Clear Sky Science · fr
Estimation au niveau communautaire du rang centile d’éducation en Chine utilisant des mégadonnées multi-sources et l’apprentissage automatique
Pourquoi le niveau d’éducation de votre quartier compte
Le lieu où nous vivons façonne les écoles que fréquentent nos enfants, la sécurité de nos rues et même la valeur de nos logements. Pourtant en Chine, des informations élémentaires sur le niveau d’éducation des différents quartiers ont longtemps été difficiles à obtenir. Cette étude change la donne en utilisant des images satellite, des photos de rues et des algorithmes informatiques avancés pour estimer le niveau d’éducation relatif de plus de 120 000 communautés à travers le pays, offrant un nouvel angle sur les inégalités sociales et la vie urbaine.
Aller au-delà des années de scolarité
La plupart des statistiques comparent l’éducation en comptant le nombre d’années passées à l’école. Mais cela peut induire en erreur entre les générations. Un diplôme d’études secondaires plaçait autrefois une personne vers le haut de son groupe d’âge ; aujourd’hui, nombre de leurs enfants ont un diplôme universitaire. Les auteurs utilisent plutôt un « rang centile d’éducation », qui indique la position d’une personne au sein de sa cohorte de naissance, de 0 (le moins instruit) à 100 (le plus instruit). Ainsi, une personne âgée avec seulement un niveau collège et une personne plus jeune titulaire d’une licence peuvent être reconnues comme occupant un statut social comparable si toutes deux se situent, par exemple, autour du 70e centile de leur génération.
Transformer le paysage urbain en indices sociaux
Pour cartographier les rangs centiles d’éducation au niveau des communautés, l’équipe s’est appuyée sur six vagues d’une vaste enquête nationale ainsi que sur un large éventail de « mégadonnées » décrivant l’environnement bâti. Ils ont examiné les types de lieux entourant chaque quartier—commerces, écoles, hôpitaux, parcs et bureaux—la densité des bâtiments et des routes, la luminosité nocturne observée depuis les satellites et la fréquentation habituelle. À partir de millions de photos Street View, ils ont utilisé la vision par ordinateur pour mesurer les espaces verts, les trottoirs, la circulation, les signes de désordre comme les déchets ou les graffitis, et même l’apparence de richesse ou de sécurité d’une rue aux yeux d’observateurs humains. Ils ont aussi pris en compte le relief, comme l’altitude et la pente, car les zones escarpées ou isolées accusent souvent du retard de développement. 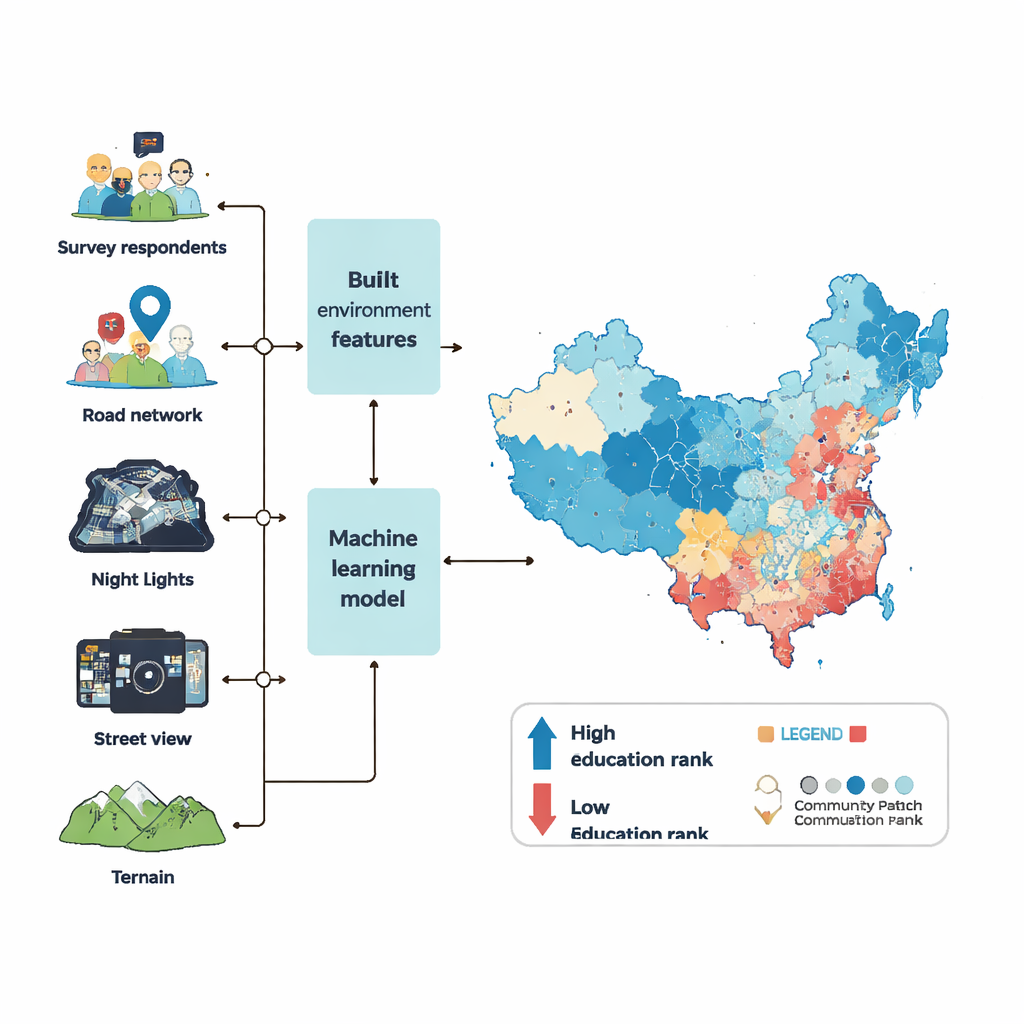
Apprendre aux machines à lire la ville
Avec ces éléments, les chercheurs ont entraîné un puissant modèle d’apprentissage automatique (appelé XGBoost) pour apprendre le lien entre les caractéristiques physiques d’une communauté et le rang centile moyen d’éducation de ses résidents. Ils ont d’abord comblé les lacunes des données environnementales à l’aide d’un processus d’« imputation » statistique soigné afin que les valeurs manquantes ne biaisent pas les résultats. Puis ils ont réglé les paramètres internes du modèle au travers de centaines d’optimisations, évaluant la performance sur la capacité du modèle à prédire les rangs d’éducation pour des communautés d’enquête qu’il n’avait pas vues auparavant. Le modèle final a pu expliquer plus de 90 % des différences entre communautés dans les données de test, avec des erreurs faibles—une performance supérieure à des efforts similaires dans d’autres pays.
Ce que révèle la nouvelle carte nationale
Grâce au modèle entraîné, les auteurs ont prédit les rangs centiles moyens d’éducation pour 122 126 communautés de la Chine continentale en 2020, couvrant la majeure partie des terres urbaines et environ 85 % de la population. Les centres-villes apparaissent généralement comme les plus éduqués, suivis par des pôles secondaires puis par les banlieues lointaines, bien que chaque métropole présente son propre schéma. Le noyau historique de Pékin, par exemple, n’accueille pas les rangs les plus élevés, tandis que les zones très éduquées de Shenzhen sont réparties sur plusieurs centres. Pour vérifier la fiabilité, l’équipe a comparé ses estimations avec les données officielles du recensement et avec des traces propriétaires de services basés sur la localisation lorsque disponibles. Aux niveaux de préfecture et de comté, les zones avec des rangs centiles prédits plus élevés montrent aussi plus d’années de scolarité dans le recensement. Au niveau des quartiers à Pékin et à Canton, leur carte s’aligne étroitement avec les références des entreprises et du recensement. 
Pourquoi cela compte pour la vie quotidienne
Pour les décideurs, les urbanistes et les chercheurs, ce nouveau jeu de données ouvert offre un portrait détaillé et à jour des avantages et des désavantages éducatifs à travers les villes chinoises. Il peut servir à étudier où se forment des enclaves de classe moyenne, jusqu’où la gentrification s’est étendue, ou quels districts peuvent nécessiter de meilleures écoles, services sociaux ou transports publics. Pour le grand public, le message central est simple : en « lisant » les rues, les lumières et les bâtiments d’un quartier, les outils de données modernes peuvent approcher la position sociale de ses résidents avec une précision surprenante. Ce travail ne remplace pas les recensements traditionnels, mais il fournit un moyen rapide et peu coûteux de combler les lacunes entre eux et de mieux comprendre comment les lieux que nous construisons reflètent, et renforcent, nos divisions sociales.
Citation: Zhang, Y., Pan, Z., You, Y. et al. Community-level education percentile rank estimation in China using multi-source big data and machine learning. Sci Data 13, 304 (2026). https://doi.org/10.1038/s41597-026-06664-y
Mots-clés: inégalité éducative, Chine urbaine, mégadonnées, apprentissage automatique, quartiers