Clear Sky Science · fr
Extraction de relations et normalisation des concepts basées sur des transformers en utilisant un corpus annoté d’essais cliniques
Aider les médecins à trouver les bons patients plus rapidement
Chaque essai clinique dépend de la recherche de patients répondant à une longue liste de conditions médicales, de traitements et de contraintes temporelles. Aujourd’hui, les médecins doivent souvent parcourir manuellement les dossiers de santé électroniques et les descriptions d’essais, ce qui est lent et sujet aux erreurs. Cet article présente une grande collection de textes d’essais cliniques en espagnol, soigneusement vérifiée, et montre comment l’intelligence artificielle moderne peut transformer ce langage non structuré en données organisées, ouvrant la voie à une recherche médicale plus rapide, plus équitable et plus précise.
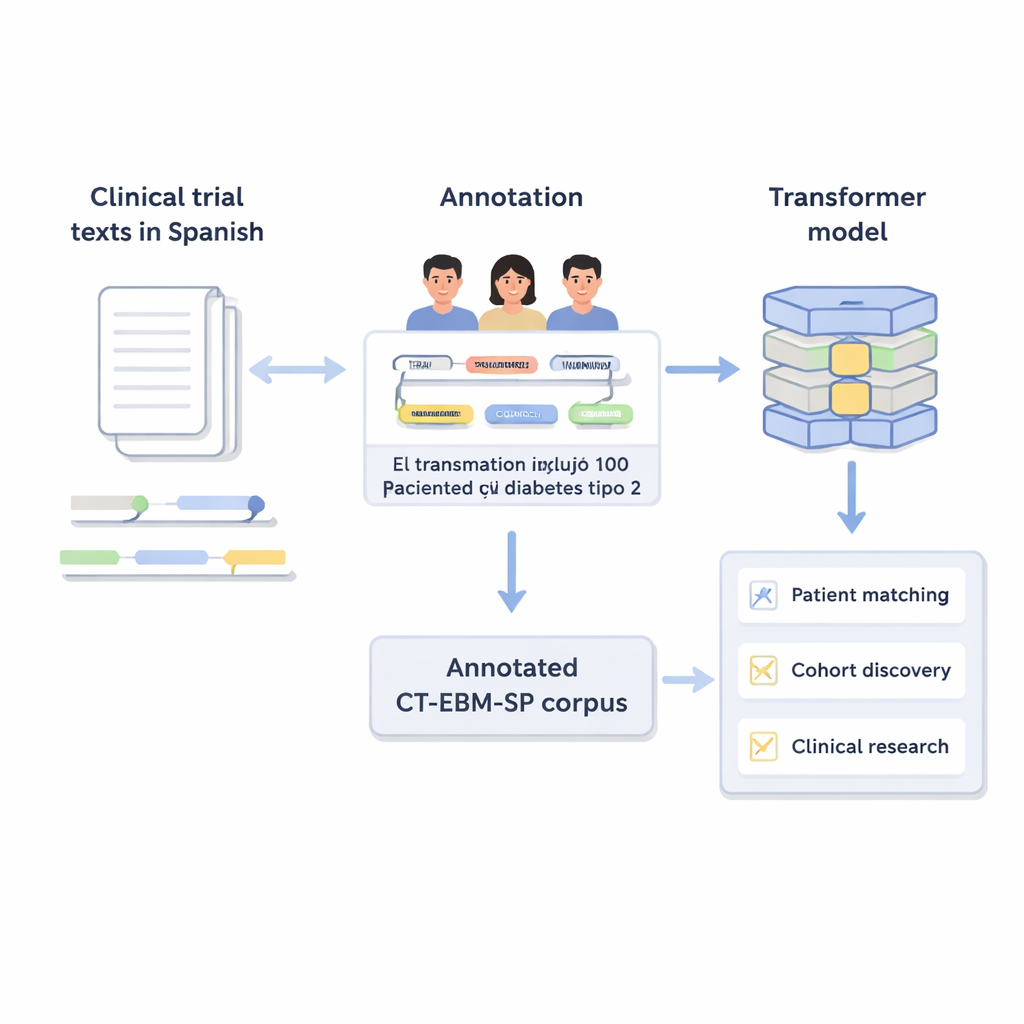
Transformer le texte libre en informations organisées
Les essais cliniques décrivent qui peut ou ne peut pas participer en utilisant un langage médical courant : limites d’âge, antécédents, résultats de laboratoire et traitements essayés. Les ordinateurs peinent à traiter ce type de texte libre. Les auteurs ont créé la version 3 du corpus CT-EBM-SP, un ensemble de données de 1 200 textes d’essais cliniques en espagnol contenant près de 300 000 mots. Des experts humains ont annoté ces textes en marquant 23 types d’entités médicales, telles que maladies, médicaments, résultats d’examens et expressions temporelles, ainsi que des indices de négation (par exemple « sans antécédent de ») et d’incertitude. Ils ont également étiqueté 11 attributs capturant des détails comme si un événement est passé ou futur et s’il concerne le patient ou un membre de sa famille.
Faire parler les termes médicaux le même langage
Un défi majeur en médecine est que le même concept peut être rédigé de nombreuses façons. Pour y remédier, l’équipe a lié la plupart des entités annotées à des codes standardisés du Unified Medical Language System (UMLS), un vaste dictionnaire médical multilingue. Cette étape, appelée normalisation des concepts, permet à différentes orthographes ou formulations de pointer vers un identifiant unique. Par exemple, plusieurs variantes de « 25-hydroxyvitamine D » sont toutes mappées sur un seul concept UMLS. Au total, le corpus comprend plus de 87 000 entités et plus de 68 000 relations, et environ 82 % des entités ont été normalisées avec succès. Deux experts ont vérifié ces liaisons indépendamment, obtenant un très fort accord, ce qui indique la fiabilité des annotations.
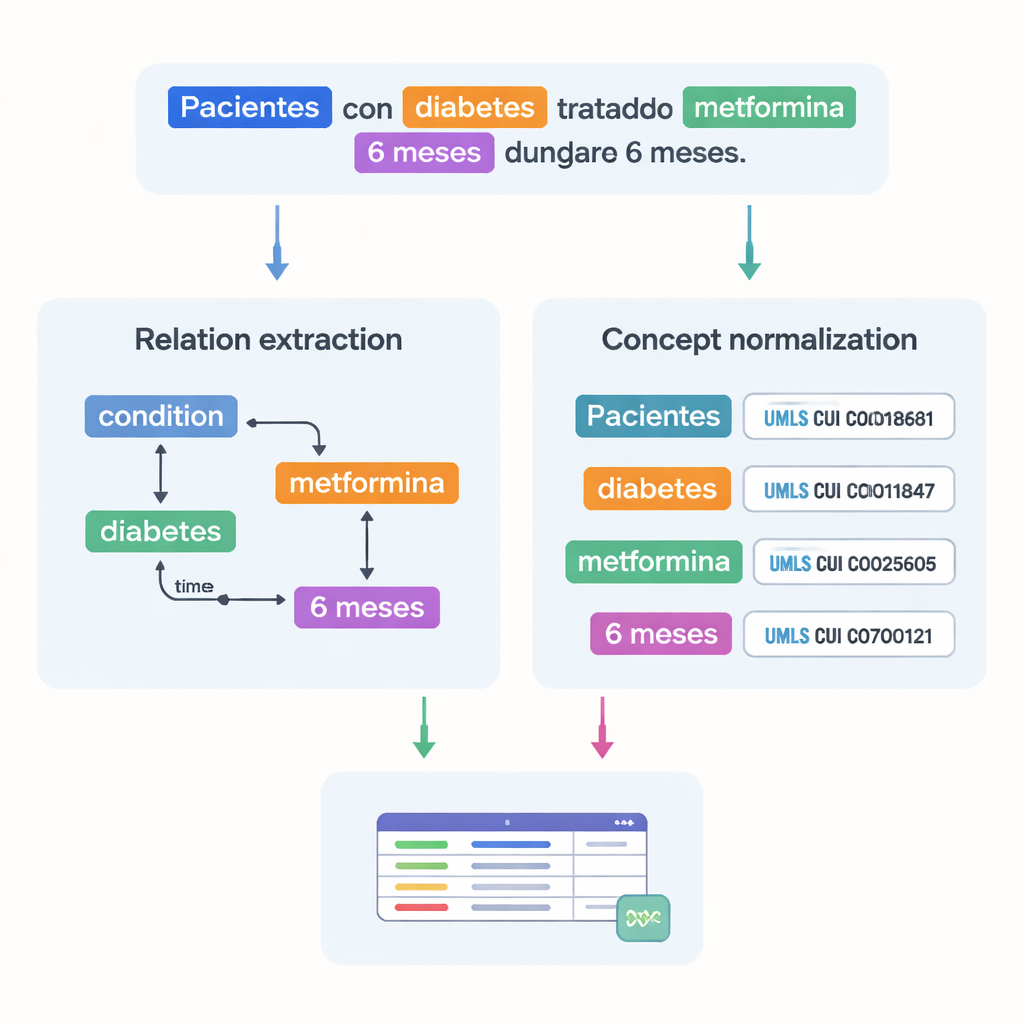
Capturer comment les faits médicaux se relient les uns aux autres
Au-delà de l’énumération de termes médicaux, l’ensemble de données enregistre leurs connexions. Les auteurs ont conçu 18 types de relations pour capturer des schémas pertinents dans les essais, comme la dose associée à un médicament, la durée d’un traitement ou la condition dont souffre un patient. Les relations temporelles indiquent si un événement se produit avant ou après un autre, et d’autres liens marquent où une maladie se situe dans le corps ou si une expression traduit une négation ou une spéculation. Ensemble, ces relations permettent aux ordinateurs de construire des graphes de la situation d’un patient — qui il est, quelle affection il présente, quel traitement il reçoit et selon quel calendrier — plutôt que de se contenter de reconnaître des mots isolés.
Entraîner et tester des modèles d’IA modernes
Pour montrer l’utilité pratique du corpus, les auteurs ont affiné plusieurs modèles d’IA basés sur des transformers, y compris des versions multilingues de BERT et RoBERTa. Ils ont entraîné ces modèles sur deux tâches : l’extraction de relations, qui apprend à retrouver les liens entre entités, et la normalisation des concepts médicaux, qui associe le texte aux codes UMLS. Pour l’extraction de relations, le meilleur modèle a atteint un score F1 proche de 0,88, ce qui signifie qu’il identifie correctement la plupart des relations avec relativement peu d’erreurs. Pour la normalisation des concepts, un modèle multilingue appelé SapBERT, utilisé sans entraînement supplémentaire, a deviné correctement le bon concept dès la première proposition dans près de 90 % des cas. Ces résultats montrent que des jeux de données de taille moyenne, bien annotés, peuvent alimenter des modèles précis et efficaces même sans systèmes linguistiques géants et généralistes.
Pourquoi cette ressource compte pour les soins futurs
Le corpus CT-EBM-SP et les modèles associés constituent une base pour des outils capables d’analyser automatiquement les textes d’essais cliniques en espagnol, de les comparer aux dossiers patients et de soutenir la découverte de cohortes dans les hôpitaux. Parce que les données sont alignées sur des standards médicaux internationaux et ont été vérifiées par des experts, elles peuvent aussi aider à développer des ressources similaires pour d’autres langues disposant de moins d’outils numériques. Concrètement, ce travail vise à faciliter et sécuriser le fait que les bons patients se voient proposer les bons essais, accélérant les découvertes médicales tout en réduisant la charge pesant sur les professionnels de santé.
Citation: Campillos-Llanos, L., Valverde-Mateos, A., Capllonch-Carrión, A. et al. Transformer-based relation extraction and concept normalization using an annotated clinical trials corpus. Sci Data 13, 280 (2026). https://doi.org/10.1038/s41597-026-06608-6
Mots-clés: essais cliniques, exploitation de textes médicaux, soins de santé en Espagne, modèles transformer, médecine fondée sur les preuves