Clear Sky Science · fr
Jeu de données linguistiques Kymata Soto : un ensemble électro‑magnéto‑encéphalographique pour le traitement du discours naturel
Écouter comment le cerveau perçoit de véritables conversations
La plupart de ce que nous disons et entendons au quotidien relève de la conversation informelle, pas de mots isolés ou de phrases lues soigneusement. Pourtant, une grande partie des recherches cérébrales sur le langage s’est appuyée sur des tâches artificielles. Le jeu de données linguistiques Kymata Soto change cela en fournissant une riche collection ouverte d’enregistrements cérébraux de personnes écoutant simplement des discussions radiophoniques animées en anglais et en russe, offrant aux scientifiques une nouvelle fenêtre puissante sur la manière dont nos cerveaux traitent la parole naturelle.
Une nouvelle bibliothèque de réponses cérébrales au discours réel
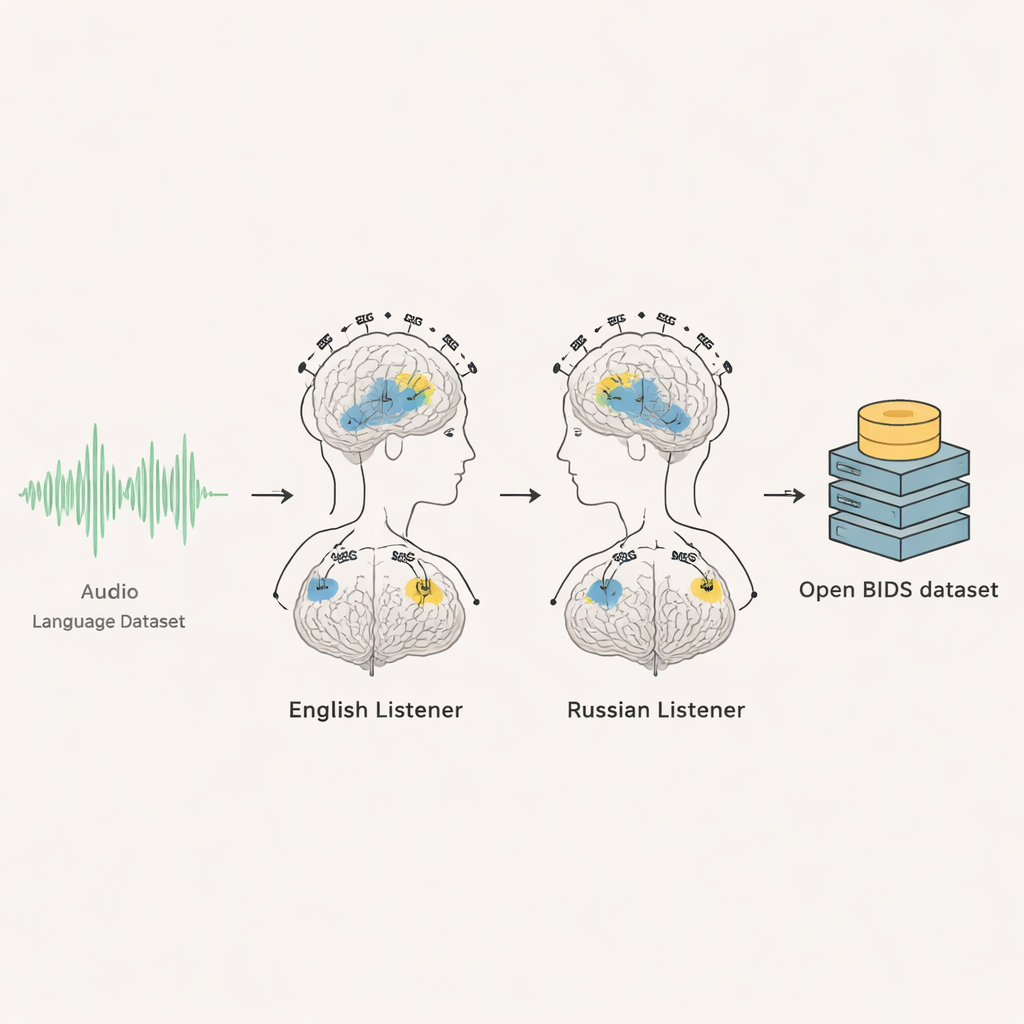
Ce projet réunit deux méthodes avancées d’enregistrement cérébral — l’électroencéphalographie (EEG) et la magnétencéphalographie (MEG) — sur 35 adultes : 20 locuteurs natifs anglais et 15 locuteurs natifs russes. Alors qu’ils restaient tranquilles et écoutaient environ six minutes et demie de conversation de style radiophonique dans leur langue, leur activité cérébrale a été enregistrée mille fois par seconde. Chaque personne a entendu le même extrait audio plusieurs fois, permettant aux chercheurs de faire la moyenne des répétitions et d’extraire les réponses cérébrales fiables du bruit de fond. Le résultat est un enregistrement détaillé et synchronisé dans le temps de la façon dont le cerveau réagit, instant après instant, au fil d’une discussion.

Des conversations sur la glace et le café
Plutôt que d’utiliser des histoires classiques ou des phrases artificielles, l’équipe a choisi des sujets engageants mais quotidiens : l’histoire de la crème glacée pour les auditeurs anglophones et l’histoire du café colombien pour les auditeurs russophones. Les deux enregistrements proviennent de discussions en studio de la BBC impliquant trois intervenants (deux hommes et une femme). Les conversations ont été montées sur environ 400 secondes et diffusées à un niveau d’écoute confortable via des écouteurs. Après chaque répétition, les participants répondaient à une ou deux questions à choix multiple simples sur le contenu — juste assez pour s’assurer qu’ils restaient attentifs et suivaient l’histoire, sans les tester de manière contraignante.
Occuper les yeux tout en focalisant l’attention sur le son
Pendant que les participants écoutaient, ils fixaient une croix centrale à l’écran. Autour de celle‑ci, des nuées de points colorés dérivaient et changeaient de façon apparemment aléatoire. Ces points mobiles avaient deux fonctions : aider à maintenir la fixation du regard, ce qui améliore la qualité des données, et créer des motifs visuels contrôlés de mouvement et de couleur que d’autres chercheurs pourront analyser ultérieurement. Il est important de noter que les points n’étaient pas synchronisés avec le contenu de la parole, ils n’« illustraient » donc pas l’histoire ni n’ajoutaient de sens, mais ils fournissaient un arrière‑plan visuel constant pouvant être étudié parallèlement aux sons.
Des signaux cérébraux bruts à des données prêtes à l’emploi
Les chercheurs ont documenté avec soin chaque partie de l’expérience et organisé le jeu de données selon une norme internationale pour les données cérébrales appelée BIDS. Pour chaque volontaire, il existe des enregistrements EEG et MEG bruts, des marqueurs temporels indiquant le début de l’audio, des événements visuels seconde par seconde, et des segments d’entraînement. L’équipe fournit également les fichiers audio originaux, des transcriptions complètes, et le minutage précis indiquant quand chaque mot et même chaque son de la parole a commencé. Ils incluent des scripts permettant à d’autres de reproduire automatiquement les extraits audio exacts utilisés. Pour le groupe anglophone, des IRM cérébrales anonymisées sont partagées afin que les réponses cérébrales puissent être cartographiées sur l’anatomie individuelle ; pour le groupe russophone, le consentement n’a pas permis le partage des images IRM, aussi les utilisateurs sont‑ils invités à se baser sur des modèles cérébraux moyens standard.
Vérifier que les signaux ont du sens
Pour s’assurer que les données sont scientifiquement fiables, les auteurs ont réalisé des analyses de validation centrées sur la façon dont le cerveau suit les variations d’intensité sonore au fil du temps. Ils ont transformé l’audio en plusieurs descriptions mathématiques de la « sonie temporelle » et ont ensuite examiné où et quand les réponses cérébrales s’alignaient sur ces patterns d’intensité. Pour les auditeurs anglais comme russes, le cerveau a montré des schémas temporels similaires, en accord avec ce qui a été rapporté dans des travaux antérieurs. Cet accord entre les langues et avec des études passées est un indicateur fort que les enregistrements sont propres, fiables et prêts à être exploités par d’autres.
Pourquoi cela compte pour la recherche future sur le cerveau et le langage
Pour le grand public, l’enseignement principal est que ce jeu de données constitue une nouvelle ressource commune permettant à de nombreuses équipes de recherche d’étudier comment la parole spontanée et réelle est traitée par le cerveau. Parce qu’il est ouvert, bien annoté et enregistré en deux langues différentes, il peut soutenir des projets allant des questions fondamentales sur la compréhension des conversations, aux comparaisons entre langues, jusqu’à des efforts ambitieux visant à décoder la parole directement à partir de l’activité cérébrale. En bref, le jeu de données linguistiques Kymata Soto vise moins à répondre à une question unique qu’à offrir à la communauté scientifique une base partagée et de haute qualité pour explorer la manière dont nos cerveaux donnent sens aux conversations qui remplissent notre vie quotidienne.
Citation: Yang, C., Parish, O., Klimovich-Gray, A. et al. Kymata Soto Language Dataset: an electro-magnetoencephalographic dataset for natural speech processing. Sci Data 13, 254 (2026). https://doi.org/10.1038/s41597-026-06579-8
Mots-clés: cerveau et langage, perception de la parole, EEG MEG, conversation naturaliste, données de neuroimagerie ouvertes