Clear Sky Science · fr
Données de films au niveau des scènes issues d’Amazon X-Ray sur le marché américain combinées avec IMDb
Pourquoi les scènes de film importent pour comprendre la culture
Les films façonnent notre regard sur le monde, mais la plupart des recherches sur le cinéma se sont concentrées sur les recettes au box-office, les genres de base ou la notoriété des stars, plutôt que sur ce qui se déroule réellement à l’écran scène après scène. Cet article présente un nouvel ensemble de données qui permet aux chercheurs de zoomer au niveau des scènes individuelles, des personnages et des répliques pour plus de trois mille films diffusés aux États-Unis sur Amazon Prime Video. En combinant la fonctionnalité X-Ray d’Amazon avec l’Internet Movie Database (IMDb), les auteurs proposent une cartographie détaillée et standardisée de qui apparaît où et quand dans chaque film, ouvrant la voie à des études plus riches sur la représentation, la narration et même les systèmes d’intelligence artificielle qui apprennent à partir de la vidéo.
Des scripts brutaux aux scènes finalisées
Jusqu’à présent, la plupart des études à grande échelle sur les films se sont appuyées sur des scénarios ou des fichiers de sous-titres. Ces sources sont utiles mais imparfaites. Les scripts sont souvent des brouillons antérieurs qui diffèrent du montage final, et ils peuvent omettre des personnages secondaires ou des modifications apportées en postproduction. Les sous-titres captent les répliques prononcées mais ignorent les personnages silencieux, les figurants en arrière-plan et la narration purement visuelle — la caméra qui s’attarde sur le visage d’un personnage, par exemple. À cause de ces lacunes, les tentatives antérieures pour suivre qui interagit avec qui à l’écran, ou comment différents groupes sont représentés, ont dû deviner à partir du texte seul, ce qui peut conduire à des erreurs d’identification des personnages et de leurs relations.
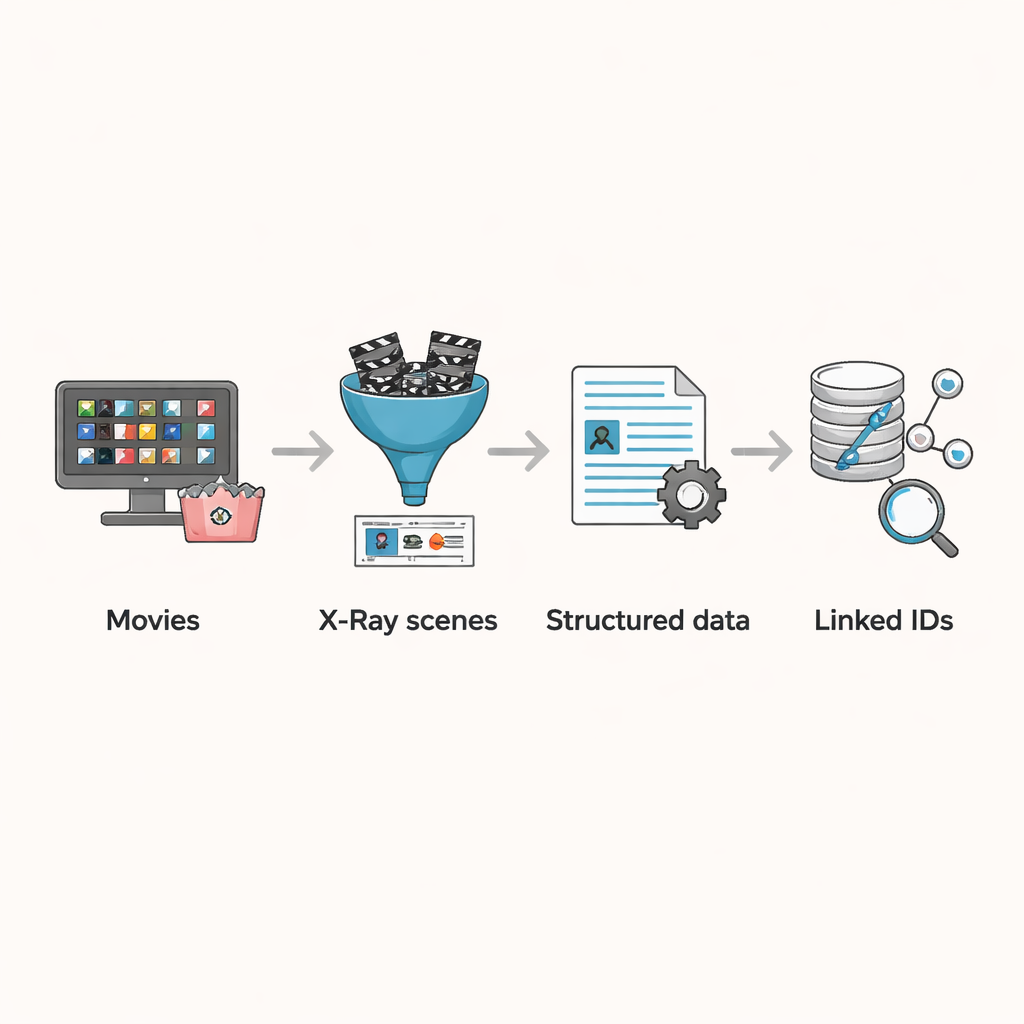
Transformer X-Ray en données prêtes pour la recherche
La fonctionnalité X-Ray d’Amazon offre une manière d’éviter ces problèmes. Lorsque les spectateurs mettent un film en pause, X-Ray montre quels acteurs et personnages sont actuellement à l’écran, une information qui est organisée et liée directement au montage final du film. Les auteurs ont construit un pipeline pour extraire ces données au niveau des scènes pour 3 265 films disponibles dans le catalogue Prime Video aux États-Unis en août 2023. Ils ont d’abord collecté toutes les entrées de films incluses avec Prime, écarté celles sans information X-Ray, et supprimé les doublons causés par des titres répétés ou des versions alternatives. Pour chaque film restant, ils ont intercepté les flux de données utilisés par le lecteur pour charger les informations X-Ray et de sous-titres, sauvegardant les résultats dans des fichiers structurés qui listent les limites des scènes, les personnages présents dans chaque scène et, pour la plupart des titres, le minutage précis de chaque segment de sous-titre.
Relier les scènes au reste de l’univers cinématographique
La véritable puissance de l’ensemble de données vient de la connexion de ces découpages de scènes à des informations externes. Si X-Ray relie déjà chaque personnage à un profil IMDb, il n’inclut pas d’identifiant IMDb pour le film lui‑même. Les auteurs ont conçu un algorithme d’appariement qui part du titre d’un film, récupère plusieurs correspondances candidates sur IMDb, puis compare la distribution principale listée sur IMDb avec les acteurs mentionnés dans les données X-Ray. Si au moins un acteur majeur se recoupe, le film est considéré comme une correspondance. Ce processus automatisé a correctement apparié la grande majorité des films, et l’équipe a ensuite vérifié manuellement les quelques centaines de cas limites restants, corrigeant les erreurs de classification et supprimant les entrées qui n’étaient pas réellement des films narratifs, comme des spectacles de stand-up. Le résultat final est un ensemble soigneusement nettoyé de films où chaque scène, personnage et sous-titre peut être lié à des métadonnées riches telles que l’année, le pays et les caractéristiques démographiques de la distribution.
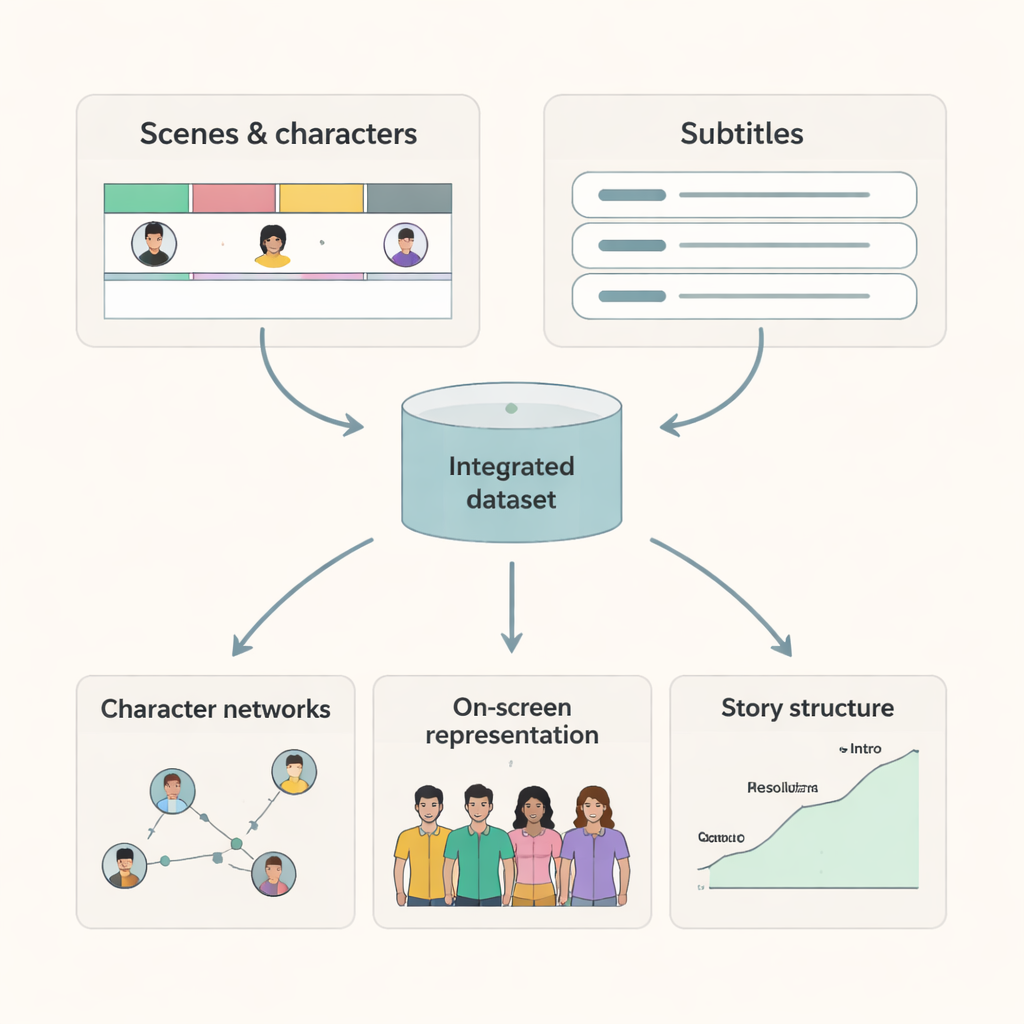
Ce que les chercheurs peuvent faire avec ces films
Parce que chaque scène a des temps de début et de fin clairs et une liste de personnes présentes, les chercheurs peuvent désormais construire des cartes précises des interactions entre personnages et du temps d’écran. Des sous-titres alignés sur les scènes rendent possible l’étude de la façon dont le langage varie selon les personnages et les contextes, ou comment certains thèmes se déploient à travers les dialogues. En combinant cet ensemble de données avec des informations supplémentaires provenant d’IMDb et d’autres sources, les universitaires peuvent examiner des questions telles que : comment l’équilibre des genres à l’écran a-t-il évolué au fil des décennies ? Les personnages de différents horizons reçoivent-ils une attention narrative égale ? Comment les schémas d’interaction diffèrent-ils selon les genres ou les pays ? L’ensemble de données offre également un référentiel de haute qualité pour les modèles d’intelligence artificielle visant à comprendre le contenu vidéo, car il fournit une vérité terrain sur qui est visible et quand.
Un nouvel angle sur les films de tous les jours
En termes simples, ce travail transforme des milliers de films en un catalogue consultable, scène par scène, de qui apparaît, qui parle et comment les histoires sont structurées. Bien que la collection soit limitée aux titres disponibles sur Prime Video aux États-Unis et dépende des processus internes X-Ray d’Amazon, elle couvre néanmoins des films de nombreuses décennies et de nombreux genres, pas seulement les grands lauréats célèbres. Cette étendue permet aux chercheurs d’étudier les films quotidiens, et pas seulement les classiques qui subsistent dans la mémoire. À mesure que l’ensemble de données est mis à jour et étendu, il promet d’approfondir notre compréhension de la façon dont les films reflètent la société — et d’offrir aux scientifiques sociaux comme aux technologues une image plus fidèle de ce qui se passe réellement à l’écran.
Citation: Shrestha, S., Heo, Y., Barron, A.T.J. et al. Scene-level movie data from Amazon X-Ray in the US market combined with IMDb. Sci Data 13, 275 (2026). https://doi.org/10.1038/s41597-026-06602-y
Mots-clés: ensembles de données de films, analyse au niveau des scènes, Amazon X-Ray, métadonnées IMDb, représentation à l’écran