Clear Sky Science · fr
Manifeste des données biomédicales : une documentation légère pour améliorer la transparence en IA/ML
Pourquoi des notes de données plus intelligentes comptent pour votre santé
Alors que hôpitaux et chercheurs s’empressent d’utiliser l’intelligence artificielle pour prédire les maladies et guider les traitements, la qualité des données alimentant ces outils façonne discrètement qui en profite — et qui risque d’être laissé pour compte. Cet article présente une méthode pratique pour « étiqueter la boîte » des jeux de données biomédicaux, afin que toute personne construisant des systèmes d’IA puisse rapidement voir d’où viennent les données, qui elles représentent et comment elles doivent — ou ne doivent pas — être utilisées. En rationalisant ce type de documentation, les auteurs visent à rendre l’IA médicale plus équitable, plus sûre et plus digne de confiance.
Les histoires cachées au sein des données médicales
La plupart des grands jeux de données biomédicaux — collections de résultats de laboratoire, d’imageries ou de résultats de traitement — n’ont pas été créés en pensant à l’IA. Ils manquent souvent d’enregistrements clairs sur la manière dont les données ont été collectées, sur les patients inclus ou sur les modifications intervenues au fil du temps. Ces détails manquants peuvent cacher des biais, comme la sous-représentation de certains groupes ou l’enregistrement incohérent d’informations clés. Quand de telles données servent à entraîner des systèmes d’apprentissage automatique, les outils résultants peuvent bien fonctionner pour certains patients mais mal pour d’autres, renforçant des inégalités de soins existantes. Les auteurs soutiennent qu’une documentation standardisée et de meilleure qualité est essentielle pour dévoiler et gérer ces risques avant le déploiement des algorithmes.
Combiner les meilleures idées en un guide simple
Plusieurs approches de « fiche technique » de données existent déjà dans la communauté IA, comme les Datasheets for Datasets, les Data Cards et les HealthSheets. Chacune propose des questions structurées sur l’objectif d’un jeu de données, son contenu, ses méthodes de collecte et ses limites. Toutefois, elles ont été principalement conçues par des informaticiens pour des jeux de données orientés IA, et peuvent être longues et difficiles à remplir pour des chercheurs biomédicaux pressés. Pour éviter de réinventer la roue, l’équipe a d’abord cartographié et harmonisé les champs de quatre modèles largement cités, en constituant une liste consolidée de 136 questions qui capturait les concepts les plus importants tout en supprimant les redondances. Ils ont ensuite affiné cette liste à 100 champs regroupés en sept catégories intuitives, allant des informations de base et de l’usage des données à des éléments tels que l’éthique, les contraintes juridiques et la manière dont les étiquettes ont été créées.
Écouter les personnes qui utilisent et produisent les données
Ensuite, les chercheurs ont demandé à des parties prenantes biomédicales du monde réel — comprenant des cliniciens, des biologistes de laboratoire, des gestionnaires de données et des experts computationnels — d’évaluer l’importance de chaque champ de documentation pour leur travail. Vingt-trois participants issus d’un réseau de recherche oncologique multi-centres ont complété l’enquête. L’équipe a regroupé les répondants en deux « personas » larges : ceux proches de la collecte de données au laboratoire ou au chevet, et ceux qui gèrent, organisent ou analysent principalement les données. Cela a révélé des différences de priorités nettes. Par exemple, les deux groupes ont fortement valorisé la connaissance de la dernière mise à jour d’un jeu de données et de la fréquence potentielle des changements futurs. Mais seuls les gestionnaires de données et les experts computationnels ont priorisé de manière marquée des détails sur l’attribution des étiquettes ou la forme des mises à jour futures, tandis que cliniciens et scientifiques de laboratoire insistaient davantage sur les usages prévus et inappropriés des données.
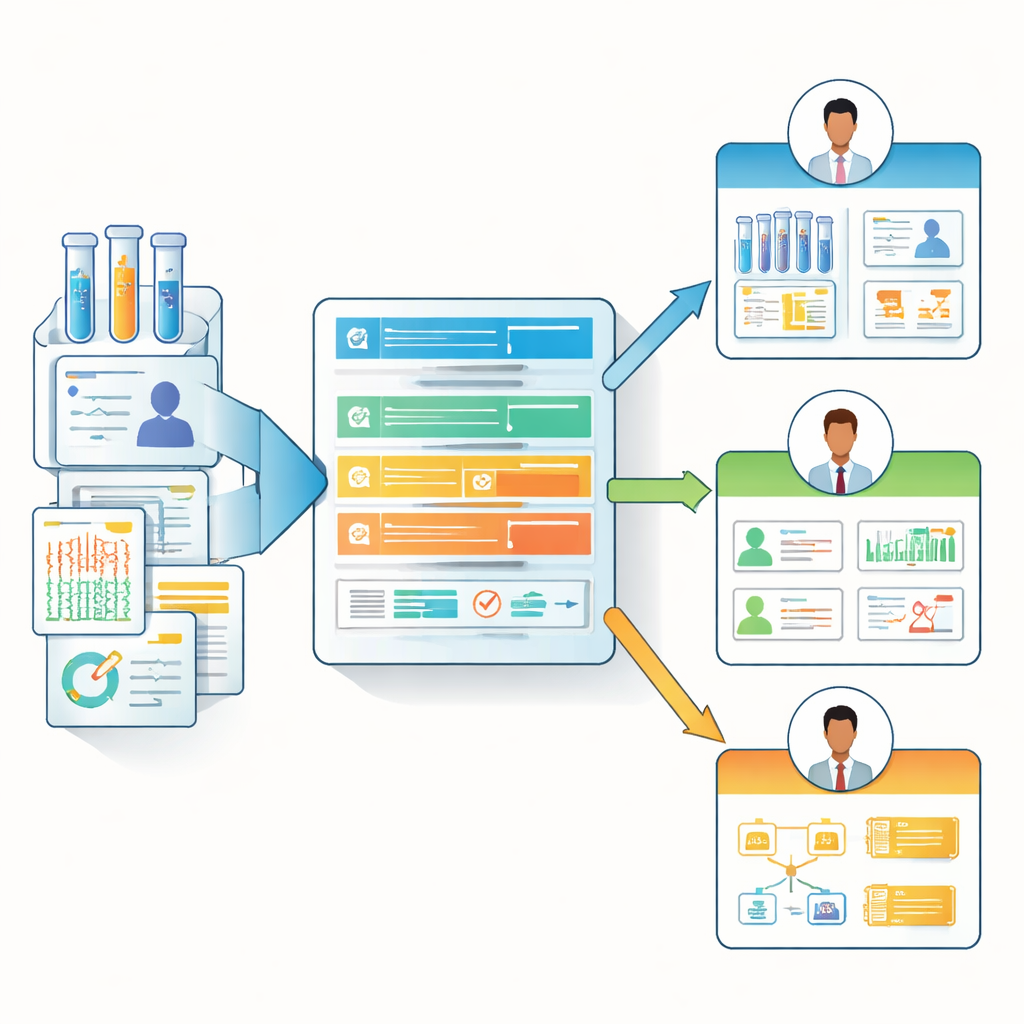
D’un modèle unique à des notes de données adaptées aux rôles
Sur la base de ces enseignements, les auteurs ont conçu le « Biomedical Data Manifest », un modèle de documentation léger et web qui s’adapte aux différents rôles. Plutôt que d’obliger chaque contributeur à remplir une longue check-list, le manifeste utilise une hiérarchie de questions de base et d’options plus détaillées. Il peut mettre en évidence les champs les plus pertinents pour chaque persona — par exemple en affichant la lignée des données et les détails de mise à jour pour les analystes, tout en soulignant le contexte clinique et les contraintes pour les chercheurs et cliniciens de première ligne. L’équipe fournit un formulaire prêt à l’emploi (par exemple, dans Microsoft Forms), un modèle d’affichage HTML et un package R open source appelé BioDataManifest. Ce logiciel peut transformer automatiquement les réponses du sondage en pages de manifeste claires et même extraire des informations depuis des dépôts publics majeurs comme le Genomic Data Commons et dbGaP pour créer des manifestes partiels pour des jeux de données existants.
Ce que cela signifie pour l’IA médicale de demain
En fin de compte, le Biomedical Data Manifest est un outil pragmatique pour faciliter la création, le partage et la compréhension des « petites lignes » des jeux de données biomédicaux. En séparant la documentation des données de celle des modèles d’IA spécifiques, et en adaptant l’affichage aux différents rôles d’utilisateur, le cadre réduit la charge pour les chercheurs tout en donnant aux utilisateurs en aval le contexte nécessaire pour juger si un jeu de données convient à un usage donné. Concrètement, il transforme des jeux de données médicaux opaques en paquets clairement étiquetés, aidant les développeurs d’IA à repérer limitations et biais potentiels avant qu’ils n’affectent les patients. Si ce type de documentation réutilisable et sensible aux rôles est largement adopté, il pourrait rendre l’IA biomédicale plus transparente, reproductible et équitable.
Citation: Bottomly, D., Suciu, C.G., Cordier, B. et al. Biomedical Data Manifest: A lightweight data documentation mapping to increase transparency for AI/ML. Sci Data 13, 414 (2026). https://doi.org/10.1038/s41597-026-06670-0
Mots-clés: documentation des données biomédicales, IA responsable en médecine, transparence des jeux de données, biais en apprentissage automatique, gouvernance des données