérer des stratégies de traitement plus personnalisées. Bien que les données actuelles ne capturent que des points temporels uniques plutôt que des évolutions sur plusieurs mois ou années, cette ressource constitue une étape importante vers l’utilisation de la pathologie numérique et de l’IA pour mieux comprendre, et ultimement mieux traiter, le cancer colorectal.
Citation: Wang, H., Li, H., Xue, J. et al. Large-Scale Histological Image Dataset with Metadata for Colorectal Cancer Microenvironment. Sci Data 13, 431 (2026). https://doi.org/10.1038/s41597-026-06675-9
Mots-clés: cancer colorectal, microenvironnement tumoral, pathologie numérique, apprentissage profond, jeu de données d’imagerie médicale