Clear Sky Science · fr
SEA CDM : Modèle de données commun Study–Experiment–Assay et bases de données pour l’intégration et l’analyse inter-domaines
Pourquoi l’organisation des données de laboratoire nous concerne tous
La médecine moderne repose sur des montagnes de données expérimentales — des essais vaccinaux et études d’infection jusqu’à la génomique du cancer. Pourtant, ces données sont souvent enfermées dans des formats incompatibles, ce qui complique la combinaison des résultats et l’identification de motifs importants, par exemple qui répond le mieux à un vaccin ou pourquoi certaines personnes présentent davantage d’effets indésirables. Cet article décrit une nouvelle manière d’organiser et de relier des expériences biomédicales diverses afin que les chercheurs puissent poser des questions plus riches et obtenir des réponses plus rapides et plus fiables qui finiront par influencer la prévention et le traitement des maladies.
Un langage commun pour les expériences
Différents groupes de recherche et bases de données ont tendance à décrire leurs études à leur façon, même lorsqu’ils réalisent des travaux très voisins. Une base peut se concentrer sur les essais vaccinaux, une autre sur l’activité génique dans des cellules individuelles, et une troisième sur les résultats cliniques, chacune employant des étiquettes et des structures différentes. Le Study–Experiment–Assay Common Data Model, ou SEA CDM, propose une « grammaire » simple et partagée pour tous ces efforts. Il découpe tout projet biomédical en trois étapes liées : l’étude globale qui pose une question, les expériences menées sur des personnes ou des animaux, et les essais — comme des tests sanguins ou des mesures d’expression génique — qui produisent des résultats. Autour de ces étapes, le modèle standardise aussi des éléments clés tels que qui ou quoi a été étudié, quels échantillons ont été prélevés, quels traitements ont été appliqués et quelles analyses ont été réalisées. 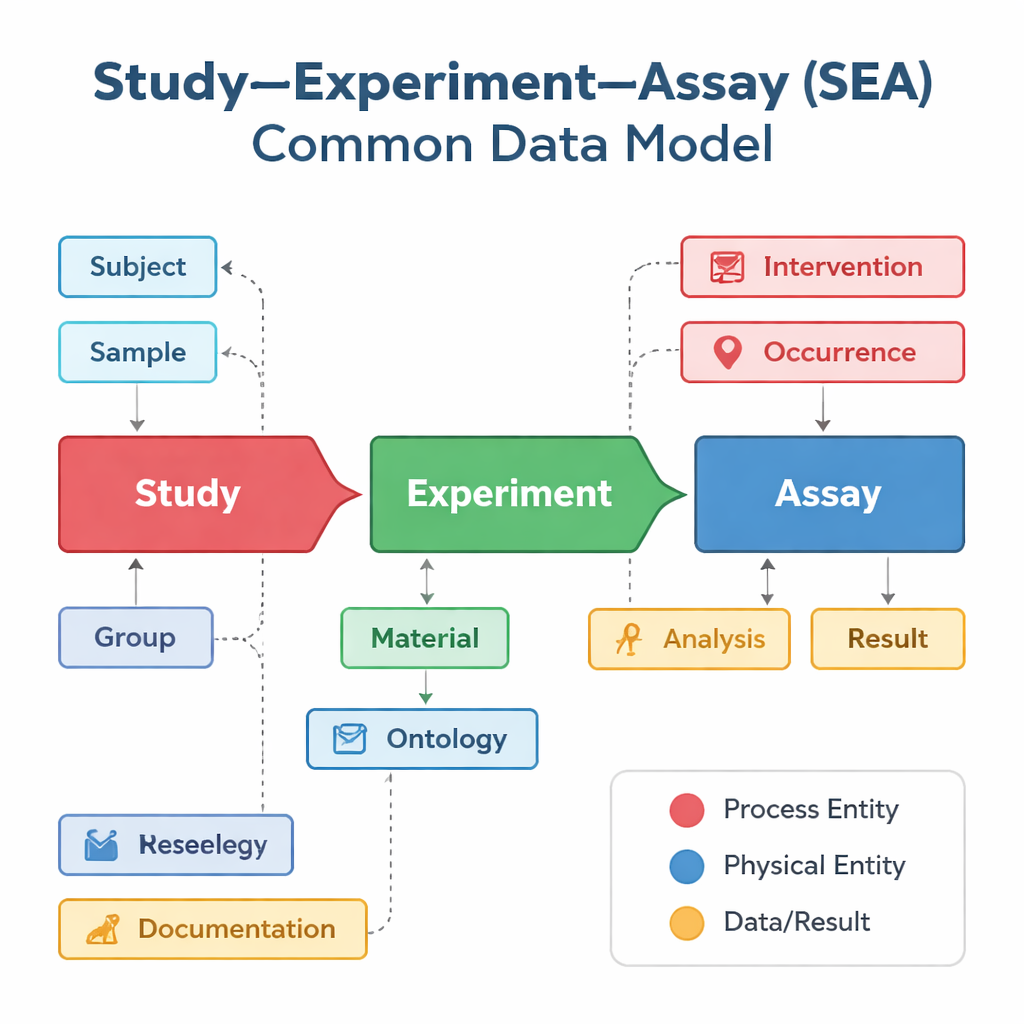
Ontologies : transformer des étiquettes en connaissances
Aligner simplement les en-têtes de colonnes ne suffit pas ; un même concept peut être nommé différemment selon les sources. SEA CDM s’appuie sur des vocabulaires curatés, appelés ontologies, pour s’assurer que « vaccin contre la grippe », « vaccin inactivé trivalent contre la grippe » et un nom de marque comme « Fluzone » sont reconnus comme des idées apparentées. Ces ontologies sont structurées comme des arbres de parenté de termes médicaux et biologiques. Parce que SEA CDM associe un identifiant officiel d’une ontologie à chaque variable — par exemple une maladie, un type cellulaire ou un vaccin — les ordinateurs peuvent suivre automatiquement ces arbres, retrouver tous les enregistrements pertinents et même inférer des relations. Par exemple, une requête simple peut extraire toutes les études ayant utilisé n’importe quel vaccin grippal trivalent parmi des centaines de produits nommés, permettant des recherches sémantiques puissantes bien au-delà d’une simple recherche par mots-clés. 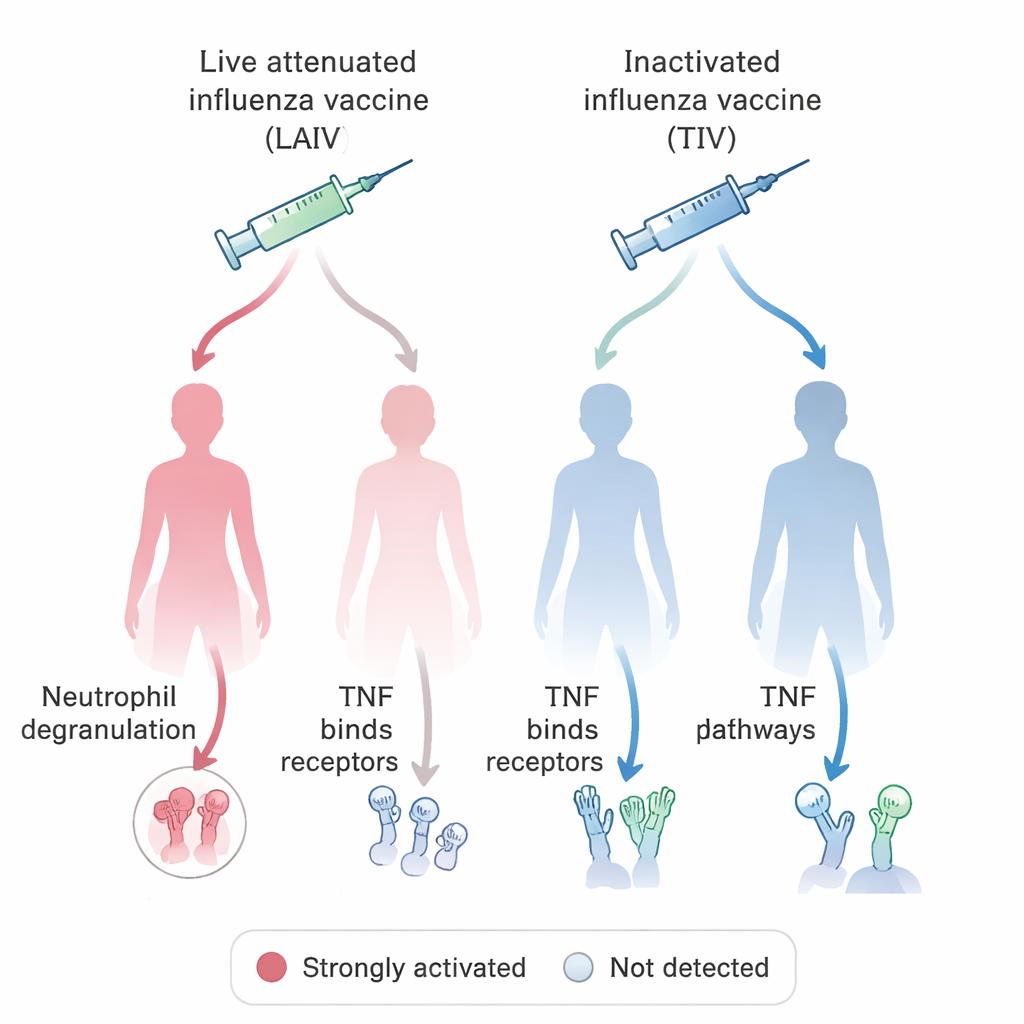
De fichiers éparpillés à des bases de données connectées
Pour tester leur modèle dans le monde réel, les auteurs ont construit une famille de bases de données et d’outils sous le nom générique OSEAN. Ils ont converti trois grandes ressources publiques au format SEA CDM : ImmPort, qui héberge des métadonnées d’études sur la réponse immunitaire ; VIGET, qui relie des études vaccinaux à des données d’activité génique ; et CELLxGENE, qui se concentre sur les mesures en cellule unique. À l’aide de pipelines personnalisés, ils ont traduit des dizaines de tables et de formats de fichiers originaux en un ensemble cohérent de tables SEA CDM ou de nœuds de graphe. Cela leur a permis de stocker plus d’un millier d’études liées à l’immunité, plus de deux millions d’échantillons, et de nombreuses descriptions de vaccins, de maladies et de méthodes de laboratoire dans un cadre cohérent pouvant être interrogé avec le même logiciel.
Ce que des données unifiées peuvent révéler sur les vaccins et les différences selon le sexe
Avec ce système unifié en place, l’équipe a posé une question biologique d’intérêt médical direct : comment différents vaccins contre la grippe stimulent-ils le système immunitaire chez les femmes et les hommes ? En interrogeant la base OSEAN basée sur VIGET et en appliquant des règles simples pour définir un gène « stimulé », ils ont identifié des centaines de gènes dont l’activité augmentait après vaccination par des vaccins antigrippaux vivants atténués (contenant un virus affaibli) ou par des vaccins inactivés, « tués ». Ils ont ensuite comparé les voies auxquelles participent ces gènes, en séparant les données par sexe. Un motif frappant concernait les neutrophiles, un type de globule blanc qui attaque les microbes en libérant des granules toxiques, et la signalisation via le TNF, une molécule inflammatoire clé. Dans la plupart des groupes, la vaccination contre la grippe était associée à des signes de dégranulation des neutrophiles, mais cette signature était absente chez les femmes ayant reçu le vaccin vivant atténué. En revanche, la signalisation liée au TNF était particulièrement marquée chez ces femmes mais pas dans les groupes masculins parallèles. Ces résultats font écho à des études animales suggérant que le comportement des neutrophiles et les réponses vaccinales peuvent différer systématiquement entre mâles et femelles.
Construire un écosystème pour de futures découvertes
Les auteurs soutiennent que la véritable puissance du SEA CDM réside dans le fait de rendre les données biomédicales plus FAIR — trouvables, accessibles, interopérables et réutilisables. En donnant aux expériences une structure partagée et en ancrant chaque étiquette importante à un terme d’ontologie bien défini, leur système facilite grandement la combinaison de données provenant de sources différentes, le traçage du traitement des échantillons et la reproduction des analyses. L’étude de cas sur la grippe montre que même des requêtes relativement simples, exécutées sur une base harmonisée, peuvent dévoiler des motifs subtils et spécifiques au sexe dans la réponse vaccinale qui pourraient influencer les doses ou le choix du vaccin. À mesure que davantage de ressources adoptent ce modèle commun et les outils associés, les chercheurs seront mieux équipés pour relier des indices à travers maladies, technologies et populations, transformant des jeux de données fragmentés en un véritable écosystème biodonnées intégratif.
Citation: Huffman, A., Yeh, FY., Hur, J. et al. SEA CDM: Study-Experiment-Assay Common Data Model and Databases for Cross-Domain Data Integration and Analysis. Sci Data 13, 238 (2026). https://doi.org/10.1038/s41597-026-06558-z
Mots-clés: intégration de données, ontologie biomédicale, réponse vaccinale, différences liées au sexe, graphe de connaissances