Clear Sky Science · fr
Programmes universitaires en science des données dans la région du Midwest des États-Unis avant l’ère ChatGPT : un jeu de données sélectionné
Pourquoi cela compte pour les étudiants et les communautés
Aux États-Unis, de nouveaux diplômes axés sur les données semblent apparaître chaque semestre, mais il peut être difficile de savoir ce que signifient réellement « Science des données », « Analyse des données » ou un programme « interdisciplinaire ». Cet article décrit un jeu de données construit avec soin qui cartographie et organise tous les programmes universitaires liés aux données dans le Midwest américain juste avant que des outils comme ChatGPT ne deviennent répandus, offrant un instantané clair de la manière dont les universités formaient la prochaine génération de professionnels des données.
Un instantané pris avant la vague de l’IA
Les auteurs ont cherché à saisir l’état de l’enseignement de la science des données en 2023, juste avant que l’intelligence artificielle générative ne commence à redessiner l’enseignement et le travail technique. Ils se sont concentrés sur les établissements d’enseignement supérieur de 12 États du Midwest, des collèges communautaires aux grandes universités. Chaque fois qu’un programme contenait le mot « data » dans son intitulé, ils l’ont examiné en détail : où était-il enseigné ? Était-ce une majeure, une mineure, un certificat ? S’adressait-il aux étudiants de premier cycle ou aux étudiants diplômés ? Quels départements en avaient la responsabilité et quelles matières couvrait le cursus ? En figeant ce moment, le jeu de données permet aux chercheurs futurs d’observer comment l’offre éducative évolue à mesure que les outils d’IA se diffusent.
Faire le tri entre les différents types de programmes en données
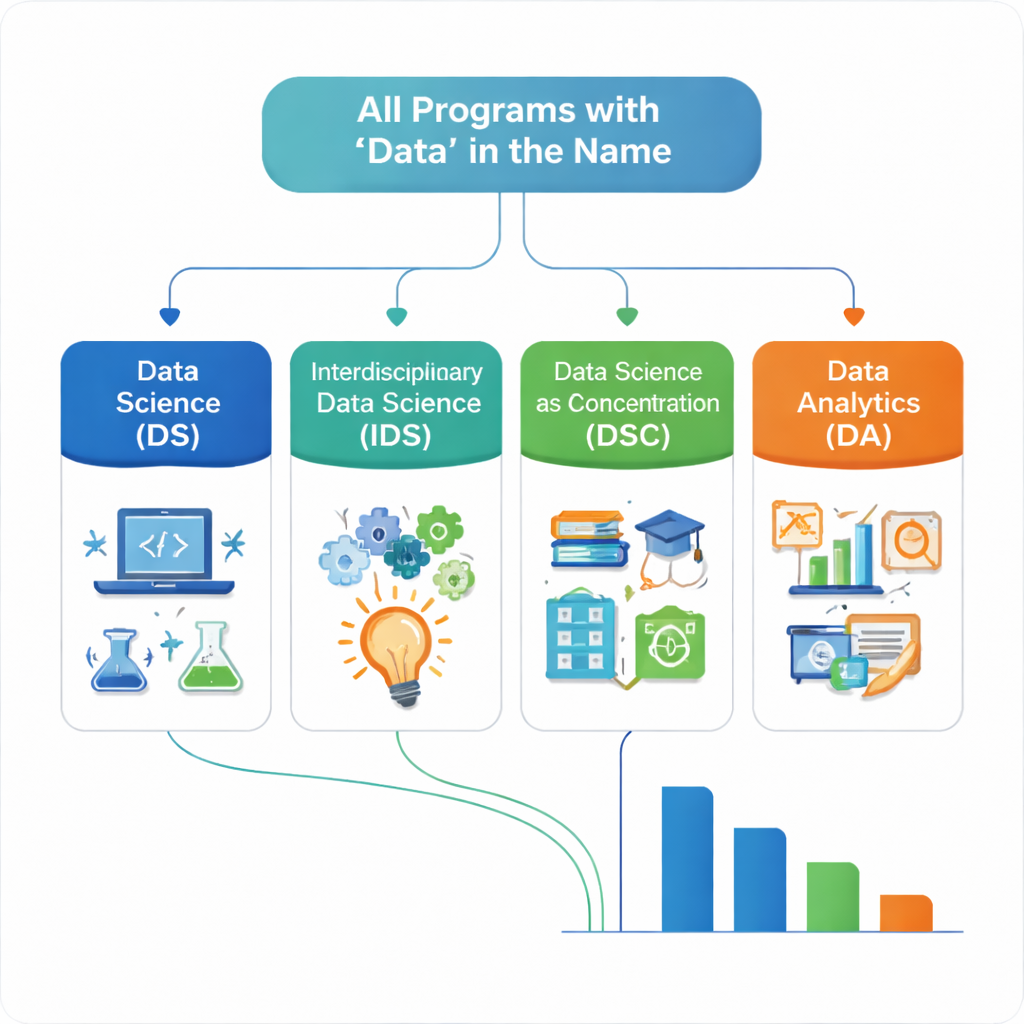
Un des principaux défis auxquels les auteurs ont été confrontés est que « science des données » est utilisé de multiples façons. Deux diplômes aux noms presque identiques peuvent préparer à des carrières très différentes. Pour mettre de l’ordre dans ce chaos, ils ont créé un système de classification reproductible comportant quatre groupes principaux. Un programme classique de Science des données combine des mathématiques, des statistiques et de l’informatique substantielles et est typiquement porté par ces départements. Les programmes interdisciplinaires de Science des données partagent ce noyau technique mais sont soit partiellement pilotés par des départements non techniques, soit exigent que les étudiants prennent une seconde majeure ou une mineure. La Science des données comme concentration décrit les cas où « data » est une spécialisation au sein d’un autre diplôme. Les programmes d’Analyse des données regroupent des offres qui utilisent le mot « data » mais qui n’ont pas le mélange complet de mathématiques et d’informatique, ou qui sont dirigés par des départements hors des domaines quantitatifs principaux.
Comment l’information a été collectée et vérifiée
Pour constituer le jeu de données, l’équipe a d’abord utilisé l’outil de recherche du College Board pour compiler une liste d’établissements du Midwest. Ils ont ensuite visité manuellement le site web de chaque école, recherché les programmes ayant « data » dans le titre et enregistré les détails dans un tableur structuré. Pour chaque programme, ils ont documenté l’État, l’établissement, la ville, le nom du programme, s’il était proposé sur le campus ou en ligne, son niveau et son type, et s’il s’agissait d’une majeure, d’une mineure ou d’un certificat. Ils ont traité majeures et mineures comme des offres potentiellement distinctes et ont porté une attention particulière aux départements officiellement responsables. Lorsque la responsabilité départementale n’était pas claire, ils se sont appuyés sur les listes de cours et les étiquettes de matière pour déduire si le cursus combinait réellement mathématiques et informatique. Après le travail manuel, ils ont utilisé du code Python pour nettoyer les données, supprimer les doublons, imposer des catégories cohérentes et signaler les contradictions ou les informations manquantes.
Ce que le jeu de données révèle sur le Midwest
La collection finale comprend 404 programmes uniques issus de 225 systèmes scolaires. Plus de la moitié sont classés comme Science des données, ce qui suggère que de nombreuses institutions du Midwest ont adopté le modèle plus technique axé sur les mathématiques et l’informatique. Environ un tiers relèvent de l’Analyse des données, souvent rattachée à des unités commerciales, d’information ou technologiques, et mettant généralement moins l’accent sur la combinaison mathématiques–informatique. Les programmes interdisciplinaires de Science des données et la Science des données comme concentration constituent des portions plus petites mais importantes, reflétant des efforts pour mêler compétences en données et domaines comme le commerce, l’ingénierie ou les sciences sociales. Les auteurs regroupent également les établissements par type — collèges communautaires, écoles techniques et d’ingénierie, universités et autres collèges — et montrent que les universités dominent en nombre d’offres, tandis que les collèges communautaires et les écoles techniques privilégient davantage les programmes d’Analyse des données.
Comment d’autres peuvent utiliser cette ressource
Le jeu de données, disponible publiquement via Harvard Dataverse ainsi que le code utilisé pour le traiter et le valider, est conçu pour être réutilisé. Les décideurs peuvent examiner la répartition des programmes liés aux données selon les États et les types d’établissements pour orienter les investissements dans le développement des compétences professionnelles. Les directeurs de départements et les concepteurs de cursus peuvent comparer leurs propres programmes à ceux des établissements voisins ou de même type. Les chercheurs en éducation peuvent suivre l’évolution des intitulés, des structures et de la gouvernance des programmes au fil du temps, en particulier à mesure que les outils d’IA s’intègrent aux salles de classe et aux lieux de travail. Les enseignants peuvent même utiliser les données dans des projets de cours, permettant aux étudiants d’explorer le paysage éducatif réel qu’ils s’apprêtent à rejoindre.
Ce que ce travail nous dit, en termes simples
Au fond, cet article offre une carte bien organisée de la manière dont les établissements du Midwest enseignaient les compétences en données juste avant le boom de l’IA générative. En distinguant clairement les différents types de programmes « data » et en documentant qui les dirige et ce qu’ils exigent, les auteurs fournissent une référence permettant de comprendre comment l’éducation suit le rythme du changement technologique rapide. Dans quelques années, cet instantané aidera à montrer si les programmes sont devenus plus techniques, plus interdisciplinaires ou plus façonnés par l’IA — et guidera les établissements et les communautés dans leurs décisions pour mieux préparer les étudiants à un monde axé sur les données.
Citation: Blackford, D., Maria Selvitella, A. Data science academic programs in the pre-ChatGPT erain the Midwestern United States: a curated dataset. Sci Data 13, 236 (2026). https://doi.org/10.1038/s41597-026-06553-4
Mots-clés: enseignement de la science des données, programmes universitaires, universités du Midwest, diplômes en analyse de données, jeu de données sur l’enseignement supérieur